SiamFC
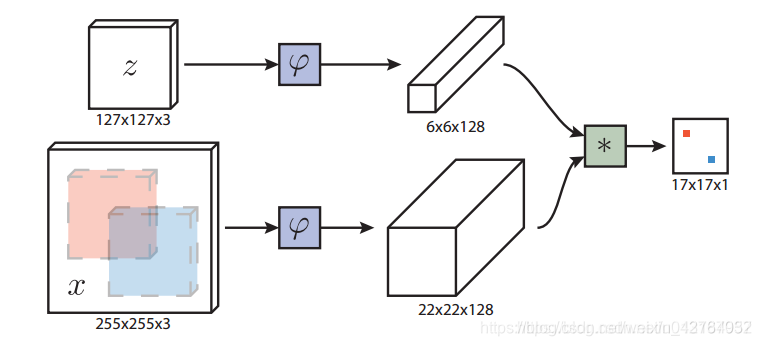
SiamFC的基本结构如下:
即,将目标与待搜索区输入到孪生网络中,分别获得对应feature map,然后做互相关,就是将目标的feature map 作为卷积核,与之作卷积,获得响应图(heatmap)
缺点 :
- 应该找到与模板类似的候选对象,并且应该将正确的对象与所有这些候选对象区分开来。
- 严重遮挡或背景杂乱的物体会导致意想不到的跟踪失败。
所以需要为目标模板找到关键部位,即注意力机制。
Visual Object Tracking by Hierarchical Attention Siamese Network
1. 关键部位搜索:
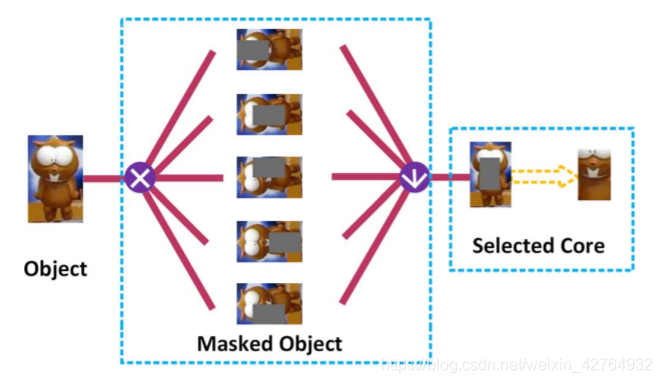
- 设置占目标面积 1 / 4 1/4 1/4的mask, 通过滑窗,生成N个masked object.
- 将原 object 和 masked object 经过简单的特征变换,得到 H O G ( O ) , H O G ( O m a s k ( i ) ) , i = 1 , 2... N HOG(O) , HOG(O_{mask(i)}), i=1,2...N HOG(O),HOG(Omask(i)),i=1,2...N
- 分别计算 H O G ( O ) HOG(O) HOG(O)与N个 H O G ( O m a s k ( i ) ) HOG(O_{mask(i)}) HOG(Omask(i))的内积,选取使得内积值最小的mask, 即该mask包含了object中最重要的特征,记该mask为关键部位。
2. 注意力权值计算
在得到对象的关键部分后,我们用它来计算匹配的注意权重。显然,关键部分位置的权重要高,背景的权重要低。
除此之外,靠近关键部位的区域应该有更多的权重。这是因为在进行相似匹配时,要突出关键部分,建立更多的判别特征,放大其比例。
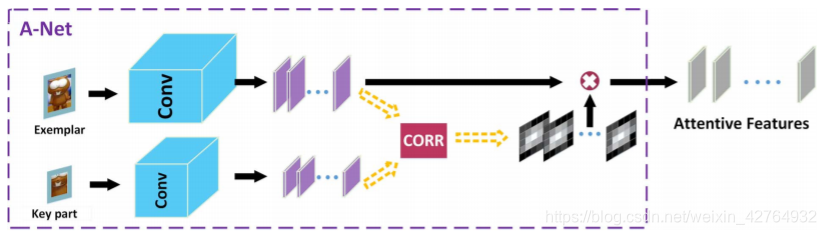
f ( C ) , f ( E ) , a n d f ( S ) f(C),f(E), and f(S) f(C),f(E),andf(S)分别为目标关键部位、目标、待搜索区的输出特征
计算流程
- 将目标与关键部分经过卷积变换后,再进行互相关操作,得到注意权重,即响应图(heatmap)。 c o r r ( f ( C ) , f ( E ) ) corr(f(C),f(E)) corr(f(C),f(E))
- 将权重heatmap与目标相结合,通过增加注意部分的匹配结果,减少不重要部分的匹配结果来提高匹配性能。 c o r r ( f ( C ) , f ( E ) ) ⋅ f ( E ) corr(f(C),f(E)) · f(E) corr(f(C),f(E))⋅f(E)
- 最后,将注意特征输出到搜索区域中进行后续定位
R = c o r r ( c o r r ( f ( C ) , f ( E ) ) ⋅ f ( E ) , f ( S ) ) R = corr(corr(f(C),f(E)) · f(E),f(S)) R=corr(corr(f(C),f(E))⋅f(E),f(S))
整体架构
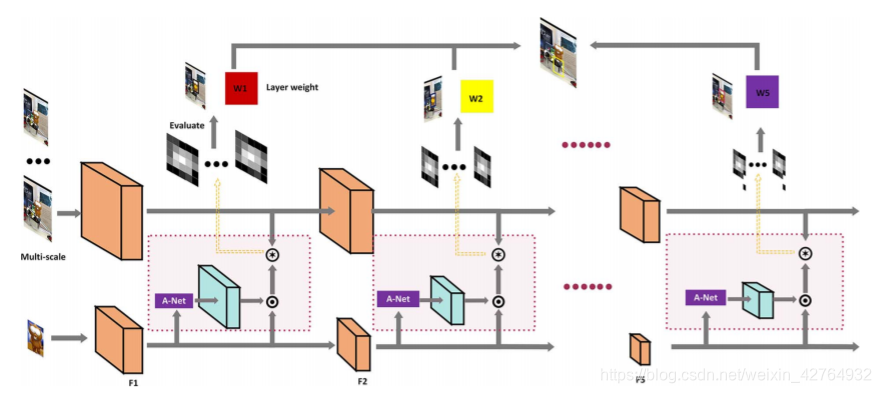
- 由目标求得关键部位,然后在孪生网络的每层卷积后,由A-Net输出经过注意力加权的attentive feature map,与该层待搜索区的feature map进行互相关,获得响应图。
- 最终位置由所有响应图估计,目标大小由所有响应图采用投票策略估计。