决策树
由于研究需要,最近在看一些paper,很多都提到了随机森林的方法,所以查阅了相关资料去学习,现在了解了它的原理,基于自己的理解写了这篇博客,希望对初学者有点帮助。
决策树是机器学习中常见的分类方法,一颗决策树由根节点、内部节点(决策节点)和叶节点组成。其中,根节点和内部节点都对应着需要分类的属性,而叶节点是分类中类标签的集合,即对应着决策结果。决策树学习的目的是为了产生一颗泛化能力强的树。其基本流程遵循“分而治之”的策略。如下图:

def CreatTree(dataset, featureLabels):
#递归终止条件1:所有数据集中的类别相同
classList=[data[-1] for data in dataset]
if classList.count(classList[0])==len(classList):
#如果某一个类别的个数等于类别集合的总长度,即数据集中的类别相同
return classList[0]
#递归终止条件2:使用完了所有特征
if len(featureLabels)==1:
return MajorClass(classList)
#找到最好的数据集划分方式
bestFeature=BestFeature(dataset)#特征的下标
bestFeatureLabel=featureLabels[bestFeature]#特征的名称
myTree={bestFeatureLabel:{}}
del(featureLabels[bestFeature])
bestFeatureValue=[data[bestFeature] for data in dataset]#该特征对应的不同值
uniqueFeaVal=set(bestFeatureValue)
for value in uniqueFeaVal:
subFeatureLabels=featureLabels[:]#函数参数为列表时,参数是按照引用方式传递,为了防止下一步调用时改变原始列表的内容
myTree[bestFeatureLabel][value]=CreatTree(SplitData(dataset,bestFeature,value),\
subFeatureLabels)
return myTree决策树最重要的是划分属性和剪枝处理,因为后面随机森林对决策树的作用与剪枝处理一样(防止过拟合),所以我们重点讲一下划分属性。这里需要理解两个概念,信息增益和基尼指数。决策树的划分一般是使用它们来选择划分属性。
信息增益
信息增益用到了信息论中的熵的概念,“信息熵”是度量样本集合纯度中最常见的一种指标。
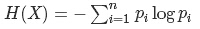
而信息增益:
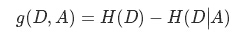
其中公式后一项为条件熵:
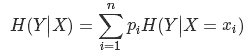
一般来说,信息增益越大,则说明使用属性A来进行划分所得的“纯度提升”也就越大。因此,我们可以用它来进行决策树的划分属性选择。
根据信息增益的公式,分类系统中某个特征A的信息增益就是:Gain(D, A) = H(C)-H(C|A),经过对信息增益计算后得到一个特征作为决策树的根节点,该特征有几个取值,根节点就会有几个分支,每一个分支都会产生一个新的数据子集,余下的递归过程就是对每个
再重复上述过程,直至子数据集都属于同一类。最后得到一颗未剪枝的决策树。
注意:
决策树的递归终止条件:1.数据集中所有样本属于同一类;2.当特征集为空集(即没有特征作为划分依据)或者训练样本在该特征处的样本属于同一类。
#decision_tree.py
from math import log
import operator
#计算熵
def CalEnt(dataset):
size=len(dataset)
Labels={}
for data in dataset:
lab=data[-1];
if lab not in Labels.keys():
Labels[lab]=1;
else:
Labels[lab]+=1;
entropy=0.0
for key in Labels:
prob=float(Labels[key])/size
entropy-=prob*log(prob,2)
return entropy
#按照给定特征划分数据集,并返回不包含给定特征值的新数据集
def SplitData(dataset,index,value):
retset=[]
for data in dataset:
if data[index]==value:
temp=data[:index]
temp.extend(data[index+1:])
retset.append(temp)
return retset
#选择最好的数据集划分方式--即信息增益最大的特征
def BestFeature(dataset):
featureSize=len(dataset[0])-1
baseEnt=CalEnt(dataset)
bestGain=0.0
bestFeature=-1
for i in range(featureSize):
feaset=[data[i] for data in dataset]
feakind=set(feaset)
nowEnt=0.0
for fea in feakind:
subset=SplitData(dataset,i,fea)
prob=float(len(subset))/len(dataset)
nowEnt+=prob*CalEnt(subset)
gain=baseEnt-nowEnt
if gain>bestGain:
bestGain=gain
bestFeature=i
return bestFeature #返回的是特征的下标
#若属性遍历完得到的数据集仍有多个类别,取数目最多的类别作为该数据集类别
def MajorClass(classList):
classCount={}
for item in classList:
if item not in classCount.keys():
classCount[item]=0
classCount[item]+=1
return max(classCount) #比书上得到最大值的方法简单
#创建树
def CreatTree(dataset, featureLabels):
#递归终止条件1:所有数据集中的类别相同
classList=[data[-1] for data in dataset]
if classList.count(classList[0])==len(classList):
return classList[0]
#递归终止条件2:使用完了所有特征
if len(featureLabels)==1:
return MajorClass(classList)
#找到最好的数据集划分方式
bestFeature=BestFeature(dataset)#特征的下标
bestFeatureLabel=featureLabels[bestFeature]#特征的名称
myTree={bestFeatureLabel:{}}
del(featureLabels[bestFeature])
bestFeatureValue=[data[bestFeature] for data in dataset]#该特征对应的不同值
uniqueFeaVal=set(bestFeatureValue)
for value in uniqueFeaVal:
subFeatureLabels=featureLabels[:]#函数参数为列表时,参数是按照引用方式传递,
#为了防止下一步调用时改变原始列表的内容
myTree[bestFeatureLabel][value]=CreatTree(SplitData(dataset,bestFeature,value),\
subFeatureLabels)
return myTree
#测试算法--遍历整棵树,比较test的值和节点数的值
def Classify(myTree,featureLabels,test):
firstFea=list(myTree.keys())[0]#先和树根比
secondDict=myTree[firstFea]#树根特征的取值
feaIndex=featureLabels.index(firstFea)#树根特征在featureLabels的下标
for key in secondDict.keys():
if(test[feaIndex]==key):
if type(secondDict[key]).__name__=='dict':
Classify(secondDict[key],featureLabels,test)
else:
classLabel=secondDict[key]
return classLabel
#存储决策树
def StoreTree(myTree,filename):
import pickle
fw=open(filename,'w')
pickle.dump(mytree,filename)
f.close()
#取出决策树
def getTree(filename):
import pickle
fr=open(filename)
return pickle.load(f)
if __name__=='__main__':
#使用决策树预测眼镜类型
import decision_tree
fr=open('G:\\程序\\python\\2.决策树\\lenses.txt')
lenses=[line.strip().split('\t') for line in fr.readlines()]
lensesLabels=['age','prescript','astigmatic','tearRate']
lensesTree=decision_tree.CreatTree(lenses,lensesLabels)
print(lensesTree)
代码引用参考博客:https://blog.csdn.net/xtnc1028/article/details/46351307
随机森林
随机森林是一种重要的基于Bagging的集成学习方法,可以用来做分类、回归等问题。它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。
在建立每一棵决策树的过程中,有两点需要注意采样与完全分裂。首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)一般m=logM+1取下整。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。一般很多的决策树算法都一个重要的步骤——剪枝,但是随机森林不需要剪枝,因为之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
随机森林的优缺点:
优点:1.比较适合做多分类问题,训练和预测速度快,在数据集上的表现好。2.对训练数据的容错能力强,是一种有效地估计缺失数据的一种方法。3.能够处理很高维的数据,并且不需要单独做特征选择,能够在训练过程中检测到属性之间的相互影响程度以及某一属性的重要性程度,具有实现过程简单方便,且能够并行分类的能力(相对于Boosting系列的Adaboost和GBDT)。
缺点:1.被证明在某些噪音较大的分类问题上仍会出现过拟合的现象。2.取值划分比较多的特征容易对RF的决策产生很大的影响,从而影响到模型的效果。