一、什么是Storm
Storm是Twitter开源的分布式实时大数据处理框架,最早开源于github,从0.9.1版本之后,归于Apache社区,被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等,大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流计算技术中的佼佼者和主流。
二、Storm实时低延迟原因
– storm进程是常驻内存的,不像hadoop里面是不断的启停的,就没有不断启停的开销。
– 第二点,Storm的数据是不经过磁盘的,都是在内存里面,处理完就没有了,处理完就没有了,数据的交换经过网络,这样就避免磁盘IO的开销,所以Storm可以很低的延迟。
三、Storm和Hadoop的区别

– 数据来源:HADOOP是HDFS上某个文件夹下的可能是成TB的数据,STORM是实时新增的某一笔数据
– 处理过程:HADOOP是分MAP阶段到REDUCE阶段,STORM是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT)
– 是否结束:HADOOP最后是要结束的,STORM是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始
– 处理速度:HADOOP是以处理HDFS上大量数据为目的,速度慢,STORM是只要处理新增的某一笔数据即可可以做到很快。
– 适用场景:HADOOP是在要处理一批数据时用的,不讲究时效性,要处理就提交一个JOB,STORM是要处理某一新增数据时用的,要讲时效性
四、Storm架构
Nimbus是调度中心,Supervisor是任务执行的地方。Supervisor上面有若干个Worker,每个Worker都有自己的端口,Worker可以理解为一个进程。另外,每个Worker中还可以运行若干个线程。

五、Storm编程模型
– DAG:有向无环图
– Spout:数据源
– Bolt:数据处理节点

六、Storm流程分类
6.1、实时请求应答服务(同步)
– 实时请求应答服务(同步),往往不是一个很简单的操作,而且大量的操作,用DAG模型来提高请求处理速度
– DRPC
– 实时请求处理
– 例子:发送图片,或者图片地址,进行图片特征的提取

这里DRPC Server的好处是什么呢?这样看起来就像是一个Server,经过Spout,然后经过Bolt,不是更麻烦了吗?DRPC Server其实适用于分布式,可以应用分布式处理这个单个请求,来加速处理的过程。
– 客户端实现
DRPCClient client = new DRPCClient("drpc-host", 3772);
String result =client.execute("reach","http://twitter.com");– 服务端实现
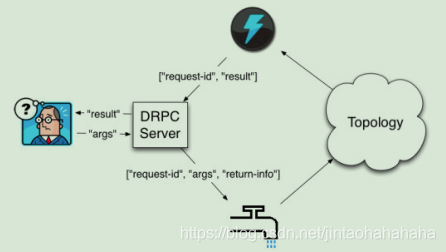
服务端由四部分组成:包括一个DRPC Server, 一个 DPRCSpout,一个Topology和一个ReturnResult。如下图:
6.2、流式处理(异步)
这种处理模式不是说其不快,而是客户端不再等待结果。举例如下:
• 逐条处理
ETL,把关心的数据提取,标准格式入库,它的特点是我把数据给你了,不用再返回给我,这个是异步的。
• 分析统计
日志PV,UV统计,访问热点统计,这类数据之间是有关联的,比如按某些字段做聚合,加和,平均等等。
最后写到Redis,Hbase,MySQL,或者其他的MQ里面去给其他的系统去消费。

– 代码示例

