<1> wc 统计字符 行 单词
wc -l
wc -w
wc -c
wc可以可以放在文件前面 也可以放在文件后面,如上图。<2> cut 切 顾名思义就是切割文件用的
作用:是切割一任意行文件的列....
但是默认按照空格来分割的个格列的
当然可以使用 cut -d 来指定分隔符 如 cut -d: cat -d"22",但是其默认参数必须要跟上-f 指定输出第几列,不指定就会报错
常用的也就-d -f 但是还有一个是以前没用用到过的,就是指定输出分隔符 --output-delimiter
这个的意思是 以 : 为分隔符切割 打印出第1,2列 然后以&为分隔符输出且只显示前十行。。
按照文本文件的行进行排序 例如: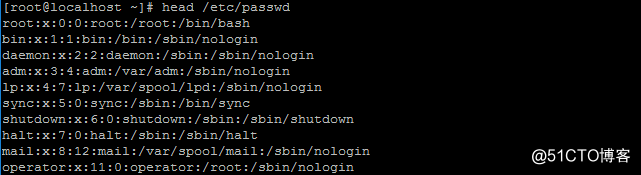
这是默认排序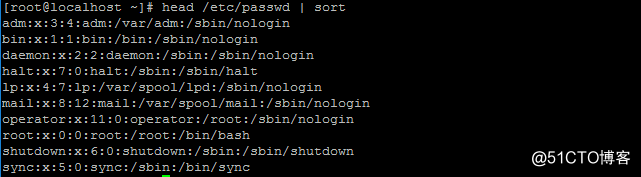
这个是使用sort排序后的输出,默认按照.....啥来着 忘了 试一下
创建了个文本 有特殊符号 大小写字母 数字
{穿插一个小知识点
这个是新创建的文本文档 可以看到里面有空字符开头的行 首先把空字符的去掉吧 让后另存为到其他文本文档
查找以空格开头的行 让后取反
接着重定向到/tmp/sort.txt
}
然后使用sort排序 下图 可以看到排序依次是特殊符号,数字,小写字母,大写字母。。。
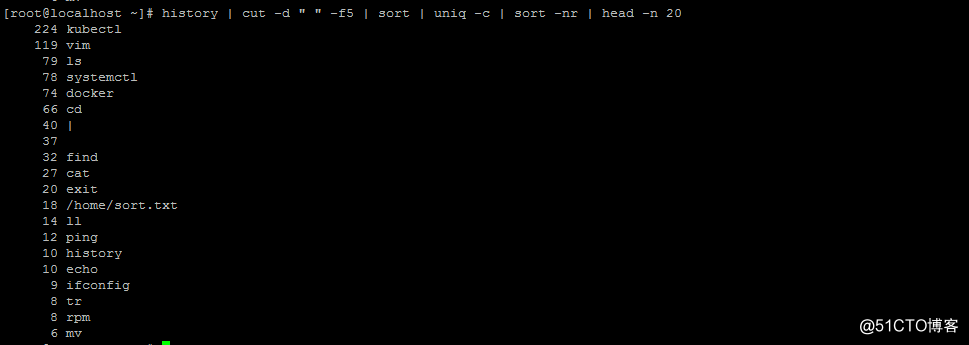
此命令是 列出历史命令中出现次数最多的前20个命令
这里需要记录的是两个命令
一个是sort 排序命令 其中两个选项 -n是按照数值大小排序 -r 取反
还有一个uniq命令 去重的意思,一个选项 -c 显示重复的次数
整个命令组合在面试的时候常被问到,一般都是统计某个时间段内,访问某网站次数最多的前10个ip地址
额 睡觉了....