storn是实时流式计算,Hadoop是做离线的数据分析
Storm简介
Storm是 Twitter开源的一个分布式的实时计算系统,可以简单、可靠的处理大量的数据流;
用于数据的实时分析,持续计算,分布式RPC等等;
Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快(在一个小集群中,每个结点每秒可以处理数以百万计的消息)。Storm的部署和运维都很便捷,而且更为重要的是可以使用任意编程询言来开发应用。
Storm实时计算应用场景
1.实时推荐系统;2.实时告警系统;3.股票系统;4.实时分析,在线机器学习,持续计算,分布式RPC,ETL等等
Storm实时计算系统特点
低延迟:都说了是实时计算系统了,延迟是一定要低的。
高性能:可以使用几台普通的服务器建立环境,结余成本
分布式:Stom非常适合于分布式场景,大数据的实时计算
可扩展:伴随着业务的发展,我们的数据量、计算量可能会越来越大,所以希望这个系统是可扩展的。
容错:这是分布式系统中通用问题,一个节点挂了不能影响我的应用,Storm可以轻松做到在节点挂了的时候实现任务转移
可靠性:可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
快速:系统的设计保证了消息能得到快速的处理,使用 ZeroMQ作为其底层消息队列。
本地模式:Storm有一个“本地模式”,可以在处理过程中完全模拟stom集群。这让你可以快速进行开发和单元测试
Storm体系结构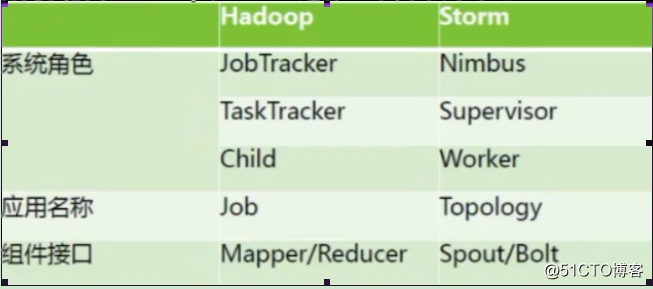
Nimbus主节点:
主节点通常运行一个后台程序—Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这个很类似亍 Hadoop中的 Job Tracker.
Supervisor工作节点:
工作节点同样会运行一个后台程序—supervisor,用于收听工作指派并基于要求运行工作进程。每个工作节点都是 topology中一个子集的实现。而Nimbus和 Supervisor之间的协调则通过 Zookeeper系统戒者集群。
Zookeeper
Zookeeper是完成 Supervisor和 Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装到stom中的“topology”.topology则是一组由 Spouts(数据源)和Bots(数据操作)通过 Stream Groupings运行连接的图。下面对出现的术语进行更深刻的解析。
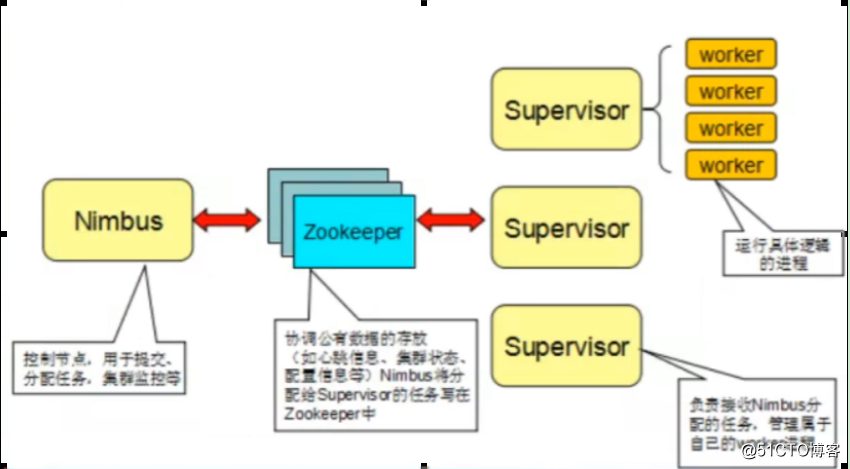
Topology(拓扑)
storm中运行的一个实时应用程序,因为各个组件间的消息流动形成逻辑上的一个拓扑结构。一个 topology是 spouts和bos组成的图,通过 stream groupings将图中的 spouts和bots连接起来
Storm demo
首先编写我们的数据源类:Spout。可以使用俩种方式:
继承 BaseRichSpout类
实现 IRichSpout接口
重点需要几个方法进行重写或实现:open、nextTuple、declareOutputFields
继续编写我们的数据处理类:Bolt。可以使用俩种方式:
继承 BaseBasicBolt类
实现 IRichBolt接口
重点需要几个方法进行重写或实现:execute、declareOutputFields
最后我们编写主函数(Topology)去进行提交一个任务。
在使用 Topology的时候,Storm框架为我们提供了俩种模式:本地模式和集群模式
本地模式:(无需stom集群,直接在jaa中即可运行,一般用于测试和开发阶段)执行运行main函数即可。
集群模式:(需要Stom集群,把实现的java程序打包,然后 Topology进行提交)需要把应用打成jar,使用stom命令把 Topology提交到集群中去
提交topology命令:storm jar storm01.jar bhz.topology.PWTopology1
查看任务命令:storm list
Storm APl
Topology(拓扑)
Stream grouping(流分组、数据的分发方式)
Spout(喷口、消息源)
Bolt(螺栓、处理器)
Worker(工作进程)
Executor(执行器、Task的线程)
Task(具体的执行任务)
Configuration(配置)
Storm拓扑配置
工作进程、并行度、任务数设置:
我们首先设置了2个工作进程(也就是2个jvm)
然后我们设置了 spout的并行度为2(产生2个执行器和2个任务)
第一个bolt的并行度为2并且指定任务数为4(产生2个执行器和4个任务)
第二个bolt的并行度为6(产生6个执行器和6个任务)
因此:该拓扑程序共有俩个工作进程(worker),2+2+6=10个执行器
(executor),2+4+6=12个任务(task)。每个工作进程可以领取到12/2=6个任务。默认情况下一个执行器执行一个任务,但如果指定了任务的数目。则任务会平均分配到执行器中。
什么是Storm拓扑?
我们在使用storm进行流式计算的时候,都必须要在Main函数里面建立所谓的“拓扑”,拓扑是什么?
拓扑是一个有向图的计算。(也就是说在计算的过程中是有流向的去处理业务逻辑,节点之间的连接显示数据该如何进入下一个节点,他们是进行连接传递的)
拓扑运行很简单,只需要使用 storm命令,把一个jar提交给 nimbus节点,numbus就会把任务分配给具体的子节点(supervisor)去工作。
我们创建拓扑非常简单:
第一,构建 TopologyBuilder对象
第二,设置 Spout(喷口)数据源对象(可以设置多个)
第三,设置Bolt(螺栓)数据处理对象(可以设置多个)
第四,构建 Config对象
第五,提交拓扑
Storm流分组
Stream Grouping:为每个bolt指定应该接受哪个流作为输入,流分组定义了如何在bolt的任务直接进行分发。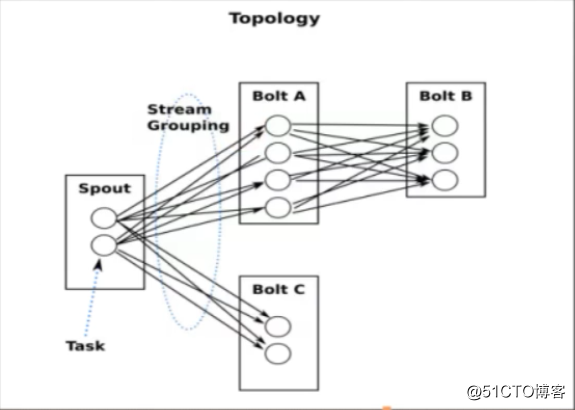
Shuffle Grouping随机分组:保证每个bot接收到的 tuple数目相同Fields Grouping按字段分组:比如按 userid来分组,具有同样 userid的 tuple会被分到相同的Bots,而不同的 userid则会被分配到不同的Bolts。All Grouping广播发送:对于每一个 tuple,所有的Bots都会收到。Global Grouping:全局分组:这个 tuple被分配到stom中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task。Non Grouping无分组:假设你不关心流式如何分组的煤科院使用这种方式,目前这种分组和随机分组是一样的效果,不同的是Stom会把这个Bolt放到Bolt的订阅者的同一个线程中执行。
Direct Grouping直接分组:这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明为 Direct stream的消息流可以声明这种分组方法而且这种消息tupe必须使用 emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的 taskid(Outputcollector.emit,方法也会返回 taskid)
本地分组:如果目标bo在同一工作进程存在一个或多个任务,元祖会随机分配给执行任务,否则该分组方式与随机分组方式是一样的。
Storm Spout的可靠性
Spout是 Storm数据流的入口,在设计拓扑时,一件很重要的事情就是需要考虑消息的可靠性,如果消息不能被处理而丢失是很严重的问题。
我们继续作实验,以一个传递消息并且实时处理的例子,来说明这个问题。
collector.ack(input);//标记成功,重写ack方法
collector.fail(input);//标记失败,重写fail方法
通过示例我们知道,如果在第一个bolt处理的时候出现异常,我们可以让整个数据进行重发,但是如果在第二个bolt处理的时候出现了异常,那么我们也会让对应的整个spout里的数据重发,这样就会出现事务的问题,我们就需要进行判断或者是进行记录
如果是数据入库的话,可以与原ID进行比对。
将一批数据定义唯一的ID入库(幂等性判断事物)
如果是事务的话在编写代码时,尽量就不要进行拆分 tuple
或者使用 storm的 Trident框架
下图是 spout处理可靠性的示意图:当 spout发送一个消息时,分配给俩个bolt分别处理,那么在最后一个bolt接受的时候会做异或运算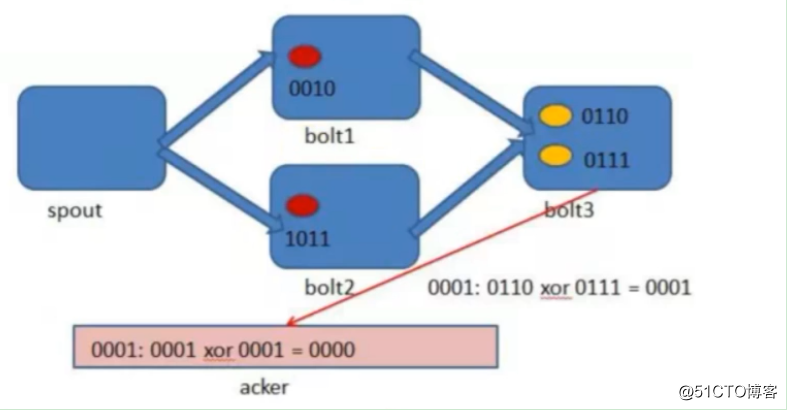
RPC介绍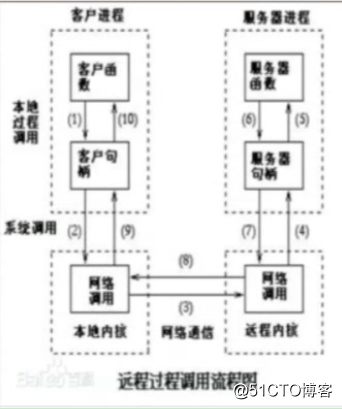
调用客户端句柄;执行传送参数
调用本地系统内核发送网络
消息消息传送到远程主机
服务器句柄得到消息并取得参数
执行远程过程
执行的过程将结果返回服务器句柄
服务器句柄返回结果,调用远程系统内核
消息传回本地主机
客户句柄由内核接收消息
客户接收句柄返回的数据
Storm DRPC
分布式RPC(distributed RPC,DRPC)
Storm里面引入DRPC主要是利用 storm的实时计算能力来并行化CPU密集型(CPU intensive)的计算任务。DRPC的 storm topology以函数的参数流作为输入,而把这些函数调用的返回值作为 topology的输出流。
DRPc其实不能算是 storm本身的一个特性,它是通过组合stom的原语stream、spout、bolt、topology而成的一种模式(pattern)。本来应该把DRPC单独打成一个包的,但是DRPC实在是太有用了,所以我们把它和storm捆绑在一起。
Distributed RPC是通过一个”DRPC Server”来实现
DRPC Server的整体工作过程如下:
1接收一个RPC请求
2)发送请求到 storm topology
3)从 storm topology接收结果。
4)把结果发回给等待的客户端。
Storm Trident介绍
Trident是在stom基础上,一个以实时计算为目标的高度抽象。它在提供处理大吞吐量数据能力(每秒百万次消息)的同时,也提供了低延时分布式查询和有状态流式处理的能力。如果你对Pig和 Cascading这种高级批处理工具很了解的话,那么应该很容易理解 Trident,因为他们之间很多的概念和思想都是类似的。Trident提供了 joins,aggregations,grouping,functions,以及 filters等能力。除此之外,Trident还提供了一些与门的原语,从而在基于数据库戒者其他存储的前提下来应付有状态的递增式处理。Trident也提供致性(consistent)、有且仅有一次(exactly-once)等语义,这使得我们在使用 trident toplogy时变得容易。
我们首先熟悉下 Trident的概念:
"Stream"是 Trident中的核心数据模型,它被当做一系列的 batch来处理。在Storm集群的节点之间,一个 stream被划分成很多 partition(分区),对流的操作(operation)是在每个 partition上并行执行的。
state Query、partition Persist.、poe(filter、partitionAggregate、
对每个 partition的局部操作包括:function
新建 maven工程(storm05)
Storm Trident Function
Storm Trident Filter
Storm Trident projection
Storm Trident operation
Storm Trident aggregate
Batch和 Spout与 Transactiona
Trident提供了下面的语义来实现有且有一次被处理的目标
1、Tuples是被分成小的集合(一组 tuple被称为一个 batch)被批量处理的。
2、每一批 tuples被给定一个唯1D作为事务ID(txid),当这一个 batch被重发时,tid不变。
3、batch和 batch之间的状态更新时严格顺序的。比如说 batch3的状态的更新必须要等到 batch2的状态更新成功之后才可以进行。
有了这些定义,你的状态实现可以检测到当前 batch是否以前处理过,并根据不同的情况进行不同的处理,这个处理取决于你的输入 spout。有三种不同类型的可以容错的 sqout:
1、non-transactional(无事务支持的 spout)
2、transactional(事务支持的 spout)
3、opaque transactional(不透明事务支持的 spout)
transactional spout实现
1、重发操作:
2、重发结果:
opaque transactional spout实现
实现ITridentspout接口
最通用的AP可以支持 transactional or opaque transactional语义
实现IBatchSpou接口:
一个 non-transactional spout
实现IPArtitioned Tridentspout接口:
一个 transactional spout
实现IOpaquePartitioned Tridentspout接口:
一个opaque transactional spout