K-Means 算法是最简单的一种聚类算法,属于无监督学习算法。
聚类和分类最大的不同在于:分类的目标是事先已知的,而聚类则不一样,聚类事先不知道目标变量是什么,类别没有像分类那样被预先定义出来。
假设我们的样本是 {x^(1), x^(2), x^(3),……, x^(m) },每个 x^(i) ∈ R^n,即它是一个维向量。现在用户给定一个 k 值,要求将样本聚类成 k 个类簇。在这里,我们把整个算法成为聚类算法,聚类算法的结果是一系列的类簇。
步骤:
输入:样本集 D,簇的数目 k,最大迭代次数N;
输出:簇划分( k 个簇,使平方误差最小)
(1)为每个聚类选择一个初始聚类中心;
(2)将样本集按照最小距离原则分配到最邻近聚类;
(3)使用每个聚类的样本均值更新聚类中心;
(4)重复步骤(2)(3),直到聚类中心不再发生变化;
(5)输出最终的聚类中心和 k 个簇划分。
涉及距离的计算,最常用的距离是欧氏距离(Euclidean Distance),公式为:
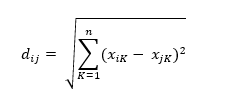
此外,还有闵可夫斯基距离:
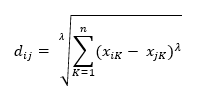
曼哈顿距离(也称为城市街区距离,City Block Distance):
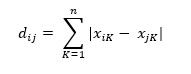
优点:
(1) 算法简单,容易实现
(2) 算法速度很快
(3) 对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(NKt),其中,N 为数据对象的数目,t 为迭代的次数。一般来说, K <<N ,t <<N。这个算法通常局部收敛。
(4) 算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好。
缺点:
(1) K是事先给定的,一个合适的 K 值难以估计。
(2) 在 K-Means 算法中,首先需要根据初始类簇中心来确定一个初始划分,然后对初始划分进行优化。初始类簇中心的选择对聚类结果有较大的影响。一旦选择的不好,可能无法得到有效的聚类结果。可以使用遗传算法来选择合适的初始类簇中心。
(3) 算法需要不断地进行样本分类调整,不断计算调整后的新的类簇中心,因此当数据量非常大的时,算法的时间开销是非常大的。可以利用采样策略,改进算法效率。也就是初始点的选择,以及每一次迭代完成时对数据的调整,都是建立在随机采样的样本数据的基础之上,这样可以提高算法的收敛速度。