标题
-
应用范围和场景
在自然语言处理的应用中,经常会用到分词,词性分析、句法分析、英体识别等应用,斯坦福NLP在中文支持方面还算不错,方便我们更快的支持和验证应用的可行性。 -
环境配值和搭建过程
下载 stanford-corenlp-full-2017-06-09.zip ,然后在系统中解压,下载该包支持的中文模型 stanford-chinese-corenlp-2017-06-09-models.jar , 注意名称需要对应,不然容易出bug。将模型的解压文件放到第一文包的解压文件中,如下图:
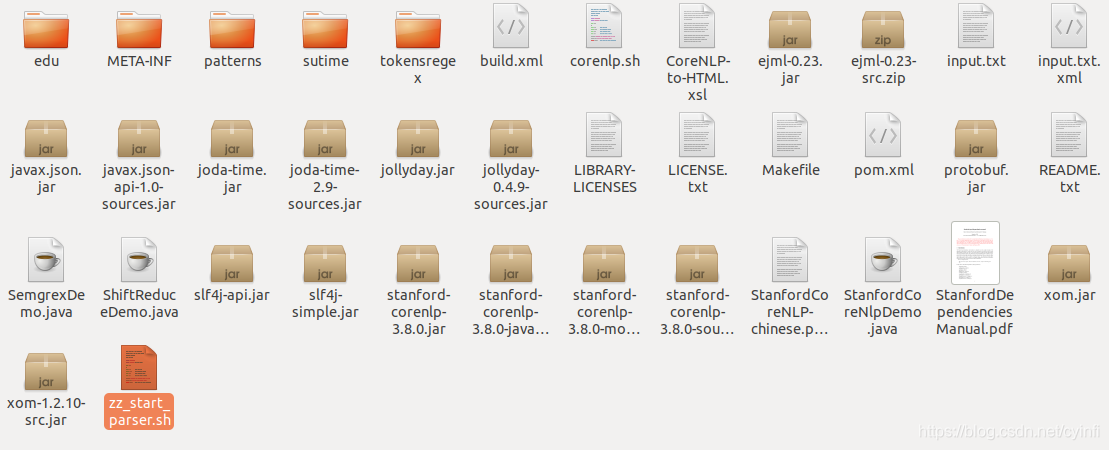
新建启动脚本如上图:注意指定中文的模型文件就可以了。

-
启动效果
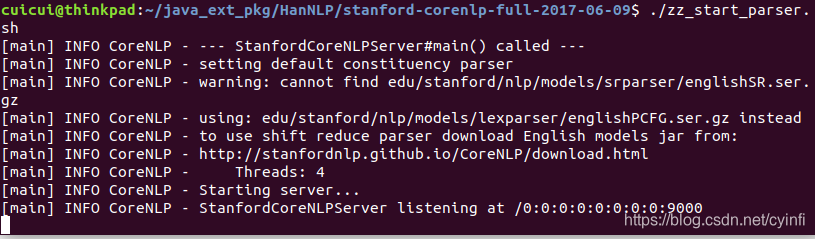

-
语言支持
在这里开个头,共朋友们参考使用。
class service_ana(object):
"""
对斯坦福服务的包装a
"""
def __init__(self):
pass
#需要提前启动服务
self.nlp = StanfordCoreNLP('http://localhost:9000')
def get_res(self, text):
"""参数是多个句子的列表(分词和不分词都行), 返回各个句子的分析结果"""
output = self.nlp.annotate(text, properties={
'annotators': 'tokenize,ssplit,pos,ner,depparse,parse',
'outputFormat': 'json'
})
print(output['sentences'][0]['parse'])
print(output['sentences'][0]['basicDependencies'])
print(output['sentences'][0]['enhancedDependencies'])
print(output['sentences'][0]['enhancedPlusPlusDependencies'])
print(output['sentences'][0]['tokens'])
- 结果分析和抽取:
{“intent_res”: “你喜欢苹果嘛”, “zhu_yu”: “你”, “bin_yu”: “苹果”, “wei_yu”: “喜欢”, “intent_index”: “你喜欢 喜欢苹果 嘛喜欢”}
**tips:**通过这种分析句子成分的方法分析意图适合场景相对集中并且比较精细的意图,比较粗的意图可以使用分类来实现,另外,涉及到句法解析,长句子也不太适合,速度较慢。