cut:
将文件中的每一行”字节” ”字符” ”字段” 进行剪切, 并将这些选取好的数据输出至标准输出
格式: cut OPTION... [FILE]...
-d DELINMITER:指定分隔符,默认tab,一般和-f连用
-f FILEDS:
#:第#个字段
#,#[,#]:离散的多个字段,例如1,3,6
#-#:连续的多个字段,例如1-4
混合使用:1-4,6
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
例1:

例2:

paste:合并两个文件同行号的列到一行
格式:paste [OPTION]... [FILE]...
-d 分隔符:指定分隔符,默认为TAB
-s:所有行合成一行显示
例1:
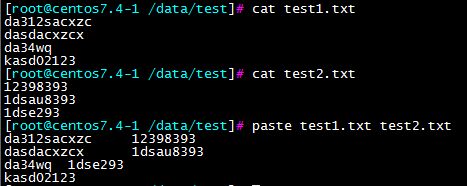
例2:

例3:

wc:文本数据统计,可以对文件或STDIN中的数据进行计数
格式:wc [OPTION]... [FILE]...
wc [OPTION]... --files0-from=F

行数 字数 字节数
-l:只计数行数
-w:只计数单词总数
-m:只计数字符总数
-L:显示文件中最长的长度
sort:文本排序,但不改变原始文件
格式:sort [OPTION]... [FILE]...
sort [OPTION]... --files0-from=F
-r:倒序显示
-R:随机排序
-n:按照数字顺序排序
-f:选项忽略字符串中的字符的大小写
-u:删除输出中的重复行
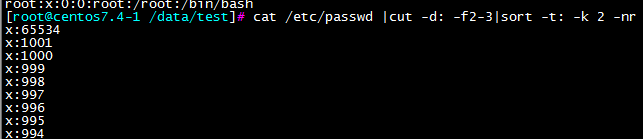
-t c:使用c作为字段的界定符
-k X:按章使用c字符分隔的X列来整理使用
uniq:从输入中删除前后连续出现重复的行
格式:uniq [OPTION]... [INPUT [OUTPUT]]
-c:显示每行重复出现的次数
-d:仅显示重复过的行
-u:仅显示不曾重复的行
注:连续且完全相同的访问重复
一般情况下,都是与sort一切配合使用的

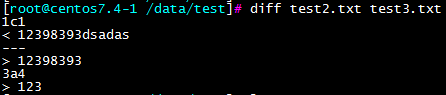
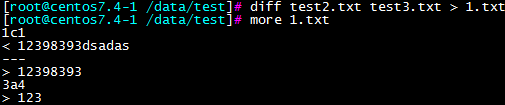
diff:比较两个文件之间的区别
其中第一行存在问题,且test2是最后一行和test3对比少了一行
-u:会将不同的地方放在一起,紧凑易读
-r:递归比较目录下的所有文件(比较文件夹时候一定要接-r)
diff通过对比也可以生成补丁,后使用patch 进行文件对修改,同步成相同的一个文件
patch:
复制在其它文件中进行的改变(要谨慎使用)
-pN:N表示忽略N层路径
-R: 还原到老版本