sort命令
概述
- sort 命令用于将文件内容进行排序,并将排序结果打印到标准输出
- 它将文件的每一行文本视为一个单位,以行为单位对文件内容进行排序
- 也可以根据不同的数据类型来排序
语法格式
sort [选项] [参数]
cat [对象] | sort [选项]
常用选项
| 常用选项 | 解释 |
|---|---|
| -f | 排序时,将小写字母视为大写字母(即忽略大小写),默认会将大写字母排在前面 |
| -n | 按照数值的大小进行排序 |
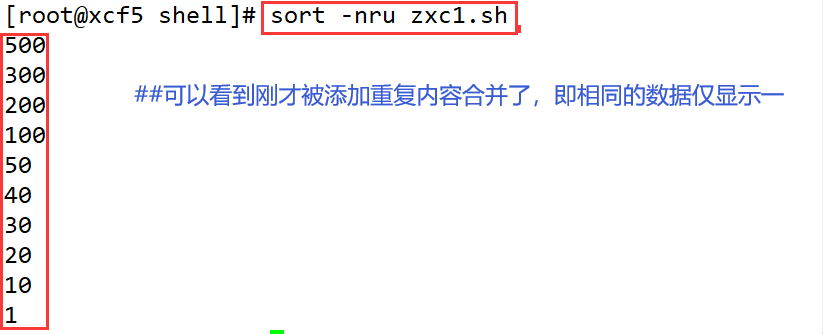
| -r | 以相反的顺序输出排序后的结果 |
| -u | 合并显示内容相同的行,表示相同的数据仅显示一行,等同于uniq |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o <输出文件> | 将排序好的结果输出到指定文件中 |
示例
- -n、-r
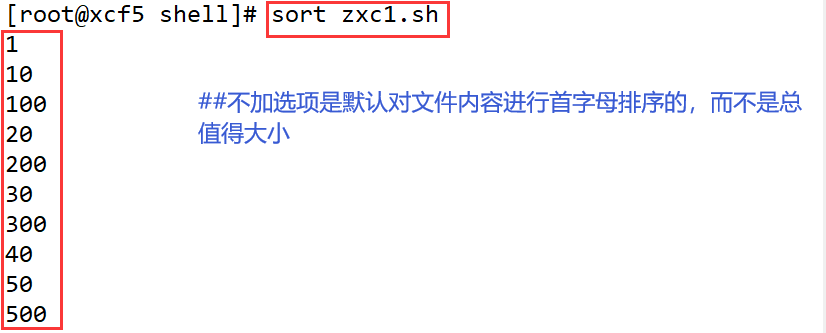
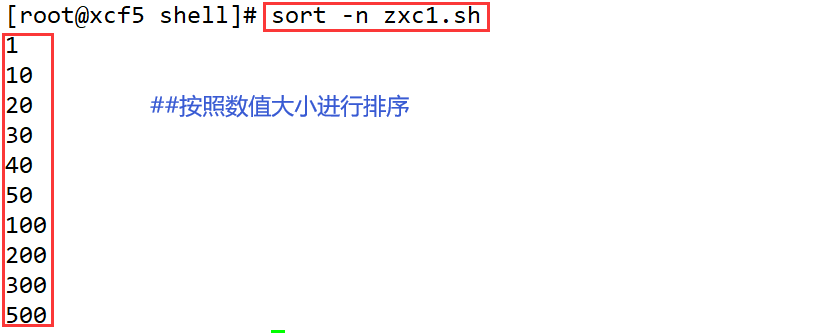

- -f


- -u

- -t、-k
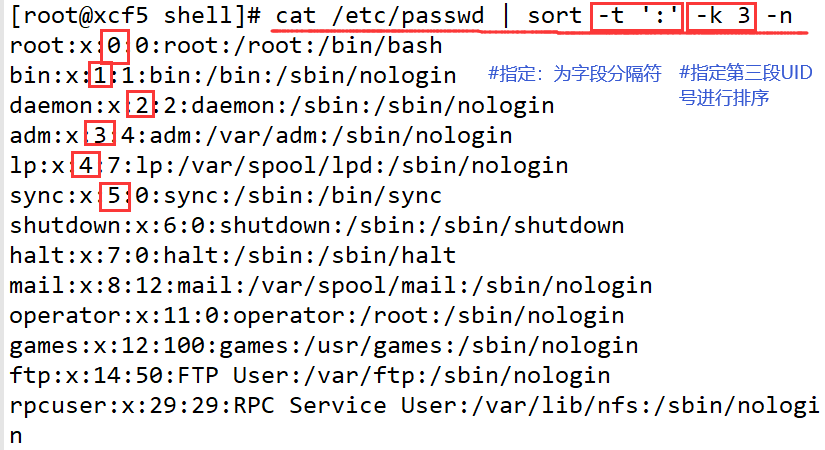
- -o

uniq命令
概述
- uniq命令用于报告或者忽略文件中连续的重复行
- 常与sort命令结合使用
语法格式
uniq [选项] 参数
cat [对象] | uniq 选项
常用选项
| 常用选项 | 解释 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |
示例

- -c

- -d、-u

- 结合sort命令使用
- 可以统计出重复次数最多的对象,这里可以应用到检测黑客攻击

tr命令
概述
- tr(translate)命令可以用来对来自标准输入的字符进行替换、压缩和删除
语法格式
tr [选项] [字符集1 字符集2]
##没有选项,则默认将标准输入中所有属于字符集1 的字符替换为字符集2中的字符
常用选项
| 常用选项 | 解释 |
|---|---|
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符串;用字符集2替换字符集1 |
| -t | 字符集2替换字符集1,不加选项同结果 |
参数
- 字符集1:
- 指定要转换或删除的原字符集
- 当执行转换操作时,必须使用参数“字符集2”指定转换的目标字符集
- 但执行删除操作时,不需要参数“字符集2”:
- 字符集2:
- 指定要转换成的目标字符集
示例
- 大小写转换

- -c

- -d

- -s


- 删除空行

or


- 把路径变量中的":",替换成换行符"\n"
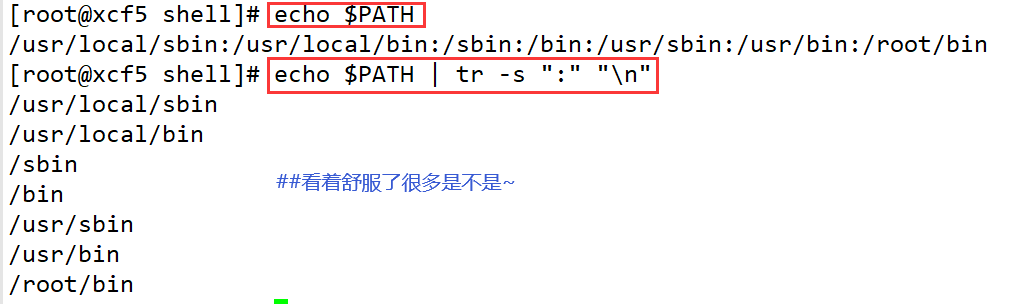
or

- Windows端传输到Linux的文件可能存在不兼容的问题,会出现"^M"字符
cat [对象] | tr -s "\r" "\n" > [新文件对象]
or
cat [对象] | tr -d "\r" > [新文件对象]
Linux中遇到换行符("\n")会进行回车+换行的操作,回车符反而只会作为控制字符("^M")显示,不发生回车的操作
而windows中要回车符+换行符("\r\n")才会回车+换行,缺少一个控制符或者顺序不对都不能正确的另起一行
首先在宿主机新建一个txt文件,内容随意
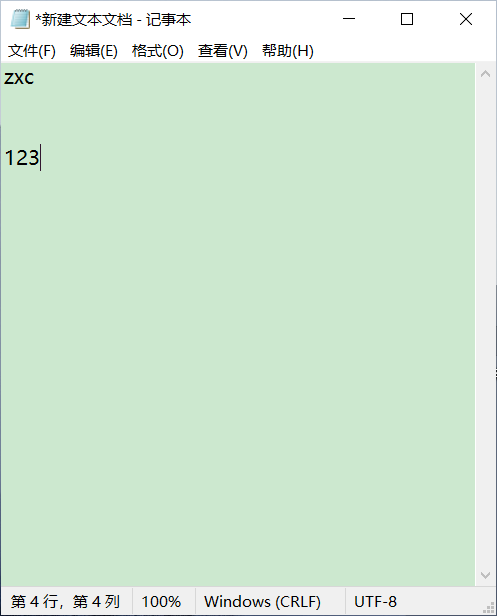
保存文件后拖进xshell并查看下



- 数组排序
你看的没错!tr可以用来数组排序!!
