主要参考了深度学习在视觉SLAM方向的可行性/方向,同时加入了自己的一些理解
背景:本文统计的是2018年及以前的相关论,未涉及2019年的论文。
文章目录
参考资料:
[1] Deep learning + SLAM小综述(博客,2018.08)
[2] GSLAM——一个通用、跨平台和完全开源的SLAM交互程序
[3] 微信公众账号“计算机视觉life”内容集锦
[4] 视觉SLAM-无人驾驶实战课程
[5] ICRA 2019 论文速览 | SLAM 爱上 Deep Learning(这是一个系列,暂时还没更新完,07.11)
[6] 这篇文章具有重大的价值,总结的论文非常多
1. 深度学习+SLAM的可行性
- 长期来讲,深度学习有极大可能会去替代目前SLAM技术中的某些模块,但彻底端到端取代SLAM可能性不大。
- 短期来讲(三到五年),深度学习不会对传统SLAM技术产生很大冲击
2. 深度学习+SLAM的 5 个主要研究方向
- 1)单目SLAM学习尺度/深度
- 2)相机重定位 / 闭环检测
- 3)前端提取特征和匹配
- 4)端到端学习相机位姿
- 5)语义SLAM
3. 单目SLAM学习尺度/深度
特点:
- 单目纯视觉SLAM最大的问题是缺乏尺度信息,于是最直观的思路就是引入深度学习来脑补图像的尺度/深度信息
示例1:CNN-SLAM
- 如TUM发表在CVPR17上的CNN-SLAM,将LSD-SLAM里的深度估计和图像匹配都替换成基于CNN的方法,取得了较为鲁棒的结果。
- 实际上,相关工作的精度确实不高,CNN-SLAM在室内每个像素的平均误差约50cm,在室外则高达7米,相比传统三角化深度在精度上有一定差距.但优势在于鲁棒性较强,传统三角化所面临的视差太大太小问题再DL这里都不存在。

示例2:GEN-SLAM
- GEN-SLAM:一种用于单目SLAM的深度学习生成模型。来自福特的无人驾驶研究人员提出了一个基于深度学习的系统,可通过单目RGB传感器实现位姿估计和深度估计。整个系统基于传统的几何SLAM结果来训练,实现单个相机能够输出在其环境中的拓扑姿态,以及周围障碍物的深度图。
- 基于这篇文章提出的方案可以先使用深度传感器和传统几何SLAM方法进行一次预先构建地图,然后使用该地图作为先验结合本文的模型进行训练。随后这些移动机器人只需配备低成本的单目相机,就可以利用训练好的模型来实现复杂工厂环境下的感知与导航额。
- 拓扑地图生成。作者利用ORB-SLAM2算法获得相机运动轨迹,为确保路径可重复,作者先用ORB-SLAM2建图并保存,在后续实验中以此地图来实现定位功能,并让机器人按照同样的路径规划运动.

示例3:单目深度估计和视觉里程计无监督学习
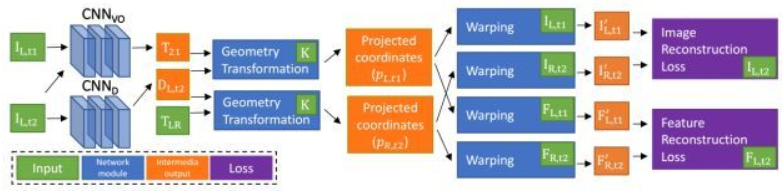
本文工作的目标是解决无监督学习的尺度不确定问题,采用双目数据联合训练深度估计和视觉里程计网络,应用时只需单目图像输入即可,即可得到深度估计值和单目相机的转移矩阵(可实现视觉里程计的功能).作者设计了基于帧到帧的视觉里程计,性能显著优于同类无监督学习方法,且与基本几何的方法相当。
参考文章:
[1] CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction(2017)
[2] GEN-SLAM: Generative Modeling for Monocular Simultaneous Localization and Mapping(2019)
[3] Unsupervised Learning of Monocular Depth Estimation and Visual Odometry with Deep Feature Reconstruction(2018),https://github.com/Huangying-Zhan/ Depth-VO-Feat
4. 相机重定位/闭环检测
特点:
- 相机重定位/闭环检测通常需要对当前时刻各类传感器的信息进行特征提取,并与之前得到的历史数据进行搜索匹配,以便在跟丢后==重新获取一个初始位置/判断是否到达了某个历史位置。==这一过程与传统的图像匹配有一定相似性,时比较适合用深度学习去完成的一类任务。
示例1:PoseNet DL+SLAM
- 代表工作如DL+SLAM的开山之作——剑桥的论文:ICCV15的PoseNet,使用GoogleNet去做6-dof的相机位姿的回归模型,并利用得到的pose进行重定位。


评价: - 其结果在当时(15年)非常具有开创性,但其主要意义还是在于开创了一种新的思路,其实用性及精确度并不如传统重定位方案来得可靠。
参考文章:
[1] PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization(2015),https://github.com/alexgkendall/caffe-posenet
[2] 基于深度学习的视觉SLAM闭环检测的性能评估(2018),本文主要的贡献是对目前主流深度神经网络,比如PCANet,CaffeNet,AlexNet,GoogleNet和传统的词带模型(BoW)和全局特征信息(GIST)在闭环检测中的性能表现做了比较分析。
5. 前端提取特征和匹配
特点:
- DL用于特征提取及图像匹配是一个比较有潜力的方向,因为传统的特征提取,描述匹配方案在数学上并没有一个非常清晰完整的解释,并且目前看来也很难用数学去进行清晰的描述:如SIFT,FAST各类特征点对图像的理解仅局限于非常有限的点信息。光流追踪一直没有一个非常完美的数学框架。这一块儿去使用DL去进行high-level regression可能会取得意想不到的效果。
- 同时,特征提取及描述一直是SLAM算法中的耗时大户,花费大量的计算才能得到比较鲁棒精确的结果,并且其中很多计算是不可避免难以优化的。那么利用DL直接出特征会是一个值得一试的思路。毕竟目前DL的优化方法数不胜数。
示例1:Toward Geometric Deep SLAM
Magic Leap 17年放出的文章Toward Geometric Deep SLAM提出了一种基于CNN的提取特征点及匹配方法,包括两个网络,第一个用于提取二维特征点,第二个用于输出二维特征点的单应矩阵。无需描述子,无需繁杂的图像预处理,可以准确的定位到了物体的每个角点,高速轻量,在单核CPU上可达30fps,但代码未开源。


示例2:完整的特征处理pipeline
发表于ECCV16的 LIFT 提出了一种新型的深度网络,实现了完整的特征处理pipeline:包括检测,方向估计和特征描述。能提取出相比SIFT更加稠密的特征点,且给予了其端到端架构较好的解释性。从实验结果看来在几个数据集上的表现吊打目前所有传统的及基于DL的特征方案(包括SIFT),但未给出运行时间数据,估计其速度应该比较堪忧。


示例3:GCNv2
这篇文章提出了一种基于深度学习的关键字和描述符生成网络GCNv2,它基于为三维投影几何而训练的GCN而来。GCNv2设计了一个二进制描述符向量作为ORB特征,以便在诸如ORB-slam等系统中方便的替换ORB。GitHub地址:GCNv2。

参考文章:
[1] Toward Geometric Deep SLAM(2017)
[2] LIFT: Learned Invariant Feature Transform(2016),http://t.cn/RiepX4E
[3] GCNv2: Efficient Correspondence Prediction for Real-Time SLAM(2019),https://github.com/jiexiong2016/GCNv2_SLAM
6. 端到端学习相机位姿
特点:
- 端到端到端SLAM最大的优势即“端到端”:完全舍去前端提点跟踪、后端优化求解的一系列过程,直接输入图像给出位姿(或者位姿+深度)。
- 其实端到端就不能算是SLAM问题了,SLAM是同步定位与地图构建,端到端是输入image输出action,没有定位和建图。
示例1:SfM-Learner
- Google CVPR17的 SfM-Learner,文章的核心思想和 LSD-SLAM 如出一辙,本质都是优化 photometric error,是利用 photometric consistency 原理来估计每一帧的 depth 和 pose。photometric consistency 就是对于同一个物体的点,在不同两帧图像上投影点,图像灰度应该是一样的。仅用一段单目视频就可以训练两个网络,分别输出pose和depth。在KITTI数据集上的效果优于不开闭环重定位的ORB-SLAM,但略逊于开了闭环重定位的ORB-SLAM。


示例2:SfM-Net
- Google的 SfM-Net,可以说是SfM-Learner的升级版,除了计算pose和depth以外,还计算了光流,场景流,三维点云等,并且可以做场景运动目标分割,总之是一个非常强大的网络。
示例3:DeMoN
CVPR17的DeMoN: Depth and Motion Network for Learning Monocular Stereo,和前面的SfM-Learner较为相似,使用pose,depth作为监督信息,来估计pose和depth。

示例4:UnDeepVO
ICRA18的UnDeepVO,利用双目图像信息进行无监督训练网络得到尺度,并用于单目SLAM,可以估计单目相机的6自由度位姿以及使用深度神经网络估计单目视角的深度。UnDeepVO有两个显著的特性:一个是无监督深度学习方法,另一个是绝对尺度恢复。在KITTI数据集上的效果高于前面的SfM-Learner和不开闭环的ORB-SLAM。


评价:
- 用DL做端到端SLAM非常简单粗暴,能够绕开许多传统SLAM框架中极为麻烦的步骤如外参标定、时间戳同步,同时避开前后端算法中许多棘手的问题。作为一种全新的思路具有一定的意义。
- 但同样端到端SLAM的问题也非常明显,和前面所说的深度估计类似,SLAM这样一个包含很多几何模型非常数学的问题,通过深度学习去端到端解决,在原理上是完全没有依据的,而且也没理由能得到高精度解。
- 另一个很大的问题是模型的泛化性难以保证。目前的SLAM系统(视觉里程计)通常会有一个非常复杂的框架,从前端到后端每一步都有明确的目的,有完整的数学理论支撑,具有很强的解释性。而用高度依赖数据的DL去粗暴地近似SLAM系统,对于某些数据集可能效果不错,换个场景可能就无法跟踪。
- 事实上,目前的端到端深度学习SLAM确实在精度上并不能和state-of-the-art的传统方法媲美,大部分工作无法直接用视频进行训练,训练过程较为麻烦。
简单来说,就是虽然简化了中间的所有步骤,但是就是黑箱啊,依赖特定数据
参考文献:
[1] SfM-Learner:Unsupervised Learning of Depth and Ego-Motion from Video(2017),https://github.com/tinghuiz/SfMLearner
[2] SfM-Net: Learning of Structure and Motion from Video(2017),非官方的TensorFlow代码:https://github.com/waxz/sfm_net,https://github.com/augustelalande/sfm
[3] DeMoN: Depth and Motion Network for Learning Monocular Stereo(2017),https://github.com/lmb-freiburg/demon
[4] UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning(2018)
7. 语义SLAM
特点:
- 语义SLAM是SLAM未来发展的一个重要方向。传统SLAM主要解决的问题是:机器人在哪里,机器人要怎么走,对图像的理解通常只限于低级且有限的点特征。但是没有回答:机器人周边环境的物体是什么,有什么特点,理想的情况应当能像人类一样对图像进行高层语义层面理解。这个不但从商业的角度来说想象空间和商机非常大,而且对终端用户来说更实用更有意义。
- 如果说稀疏SLAM的稀疏地图点是为了跟踪和重定位,稠密SLAM的稠密点云或者mesh是为了场景重建,那么语义SLAM才是真的全方位“环境重建”。
示例1: CNN-SLAM
前面提过的 ==CNN-SLAM ==除了用CNN估计深度外,还用了CNN做图像语义分割,然后将geometry和semantic融合起来,生成具有语义信息的地图。
示例2:构建语义地图
2016年的工作 Semi-Dense 3D Semantic Mapping from Monocular SLAM,利用 ==LSD-SLAM ==作为框架,引入DL进行语义地图构建,选择关键帧进行做深度学习实现语义分割,之后选择相邻的几帧做增强。本质上是做了二维语义分割,然后利用SLAM投影到三维空间中去。可在室内外环境工作。

示例3:Meaningful Maps With Object-Oriented Semantic Mapping
Meaningful Maps With Object-Oriented Semantic Mapping,输入RGB-D图像 -> ORB-SLAM2应用于每一帧,SSD(Single Shot MultiBox Detector)用于每一个关键帧进行目标检测,3D无监督分割方法对于每一个检测结果生成一个3D点云分割 -> 使用类似ICP的匹配值方法进行数据关联,以决定是否在地图中创建新的对象或者跟已有对象建立检测上的关联 -> 地图对象的3D模型(3D点云分割,指向ORB-SLAM2中位姿图的指针,对每个类别的累计置信度)

示例4:Probabilistic data association for semantic SLAM
ICRA17 best paper 的 Probabilistic data association for semantic SLAM 在数学上很有条理很严谨地解答了SLAM几何上的状态(sensor states)和语义的地标(semantic landmark)一起构成的优化问题,在ORB-SLAM2的基础上引入DL来进行语义SLAM中的数据关联,语义识别物体,并将目标检测的结果作为SLAM前端的输入,与传统特征互补提高定位鲁棒性。难点在于detection结果的data association最好能和定位联合优化,即构建紧耦合优化,但前者是个离散问题。文章利用EM算法首次针对融合了语义信息的SLAM问题给出了求解思路。作者通篇是公式,没有给出网络框架,没有找到源代码。

示例5:语义视觉里程计
- 《VSO: Visual Semantic Odometry》这篇文章依然使用 EM 估计,在上一篇的基础上使用距离变换将分割结果的边缘作为约束,同时依然利用投影误差构造约束条件。在 ORB SLAM2 和 PhotoBundle 上做了验证取得了一定效果。这篇文章引入距离变换的思路比较直观,很多人可能都能想到,不过能够做 work 以及做了很多细节上的尝试,依然是非常不容易的。但仍然存在一个问题是,分割的边缘并不代表是物体几何上的边缘,不同的视角这一分割边缘也是不停变化的,因此这一假设也不是非常合理。
- 该篇论文提出了一种用语义信息实现中期连续点跟踪的方法。可以被简单地融合进已有的直接或间接视觉里程计框架中。在自动驾驶下应用该方法实现了巨大改善。

示例6:3D目标检测与追踪,定位
SLAM 是一个多传感器融合的框架,RGB、激光、语义、IMU、码盘等等都是不同的观测,所以只要是解决关于定位的问题,SLAM 的框架都是一样适用的。在这篇文章中,他们将不同物体看成不同的 Map,一边重建一边跟踪。使用的跟踪方法仍然是传统的 Local Feature,而 VIO 作为世界坐标系的运动估计。语义融合方面,他们构造了4个优化项,最终取得了很好的效果。(大综合啊)

示例7:自动驾驶中基于语义分割的定位
《Long-term Visual Localization using Semantically Segmented Images》,这篇论文讲得比较有意思,它不是一个完整的SLAM系统,不能解决Mapping的问题。它解决的问题是,当我已经有了一个很好的3D地图后,我用这个地图怎么来定位。在传统方法中,我们的定位也是基于特征匹配的,要么匹配 Local Feature 要么匹配线、边等等几何特征。而我们看人在定位时的思维,其实人看不到这么细节的特征的,通常人是从物体级别去定位,比如我的位置东边是某某大楼,西边有个学校,前边有个公交车,我自己在公交站牌的旁边这种方式。当你把你的位置这样描述出来的时候,如果我自己知道你说的这些东西在地图上的位置,我就可以基本确定你在什么地方了。这篇文章就有一点这种意思在里边,不过它用的观测结果是分割,用的定位方法是粒子滤波。它的地图是三维点云和点云上每个点的物体分类。利用这样语义级别的约束,它仍然达到了很好的定位效果。可想而知这样的方法有一定的优点,比如语义比局部特征稳定等;当然也有缺点,你的观测中的语义信息要比较丰富,如果场景中你只能偶尔分割出一两个物体,那是没有办法work的。

参考文献:
[1] Semi-Dense 3D Semantic Mapping from Monocular SLAM(2016)
[2] Meaningful Maps With Object-Oriented Semantic Mapping(2017)
[2] Probabilistic data association for semantic SLAM(2017)
[3] VSO: Visual Semantic Odometry(2018)
[5] Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving(2018)
[6] Long-term Visual Localization using Semantically Segmented Images(2018)