前言
OCR(Optical Character Recongnition)光学字符识别。
halcon 的OCR,提供了几种方式,我们应该如何选择?
- 自动文本阅读器(find_text)
- 手动文本阅读器(find_text)
- 自己分割再识别
自动文本阅读器
只需要指定一段字符的区域,然后指定一些参数,他就能自动识别!非常标准化的流程。
read_image (Image, 'numbers_scale')
* 创建模型,注意这里自动文本阅读器,第一个参数使用auto
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
* 设置模型参数
set_text_model_param (TextModel, 'min_char_height', 20)
* 根据设置好的模型进行识别
find_text (Image, TextModel, TextResultID)
* 获取字符分割的区域
get_text_object (Characters, TextResultID, 'all_lines')
* 获取分类结果
get_text_result (TextResultID, 'class', Class)
自动文本阅读器对应的set_text_model_param
set_text_model_param,对模型参数进行设置,用于对字符图像的分割。
OCR本质是需要将每个字符分割成单个区域,单个单个的识别的。所以分割每个字符是识别的必要的前奏。
“min_contrast”(最小对比度):字符与周围背景之间必须具有的最小对比度。
“polarity”(极性):文本与背景的对比度关系,可以是"dark_on_light"(文本比背景暗),“light_on_dark”(文本比背景亮)或"both"(两种情况都处理)。
“eliminate_border_blobs”(排除边界区域):是否排除与图像边界接触的区域。
“add_fragments”(添加片段):是否将文本中的片段(如’i’上的点)添加到分割的字符中。
“separate_touching_chars”(分离相邻字符):控制如何处理相邻字符的分割。
“min_char_height”(字符最小高度):字符的最小高度。 “max_char_height”(字符最大高度):字符的最大高度。
“min_char_width”(字符最小宽度):字符的最小宽度。 “max_char_width”(字符最大宽度):字符的最大宽度。
“min_stroke_width”(最小笔画宽度):字符的最小笔画宽度。
“max_stroke_width”(最大笔画宽度):字符的最大笔画宽度。
“return_punctuation”(返回标点符号):是否返回与文本行基线接近的小标点符号。
“return_separators”(返回分隔符):是否返回分隔符,如减号或等号。
“dot_print”(点印刷):文本中是否包含点印刷字符。
“dot_print_tight_char_spacing”(点印刷字符的字符间距是否较小)。
“dot_print_min_char_gap”(点印刷字符的最小字符间距)。
“dot_print_max_dot_gap”(点印刷字符的最大点间距)。
“text_line_structure”(文本行结构):定义文本行的结构,用于简化文本搜索。
在自动文本阅读器里,set_text_model_param 有这些参数可以帮助我们进行更精细的分割,其实大多数的值默认都是auto
所以在图片比较清晰的情况下,使用自动文本阅读器一般不用设置什么参数就能达到比较好的识别效果。
最后,自动文本阅读器通过 get_text_result 就可以拿到 识别的结果,识别的结果会放到一个字符串数组中!
手动文本阅读器
在自动文本阅读中,我们使用是:
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
手动文本阅读器,我们使用:
create_text_model_reader ('manual', [], TextModel)
区别在于,第一次参数改传 ‘manual’ 表示手动, 第二个参数和自动文本阅读器不同,没有传OCR分类器,而是一个空的数组。这是因为手动文本阅读器,只是完成分割这个步骤,不包含识别这个过程。
手动文本阅读器对应的set_text_model_param
“manual_char_height”(字符高度):字符的高度。
“manual_char_width”(字符宽度):字符的宽度。
“manual_stroke_width”(笔画宽度):字符的笔画宽度。
“manual_base_line_tolerance”(基线容差):字符的基线最大偏差。
“manual_polarity”(极性):文本与背景的对比度关系。
“manual_uppercase_only”(仅大写字符):文本是否仅包含大写字符或数字。
“manual_is_dotprint”(点印刷):文本是否是点印刷。
“manual_is_imprinted”(印记):文本是否受到反射引起的极性变化影响。
“manual_eliminate_horizontal_lines”(排除水平线):是否排除靠近文本的较长水平结构。
“manual_max_line_num”(最大行数):要查找的最大文本行数。
“manual_return_punctuation”(返回标点符号):是否返回标点符号。
“manual_return_separators”(返回分隔符):是否返回分隔符。
“manual_add_fragments”(添加片段):是否添加片段。
“manual_fragment_size_min”(片段的最小面积):要添加的片段的最小面积。
“manual_text_line_structure”(文本行结构):定义文本行的结构,用于简化文本搜索。
可以看到,手动文本阅读器对应的set_text_model_param 设置的参数 都是已 'manual_'开头的。(使用自动文本阅读器对应的参数将会报错!)
“auto"和"manual” 模式的分割逻辑
那,不同的模式"auto"和"manual" 他们分割的逻辑有什么不一样?
-
自动模式 (“auto” 模式):
- “auto” 模式是基于字符的图像特征和背景对比度来执行文本分割的。它使用一种自适应的方法来检测字符之间的边界,并将文本分割成字符。
- 在 “auto” 模式中,你需要设置一些参数,如最小对比度 (“min_contrast”)、字符最小高度 (“min_char_height”)、字符最大高度 (“max_char_height”)、字符最小宽度 (“min_char_width”)、字符最大宽度 (“max_char_width”)、最小笔画宽度 (“min_stroke_width”)、最大笔画宽度 (“max_stroke_width”) 等,以帮助分割算法确定字符的边界。
- “auto” 模式通常适用于较通用的文本分割任务,其中文本的字符大小和外观可能会有所变化。它对于不需要精确控制字符属性的应用场景很有用。
-
手动模式 (“manual” 模式):
- “manual” 模式允许用户手动设置字符的属性,如字符高度 (“manual_char_height”)、字符宽度 (“manual_char_width”)、笔画宽度 (“manual_stroke_width”) 等。这些参数将用于文本分割。
- 在 “manual” 模式中,用户需要更详细地描述要分割的文本的特征。这种方式通常用于特定字符或特殊文本类型的分割任务,其中字符的属性已知并且相对一致。
- “manual” 模式可以用于处理特定的印刷风格,如点印刷字符 (“dot_print”) 或具有特定笔画宽度 (“manual_stroke_width”) 的文本。
总之,“auto” 模式是一种更自适应的文本分割方法,适用于一般性的文本分割任务,而 “manual” 模式允许用户更精确地定义字符属性,适用于特殊字符或文本类型的分割任务。选择哪种模式取决于你的具体应用需求和文本样本的特性。
一般背景比较复杂,不容易区分的,比如镭雕的字符,就更适合使用手动模式区分!
手动文本阅读器的识别过程
那,手动文本阅读器分割之后,如何完成识别呢? 分割完成之后,其实手动文本阅读器的工作就完成了,
识别的过程和手动文本阅读器已经无关了。
在自动文本阅读中,我们创建的时候就传入的分类器的类型。
create_text_model_reader ('auto', 'Document_Rej.omc', TextModel)
因为自动文本阅读器,帮我们完成了识别过程,现在我们要单独的完成识别工程:
首先,我需要读取分类器:
read_ocr_class_mlp ('Industrial_0-9A-Z_Rej.omc', OcrHandle)
halcon 为我们提供了很多类型的训练好的分类器(就是这个.omc结尾的文件),选择合适的分类器可以提高我们的识别率。
如何选择合适的分类器,我们留到后面再说。
给出完成分割和识别的代码:
*//-------------分割部分
create_text_model_reader ('manual', [], TextModel)
*//参数设置
set_text_model_param (TextModel, 'manual_polarity', 'light_on_dark')
set_text_model_param (TextModel, 'manual_char_width', 104)
set_text_model_param (TextModel, 'manual_char_height', 105)
set_text_model_param (TextModel, 'manual_stroke_width', 21)
set_text_model_param (TextModel, 'manual_return_punctuation', 'false')
set_text_model_param (TextModel, 'manual_uppercase_only', 'true')
set_text_model_param (TextModel, 'manual_fragment_size_min', 100)
set_text_model_param (TextModel, 'manual_eliminate_border_blobs', 'true')
set_text_model_param (TextModel, 'manual_base_line_tolerance', 0.2)
set_text_model_param (TextModel, 'manual_max_line_num', 1)
*//-----------------识别部分
read_ocr_class_mlp ('Industrial_0-9A-Z_Rej.omc', OcrHandle)
//* 根据设置好的模型进行识别
find_text (Image, TextModel, TextResult)
//* 获取字符分割的区域。 ps:这里和自动的不同,使用的是 manual_all_lines 不是 all_lines
get_text_object (Characters, TextResult, 'manual_all_lines')
//* 获取结果
get_text_result (TextResult, 'manual_num_lines', ResultValue)
dev_display (Characters)
do_ocr_multi_class_mlp (Characters, TmpInverted, OcrHandle, SymbolNames, Confidences)
get_text_result 结果获取
注意和get_text_object 区分哈,get_text_object 是获取分割的区域,get_text_result 是获取某个结果。
在自动文本阅读器中,我们也使用了get_text_result ,直接获取的分类的结果:
* 获取分类结果
get_text_result (TextResultID, 'class', Class)
但是,如果是手动文本阅读器,你使用 get_text_result (TextResultID, ‘class’, Class),就会报错!
这是因为手动文本阅读器得到是分割的结果不是分类的结果,具体我们可以看一下get_text_result的具体介绍。
get_text_result 是一个用于查询文本分割结果的操作符。它通过查询 find_text 返回的
TextResultID 中的 ResultName 控制结果。ResultName 的可能参数值取决于在
find_text 的文本分割过程中使用的文本模型。
Mode = ‘auto’ 和 Mode = ‘manual’ 时, get_text_result 获取的时不同的结果。(下面这段可以不看,知道原因即可!)
以下首先列出了在 Mode = ‘auto’ 的文本模型中的可能参数值,然后是 Mode = ‘manual’ 的文本模型中的参数值。
可以查询以下结果:
对于 Mode = ‘auto’ 的文本模型的文本分割结果:
对于每种极性,文本行都独立从上到下、从左到右排序。文本行内的字符从左到右排序。
- ‘num_lines’(行数):找到的行数。
- ‘num_classes’(类别数):为每个字符存储的最佳类别数。根据所使用分类器的类别数量,这个值可能小于在文本模型中设置的值,参见
set_text_model_param。- ‘class’(类别):所有分割字符的分类结果,使用对应文本模型中的 OCR 分类器。请注意,如果分类器使用拒绝类进行训练,
get_text_result将返回拒绝类的第二高置信度的字符的第二高结果。- [‘class’, n](类别 n):类似于 ‘class’,但返回第 (n+1) 高置信度的类别。例如,[‘class’, 0] 返回每个字符的最高置信度的类别。此外,与 ‘class’ 不同,如果包含在对应文本模型中的分类器使用拒绝类进行训练,可以返回拒绝类。
- [‘class_line’, LineIndex](行内类别):指定由 LineIndex 指定的文本行内字符的分类结果,使用对应文本模型中的 OCR 分类器。例如,[‘class_line’, 0]
返回第一行内的字符类别。请注意,如果分类器使用拒绝类进行训练,get_text_result
将返回拒绝类的第二高置信度的字符的第二高结果。- [‘class_line’, LineIndex, n](行内类别 n):类似于 [‘class_line’, LineIndex],但返回第 (n+1) 高置信度的类别。例如,[‘class_line’, LineIndex, 0] 返回
LineIndex 指定的文本行内每个字符的最高置信度的类别。此外,与 [‘class_line’, LineIndex]
不同,如果包含在对应文本模型中的分类器使用拒绝类进行训练,可以返回拒绝类。- [‘class_element’, Index](字符类别):字符在位置 Index 处的分类结果,使用对应文本模型中的 OCR 分类器。例如 [‘class_element’, 0] 返回第一个字符的 ‘num_classes’ 个最佳类别(按置信度排序)。
- ‘confidence’(置信度):返回所有分割字符的类别的置信度,参见 ‘class’。
- [‘confidence’, n](置信度 n):返回第 (n+1) 高置信度的类别的置信度,参见 [‘class’, n]。
- [‘confidence_line’, LineIndex](行内置信度):返回指定由 LineIndex 指定的文本行内所有字符的类别的置信度,参见 [‘class_line’, LineIndex]。
- [‘confidence_line’, LineIndex, n](行内置信度 n):返回指定由 LineIndex 指定的文本行内所有字符的第 (n+1) 高置信度的类别的置信度,参见 [‘class_line’, LineIndex, n]。
- [‘confidence_element’, Index](字符置信度):返回与位置 Index 的字符的类别相对应的置信度,参见 [‘class_element’, Index]。
- ‘polarity’(极性):返回所有分割字符的极性。
- [‘polarity_line’, LineIndex](行内极性):返回指定由 LineIndex 指定的文本行内的字符的极性。例如,[‘polarity_line’, 0] 返回第一行内的极性。
- [‘polarity_element’, Index](字符极性):返回在位置 Index 处的字符的极性。例如 [‘polarity_char’, 0] 返回第一个字符的极性。
对于 Mode = ‘manual’ 的文本模型的文本分割结果:
- ‘manual_num_lines’(行数):找到的行数。
- 如果为创建 TextResultID 的文本模型激活了 ‘manual_persistence’,则可以查询以下额外的值:
- ‘manual_thresholds’(阈值):用于分割的阈值。
请注意,这些参数允许你查询文本分割结果的各个方面,包括字符分类、置信度、极性等。根据你的应用需求,你可以选择查询适合你的结果。
也就是,在手动模式下,get_text_object 只能获取到两种结果:
‘manual_num_lines’(行数):找到的行数。
‘manual_thresholds’(阈值):用于分割的阈值。
所以在手动模式下,是无法获取到分类的结果的!
do_ocr_multi_class_mlp 分类结果的获取
那真正获取到分类结果,我需要通过函数:
do_ocr_multi_class_mlp (Characters, img, OcrHandle, SymbolNames, Confidences)
参数介绍:
1 Characters,是通过get_text_object 获取到的分割区域,
2 img 是识别的图片。
3 OcrHandle 是读取halcon提供的分类器时返回的句柄。
4 SymbolNames 就是分类的结果
5 Confidences 是每个字符对应的置信度!
这里一个问题要注意,img 这个图片必须是白底黑字的图片,你可能会说我不是已经设置过极性了啊!
set_text_model_param (TextModel, ‘manual_polarity’, ‘light_on_dark’) 已经告诉他是黑底白字啊!
不行的,因为这是分割参数,和识别无关了,识别就必须是白底黑字!
如果你的图片是’light_on_dark’,你们请使用 invert_image (Image, TmpInverted),将图片进行反转再传给
do_ocr_multi_class_mlp 进行识别!
阶段小结:
通过这些参数,发现只有一个参数是来自,手动文本阅读器,就是 Characters :分割区域。
所以识别和分割时完全分开的! 我们也可以通过其他的方式,比如blob分析,图像滤波,形态学等操作获取到字符的分割区域

然后直接进行识别!
另一个识别函数 do_ocr_word_mlp
函数参数解读:
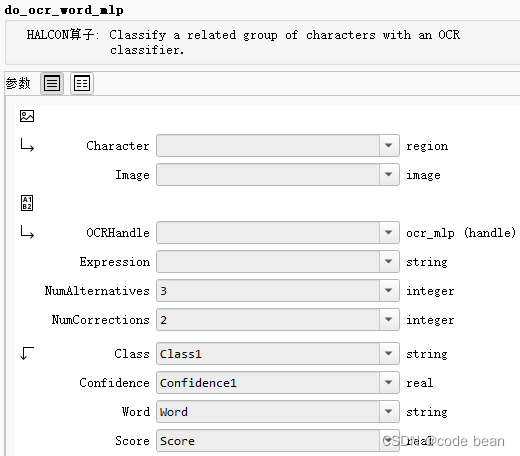
参数介绍:
1 Characters,是通过get_text_object 获取到的分割区域,
2 Image 是识别的图片。
3 OcrHandle 是读取halcon提供的分类器时返回的句柄。
4 Expression 预设匹配内容表达式,如:使用正则表达式
5 NumAlternatives 参数用于指定在执行 OCR 时考虑每个字符的备选类别数量。具体来说,它决定了在 do_ocr_word_mlp 操作中执行单词校正时,每个字符的备选类别数量。
当 do_ocr_word_mlp 无法通过原始分类结果生成与给定表达式匹配的单词时,它会考虑使用备选类别来进行校正。备选类别是按照置信度排名的备选字符分类结果。
NumAlternatives 参数控制了要考虑多少个备选类别。更具体地说,对于每个字符,DoOcrWordMlp 将考虑排名前 NumAlternatives 的备选类别。这意味着它将尝试将每个字符的分类结果更正为这些备选类别之一,以生成与表达式( Expression )匹配的单词。
6 NumCorrections 参数用于指定在执行 OCR 时最多允许的字符校正数量。具体来说,它决定了在 DoOcrWordMlp 操作中,如果生成的单词与给定的表达式不匹配,允许对多少个字符进行校正。NumCorrections 参数限制了在校正过程中允许的最大校正数量。如果 NumCorrections 设置为2,那么在校正单词时,最多允许对两个字符进行校正。
7 Class 就是分类的结果放到一个字符串数组
8 Confidences 是每个字符对应的置信度!
9 Word 字符串结果,不是数组的形式,结果的另一种展现形式
9 Score 用于衡量校正后的单词与未校正的分类结果之间的相似性。它是一个度量值,表示校正的质量,可以帮助您了解校正过程的效果。
Score 的取值范围通常在0.0到1.0之间,其中:
- 0.0 表示未进行任何校正,校正后的单词与未校正的分类结果完全不匹配。
- 1.0 表示校正后的单词与未校正的分类结果完全匹配,没有进行任何校正。
Score的计算方式通常考虑以下因素: - 校正的字符数量:校正了更多的字符可能会降低
Score。 - 放弃的备选类别数量:如果在校正过程中放弃了多个备选类别以使单词匹配表达式,也可能会降低
Score。
从参数数量上看,do_ocr_word_mlp 比 do_ocr_multi_class_mlp 复杂很多。
从一个叫 word, 一个叫 multi_class 就可以看出来一些问题。do_ocr_word_mlp 是对一组相关字符进行分类的操作符。
与 do_ocr_multi_class_mlp 不同,do_ocr_word_mlp 将字符组视为一个实体,通过连接每个字符区域的类别名称来生成一个单词。这允许通过指定描述期望单词的表达式来在文本级别上限制允许的分类结果。
那么整个函数的关键在于参数, Expression!利用好这个参数,能帮我们提高识别的准确度!举个例子:
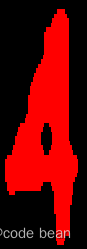
这个图片其实是4,但是识别过程中有时会识别成A,那此时 Expression 就能发挥作用了!
这是halcon自带的一个例子:
* Process Date Text
sort_region (CharactersDate, SortedDate, 'character', 'true', 'row')
* Classify the data string without restriction (for comparison)
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '.*', 5, 5, Class, Confidence, OriginalDateText, DateScore)
* Classify the data string using a regular expression
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', 10, 5, Class, Confidence, DateText, DateScore)
意再对比使用正则约束和不使用正则约束的区别!
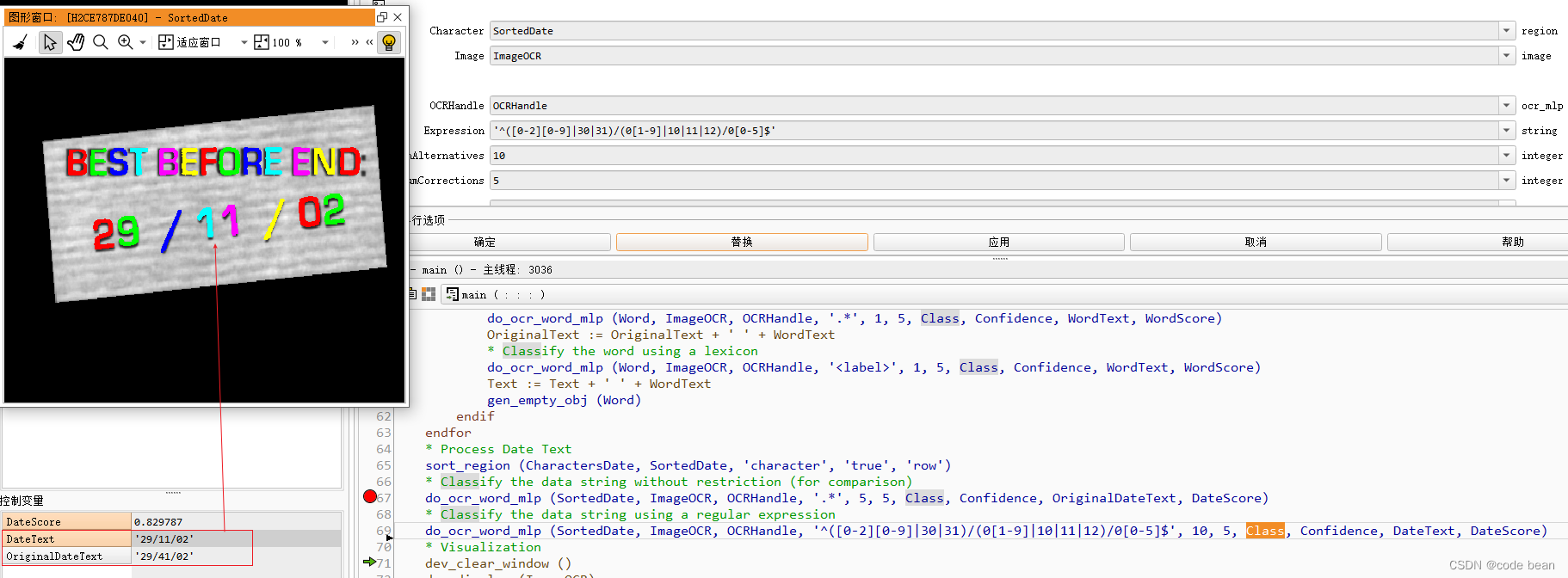
这个例子,表示如果使用正则 “ .* ” 的时候(就是没有约束匹配任何字符),原本的11被识别为了41,此时DataScore分数是满分1分。
如果使用正则 ‘^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$’ 识别出了正确结果。此时DataScore分数是0.829分。
这就是说正则有一定的纠错能力。
但是这个是有一个前提的:
正确的结果确实在识别的备选方案之中,比如这里如果1就不在halcon识别结果的备选方案中,那么正则就不会纠错,而且此时的DataScore会等于0,因为正则匹配的结果和识别的结果不一致。
还需要注意的是:
do_ocr_word_mlp (SortedDate, ImageOCR, OCRHandle, '^([0-2][0-9]|30|31)/(0[1-9]|10|11|12)/0[0-5]$', 10, 5, Class, Confidence, DateText, DateScore)
Class,中输出的是没有经过纠正的字符数组,而DateText中输出的是经过正则纠正的字符串。
我遇到的一个例子:

这个区域就被识别成了7,而我通过正则想将其纠正成1,但是根本没有作用,打分始终为0.
这其 就说明 1 根本就不在备选方案里面!(作为人的直觉1应该在备选方案啊!但是halcon识别结果里没有,我当时错还以为正则无效,其实就是不在备选方案)
do_ocr_single_class_mlp
do_ocr_multi_class_mlp 我们之前已经讲过了
do_ocr_single_class_mlp 和 do_ocr_multi_class_mlp 对比
很好理解:
do_ocr_single_class_mlp 一次识别一个区域 (一个区域对应一个字符)
do_ocr_multi_class_mlp 一次性识别多个区域(一个区域对应一个字符)
sort_region (RegionTrans, SortedRegions1, 'first_point', 'true', 'column')
for i := 1 to Number by 1
select_obj (SortedRegions, ObjectSelected, i)
do_ocr_single_class_mlp (ObjectSelected, Image, OCRHandle, 1, Class, Confidence)
* 显示相应的识别内容在区域上方
disp_message (WindowHandle, Class, 'image', MeanRow-10, Column[i-1]-10, 'red', 'true')
endfor
这里的排序,是为了识别的类容和识别的区域,是按指定的顺序(如从左到右)一一对应的。
有时,我们可能需要一个一个区域的处理(比如需要额外处理每个字符瑕疵),就可以使用do_ocr_single_class_mlp 。
这里,可能会有同学问题个问题,为啥之前都没看到排序这个步骤,这是应为自动和手动阅读器,帮我们完成的排序,
所有,如果是我们自己分割,需要自己完成这个排序。
OCR的识别过程总结
那整个OCR的识别过程就是:
1 获取到训练好的OCR识别句柄
2 将字符分割到单个的区域中
3 调用相应的方式识别。
1 获取到训练好的OCR识别句柄
我们可以通过 create_text_model_reader ('auto', 'Document_Rej.omc', OCRHandle)的方式获取到(这是自动阅读器的方式)
或者直接通过函数read_ocr_class_mlp 读取:read_ocr_class_mlp ('DotPrint_0-9A-Z_NoRej.omc', OCRHandle)
2 将字符分割到单个的区域中
一是,通过使用create_text_model_reader ('manual', [], TextModel) 得到一个分割的句柄,设置相应的参数,对字符图片进行的自动分割。
二是,通过blob分析,图像滤波,形态学操作,对字符图片进行分割。
分割,其实是整个OCR识别的关键!
3 调用相应的方式识别
目前介绍了三种方式:
- do_ocr_multi_class_mlp
- do_ocr_single_class_mlp
- do_ocr_word_mlp
使用心得总结
手动文本阅读器和自动文本阅读器的好处在于,可以将识别的过程标准化,我们只需要配置一些参数就OK了。
但是会有一些限制:
1 要求图片比较清晰
2 子母大小间隔都差不多,最好不含有一些特殊字符。
 ![在这里插入图片描述]
![在这里插入图片描述]
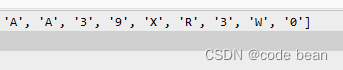
比如这里,就把3-识别成了X。(就是因为两个区域没分开导致的)
还有,这里两个A挨得很近,图像处理的时候,要注意得到的区域是否将其分割成了两个区域。
如果区域连接到了一起,注意要调整参数了
我使用下来的感觉是:自己通过blob分析,图像滤波,形态学操作,对字符图片进行分割。然后使用
支持正则的do_ocr_word_mlp进行识别,我愿称之为最强组合。普适性还是更好,识别更为准确,适合更为苛刻的识别需求。
预训练字符库的选择
预训练字符库就是.omc的文件,可以在安装HALCON的文件夹的子目录ocr中访问它们。预训练字体是使用在亮背景下的暗字符进行训练的。这就是为啥
- do_ocr_multi_class_mlp
- do_ocr_single_class_mlp
- do_ocr_word_mlp
都需图片输入必须是白底黑字的原因。
NoRej和 Rej
所有预训练的OCR字体都有两个版本。以_NoRej结尾的字体名称具有正则化权重但没有拒绝类,以_Rej结尾的字体名称具有正则化权重及拒绝类。由于正则化,预训练的OCR字体提供了更有意义的置信度。使用拒绝类的字体,可以区分字符与杂乱背景。带有拒绝类的字体返回ASCII Code 26。
如果出现:字符串包含数字 “\032”(也可以显示为 “\0x1A”),表示该区域已分类为拒绝类,也就是表示不判断了,拒绝给出判断。
OCR字体的命名法
- 0-9:OCR字体包含数字0到9。
- A-Z:OCR字体包含大写字符A到Z.
- +:OCR字体包含特殊字符。特殊字符列表与单个OCR字体略有不同。
- _NoRej:OCR字体没有拒绝类。
- _Rej:OCR字体有拒绝类。
以下列出,halcon所有的预训练字符库
"Document_A-Z+_Rej.omc",
"Document_NoRej.omc",
"Document_Rej.omc",
"DotPrint_0-9_NoRej.omc",
"DotPrint_0-9_Rej.omc",
"DotPrint_0-9+_NoRej.omc",
"DotPrint_0-9+_Rej.omc",
"DotPrint_0-9A-Z_NoRej.omc",
"DotPrint_0-9A-Z_Rej.omc",
"DotPrint_A-Z+_NoRej.omc",
"DotPrint_A-Z+_Rej.omc",
"DotPrint_NoRej.omc",
"DotPrint_Rej.omc",
"HandWritten_0-9_NoRej.omc",
"HandWritten_0-9_Rej.omc",
"Industrial_0-9_NoRej.omc",
"Industrial_0-9_Rej.omc",
"Industrial_0-9+_NoRej.omc",
"Industrial_0-9+_Rej.omc",
"Industrial_0-9A-Z_NoRej.omc",
"Industrial_0-9A-Z_Rej.omc",
"Industrial_A-Z+_NoRej.omc",
"Industrial_A-Z+_Rej.omc",
"Industrial_NoRej.omc",
"Industrial_Rej.omc",
"OCRA_0-9_NoRej.omc",
"OCRA_0-9_Rej.omc",
"OCRA_0-9A-Z_NoRej.omc",
"OCRA_0-9A-Z_Rej.omc",
"OCRA_A-Z+_NoRej.omc",
"OCRA_A-Z+_Rej.omc",
"OCRA_NoRej.omc",
"OCRA_Rej.omc",
"OCRB_0-9_NoRej.omc",
"OCRB_0-9_Rej.omc",
"OCRB_0-9A-Z_NoRej.omc",
"OCRB_0-9A-Z_Rej.omc",
"OCRB_A-Z+_NoRej.omc",
"OCRB_A-Z+_Rej.omc",
"OCRB_NoRej.omc",
"OCRB_passport_NoRej.omc",
"OCRB_passport_Rej.omc",
"OCRB_Rej.omc",
"Pharma_0-9_NoRej.omc",
"Pharma_0-9_Rej.omc"
Document
’Document’可用于读取以Arial,Courier或Times New Roman等字体打印的字符。这些是用于打印文档或字母的典型字体。请注意,无法区分字体Arial的字符I和l。这意味着l可能被误认为是I,反之亦然。
可用的特殊字符:- = + < > . # $ % & ( ) @ * e £ ¥
DotPrint
有的点式打印机还有喷墨机,打印出的效果,字符是小点组成。它不包含小写字符。
可用的特殊字符:- / . * :

Industrial
‘Industrial’可用于读取以Arial,OCR-B或其他sans-serif字体等打印的字符。例如,这些字体通常用于打印标签。
可用的特殊字符:- / + . $ % * e £
Industrial翻译为工业,我发现这个字符集,在识别I这个子母的时候更加准确!
但是,貌似并不能识别到横杠。(可能是我使用了字符和数字的库,如果是单个数字库,也许就能识别了"Industrial_0-9+_Rej.omc" 因为如果是字符和数字的库,就没有带+号的了, 后续有空再求证吧!)
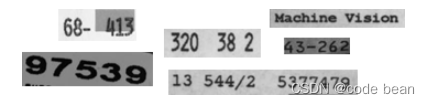
HandWritten
顾名思义,这个就是识别手写的字符,目前仅仅支持数字的手写。

OCR-A
‘OCR-A’可用于读取以字体OCR-A打印的字符。
可用的特殊字符: - ? ! / {} = + < > . # $ % & ( ) @ * e £ ¥

OCR-B
‘OCR-B’可用于读取以字体OCR-B打印的字符。
可用的特殊字符:- ? ! / {} = + < > . # $ % & ( ) @ * e £ ¥

Pharma
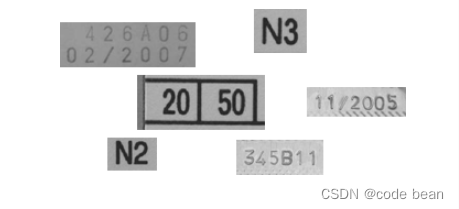
‘Pharma’可用于读取以Arial,OCR-B等字体打印的字符,以及制药行业通常使用的其它字体(见图18.18)。此OCR字体不包含小写字符。
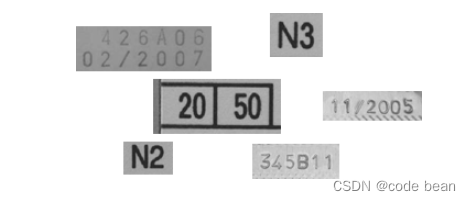
SEMI
‘SEMI’可用于读取以SEMI字体打印的字符,该字体由易于彼此区分的字符组成。它有一组有限的字符,可以在图18.19中看到。此OCR字体不包含小写字符。
可用的特殊字符: - .

Universal
‘Universal’可用于读取各种不同的字符。这种基于CNN训练的字体的基于 ‘’Document’,“DotPrint”,“SEMI”和“Industrial’”等字符。
可用的特殊字符:- / = + : < > . # $ % & ( ) @ * e £ ¥
如果这些预训练的字符库都无法解决你现有的识别问题,那么你就需要训练自己的字符库了!关注一波我们下一篇见
参考文章
预训练字符库的选择主要参考Mr.Devin的文章:
https://blog.csdn.net/IntegralforLove/article/details/83756956
Mr.Devin 真乃神人也~~~