前面几篇都是有关于数字和字母的识别方法,当然了,我们大多数遇到的项目也都是读取数字和字母,但有时候如果我们遇到汉字了,而halcon里面是没有汉字字库的,所以这个时候就要用到训练了,那么这篇文章就是来介绍下一般步骤下字符训练的过程和方法(当然也可以用于不规则的数字字母)。
在汉字识别前,再补充介绍一种投影矫正OCR:
原图:

代码如下:
read_image
(Image,'C:/Users/Administrator/Desktop/slate.jpg')
decompose3 (Image, R, G, B)
dev_display (R)
*按照逆时针的方向,依次获取车牌四个角落的行列值,关于这个方向你可以按照个人的习惯来,你可以顺时针也可以逆时针,只要上下统一就行。
*逆时针
RowCorner:=[88,185,257,152]
ColCorner:=[82,87,367,366]
*顺时针
* RowCorner:=[88,152,257,185]
* ColCorner:=[82,366,367,87]
dev_set_line_width (5)
gen_cross_contour_xld (Cross, RowCorner, ColCorner, 20, 0.785398)
*如果上面找区域的四个顶点是按照逆时针来选的,那么得到这个投影矩阵的时候
*矩阵运算后的点的顺序也要按照逆时针来填。
hom_vector_to_proj_hom_mat2d (RowCorner, ColCorner, [1,1,1,1], [80,160,160,80], [80,80,370,370], [1,1,1,1], 'normalized_dlt', HomMat2D)
projective_trans_image (R, TransImage, HomMat2D, 'bilinear', 'false', 'false')
顶点图:

最后矫正图片:

接下来就进行汉字识别的内容
训练的图片:

识别用的图片:

训练字符的代码如下:
read_image (Image, 'C:/Users/Administrator/Desktop/训练.png')
rgb1_to_gray (Image, GrayImage)
char_threshold (GrayImage, GrayImage, Characters, 3, 80, Threshold)
dilation_rectangle1 (Characters, RegionDilation, 5, 8)
connection (RegionDilation, ConnectedRegions1)
select_shape (ConnectedRegions1, SelectedRegions, ['height','area'], 'and', [29.69,333.12], [100,3903.62])
union1 (SelectedRegions, RegionUnion)
partition_rectangle (RegionUnion, Partitioned, 80, 75)
*一般汉字都是由点的,都是分开的,所以我们需要通过切开求交集的方式,将
*那些和本体分开的字合并成一个整体。
intersection (Partitioned, Characters, RegionIntersection)
sort_region (RegionIntersection, SortedRegions, 'character', 'true', 'row')
count_obj (SortedRegions, Number)
words:=['你','好','丫','美','女','加','个','微','信','呗']
*准备好训练文件地址
transfile:='C:/Users/Administrator/Desktop/word.trf'
*下面就是训练的过程了,循环将提前准备好的字符内容一一添加到训练文件中。
for i := 1 to Number by 1
select_obj (SortedRegions, ObjectSelected, i)
reduce_domain (GrayImage, ObjectSelected, ImageReduced)
append_ocr_trainf (ObjectSelected, ImageReduced, words[i-1], transfile)
endfor
*准备好字库文件地址
fontFile:='C:/Users/Administrator/Desktop/word.omc'
read_ocr_trainf_names (transfile, CharacterNames, CharacterCount)
create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, 80, 'none', 10, 42, OCRHandle)
trainf_ocr_class_mlp (OCRHandle, transfile, 200, 1, 0.01, Error, ErrorLog)
write_ocr_class_mlp (OCRHandle, fontFile)
clear_ocr_class_mlp (OCRHandle)
**********************
*以上的内容就是在整个训练的过程,每次有新的字体出现的时候你只需要在words数组里面添加
*相应的字就行了,下面就是利用训练好的字库omc文件识别字符。
**********************
下面就是打乱训练的字体的顺序,看能不能精准识别:
read_image (Image1, 'C:/Users/Administrator/Desktop/识别 .png')
rgb1_to_gray (Image1, GrayImage1)
binary_threshold (GrayImage1, Region, 'max_separability', 'dark', UsedThreshold)
dilation_rectangle1 (Region, RegionDilation1, 5, 7)
connection (RegionDilation1, ConnectedRegions)
select_shape (ConnectedRegions, SelectedRegions1, 'column', 'and', 0, 989.65)
intersection (SelectedRegions1, Region, RegionIntersection1)
sort_region (RegionIntersection1, SortedRegions1, 'character', 'true', 'column')
read_ocr_class_mlp ('C:/Users/Administrator/Desktop/word.omc', OCRHandle1)
do_ocr_multi_class_mlp (SortedRegions1, GrayImage1, OCRHandle1, Class, Confidence)
识别结果:
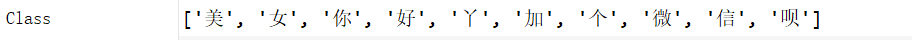
好了,最后结果准确无误。
有关于OCR识别的部分大致就是这些内容了,正常情况下,我们遇到的项目中的ocr识别(按照我目前遇到的一些项目中),我这几篇文章中的方法都能够解决。当然如果有大佬们遇到十分新奇的ocr项目也可以分享分享。识别不难,标准套路就行,难就难在前面怎么使用一些处理手段将相应的字符区域很好提取出来,这些部分就是八仙过海,各显神通了。