原理
1、网络的结构
BP网是一种前馈多层(一般都选用3层)网络。理论已经证明一个三 层网络可以无限近似任意连续函数。下面为经典的三层BP网络结构:

其中:
xi :输入层第i个结点输入值 ;
wij :输入层结点i到隐含层结点j的权重 ;
θj :隐含层第j个结点的阈值 ;
φ(x): 隐含层激励函数 ;
wjk :隐含层结点j到输出层结点k的权重 ;
bk:输出层结点k的阈值 ;
f(x):输出层激励函数 ;
yk:输出层第k个结点的输出 。
2、训练过程
训练算法就是将一组训练集送入网络,根据网络的实际输出与期望输出间的差别来调整连接权。
训练过程如下:
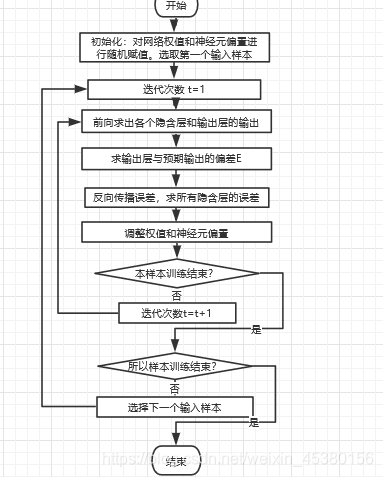
步骤:
1、初始化网络权重:给wi(0) (i=1,2…n) 及每个神经元的偏置 赋予一个较小的非0随机数作为初值
2、向前传播输入:输入一个样例 x=[x1,x2…xn] 和期望的输出
3、反向误差传播:计算网络的实际输出
4、网络权重与神经元偏置调整:调整权值 wi(t+1)=wi(t)+A[d-y(t)]xi ,其中 0<A<=1;增益因子,控制调整速度
5、判断结束
实验函数分析:
1、生成网络(newp)
用于生成可以解决线性可分问题的感知机,代码如下图:

net 为生成的感知机;
生成的初始权值和阈值均为0,可对其进行赋值,如 权重 net.IW{1,1}=[-1 1]; 阈值 net.b{1}=1。
2、网络仿真(sim)
网络仿真用于验证网络训练结果,代码如下图:

net 为生成的神经网络;
p1、p2、p3 、p4 为网络输入 ;
a1、a2、a3、a4为网络输出。
3、网络初始化( init)
用于将神经网络的权值和阈值恢复初始值或者赋予随机值,代码如下图:

这三条命令可以改变网络的权值和阈值为随机数:
net.inputweights{1,1}.initFcn=‘rands’;
net.biases{1}.initFcn=‘rands’;
net=init(net);
4、网络学习(learnp)
网络学习,learnp是感知器重量/偏差学习功能。代码如下图:

learnp 根据感知器学习规则从神经元的输入p和误差e计算给定神经元的权重变化dw:
如果e = 0 ,dw = 0,
如果e = 1 ,dw = p’,
如果e = -1 ,= -p’,
这可以概括为 dw = e * p’
5、网络训练
对生成网络进行训练,代码如下图:

对网络进行训练的时候出现如下图:
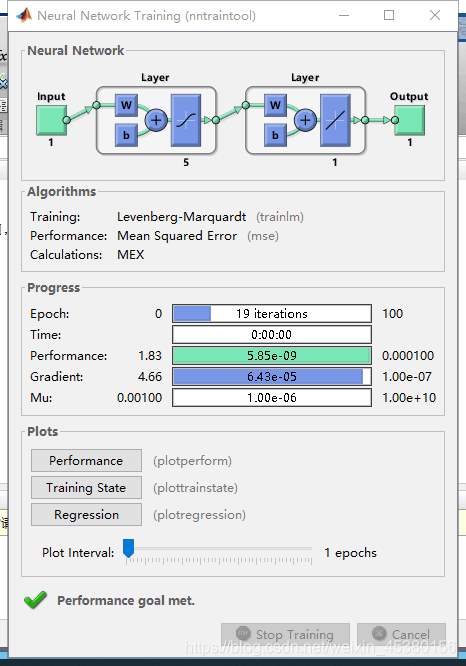
由上图中的Netrual Network项可知,这是一个两层的网络。
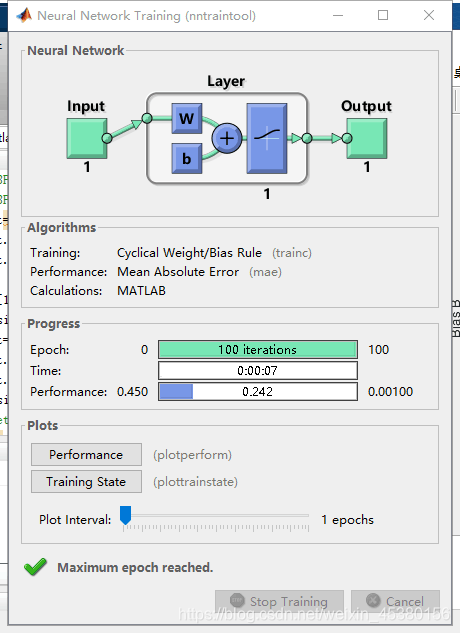
Epoch:训练次数 ,一般情况下,训练的次数都会达到最大的训练次数才会停止训练(点击Stop Trainning按键的除外)。但是,如果在
train参数中,指定了确定样本,则可能会提前停止训练。
Time:训练时间,也就是本次训练中,使用的时间。
Performance:性能指标。
Gradiengt:梯度。 进度条中显示的当前的梯度值,其右边显示的是设定的梯度值。如果当前的梯度值达到了设定值,则停止训练。
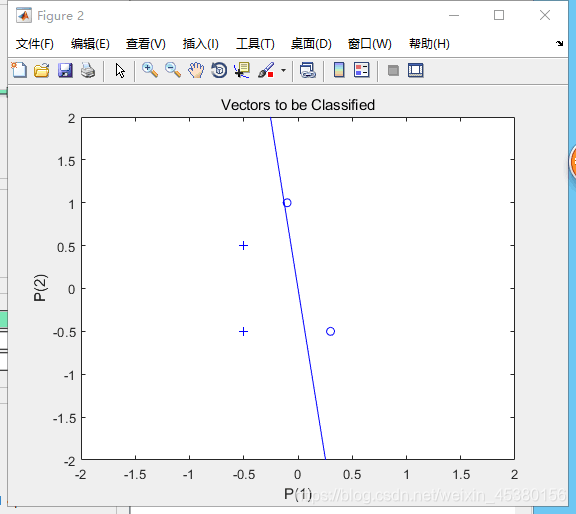
代码运行结果