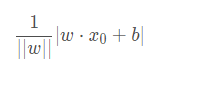在这篇文章我们主要了解感知机定义、功能、模型如何去获得损失函数、以及有哪些方法去将损失函数极小化,从而确定模型参数
感知机模型的定义:
输入空间由xi(xi(1),xi(2),xi(3)…xi(n))组成,输出空间为{-1, +1},由输入空间到输出空间的映射函数为 f(x)=sign(w·x+b) 称为感知机。其中w是权重向量,b称为偏置,w·x为w和x的内积。sign(x)是符号函数,即:
0

为了便于计算,我们往往会把线性不可分的样本在某种变换下成为线性可分。如果我们找不到一条直线可以把正负样本划分开那么我们可以通过两条直线来划分它,两者满足我们就说它是正样本,其它的就为负样本。还有一种划分方式,在工业界,人们往往会找一条曲线将其分隔开,但是问题是这条曲线怎么做呢?这就是我们要思考的问题,其实道理也很简单,我们先做一些线性分类器,然后我们在做线性分类器的叠加,形成一个锯齿状的线,而不是一条圆滑的线。总的来说,也就是说通过多个线性的分类器,逐个做组合来完成非线性的分割。
感知机模型图如下
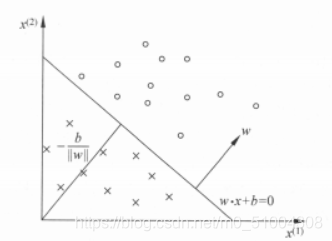
从模型可看出,很明显我们要求解w和b,也就是说只有这样我们才能正确的分离所有正负样本的超平面S,那么要如何确定w和b,这就需要一个损失函数,并将损失函数极小化。我们通常采用的方法是梯度下降法来找到最优值,当然后面还会介绍比梯度下降法更好的方法,比如说有Momentum、AdaGrad、Adam。下面是这些方法的介绍(说的挺言简意赅的)
https://blog.csdn.net/m0_51004308/article/details/112614340
损失函数
我觉得这篇博客写的挺好的,这里就借鉴一下这篇大佬写的,下面是他的链接。
选择误分类点到超平面 S 的总距离作为损失函数。
首先,找出一个误分类点到超平面的距离
因为输入空间xi(xi(1),xi(2),xi(3)…xi(n))中任一点 x0到超平面S的距离: