这篇文章主要是介绍下我经历的一些比较难已提取OCR部分的图片,从而介绍下一些特别的处理方式。
第一种:差分高斯diff_of_gauss(近似拉普拉斯高斯)
原图如下:一般的方法基本提取不出来相应的字符。

那我们可以通过差分高斯这个算子直接得出很好的效果图,代码以及效果图如下:
read_image (Image, 'C:/Users/Administrator/Desktop/3.bmp')
rgb1_to_gray (Image, GrayImage)
*差分高斯
diff_of_gauss (GrayImage, DiffOfGauss, 3, 1.6)
threshold (DiffOfGauss, Regions, 2, 12)

这个效果可以直接进行处理,参照我之前的处理OCR的程序,直接就可以得出结果了,这里我就不再写了。
第二种:环形的字符,主要的思路就是通过极坐标转换,将环形部分拉直,剩下的就是正常的字符读取了。
原图:

read_image (Image, 'C:/Users/Administrator/Desktop/环形字符.png')
rgb1_to_gray (Image, GrayImage)
get_image_size (GrayImage, Width, Height)
emphasize (GrayImage, ImageEmphasize, Width, Height, 1)
threshold (ImageEmphasize, Regions, 0, 21)
connection (Regions, ConnectedRegions)
select_shape_std (ConnectedRegions, SelectedRegions, 'max_area', 70)
fill_up (SelectedRegions, RegionFillUp)
*分别两次膨胀
dilation_circle (RegionFillUp, RegionDilation, 20)
dilation_circle (RegionFillUp, RegionDilation1, 70)
*这里是求出两个膨胀区域的最小外接圆的圆心和半径,为之后的极坐标转换做准备
smallest_circle (RegionDilation, InnerRow, InnerCol, InnerRadius)
smallest_circle (RegionDilation1, OuterRow, OuterCol, OuterRadius)
*求出两个膨胀区域的差异部分,就是求出一个字体圆环部分
difference (RegionDilation1, RegionDilation, RegionDifference)
reduce_domain (ImageEmphasize, RegionDifference, ImageReduced)
*这里就是极坐标转换的算子了,就是将环形部分拉直,方便读取OCR
polar_trans_image_ext (ImageReduced, PolarTransImage, OuterRow, OuterCol, rad(-30), rad(-120), InnerRadius+16, OuterRadius, Width, Height/8, 'nearest_neighbor')
mirror_image (PolarTransImage, ImageMirror, 'row')
gray_range_rect (ImageMirror, ImageResult, 7, 7)
binary_threshold (ImageResult, Region, 'max_separability', 'light', UsedThreshold)
connection (Region, ConnectedRegions1)
select_shape (ConnectedRegions1, SelectedRegions1, ['height','area'], 'and', [54.14,912.03], [100,10000])
partition_rectangle (SelectedRegions1, Partitioned, 40, 70)
sort_region (Partitioned, SortedRegions, 'character', 'true', 'row')
invert_image (ImageResult, ImageInvert)
read_ocr_class_mlp ('Industrial_0-9A-Z_NoRej.omc', OCRHandle)
do_ocr_multi_class_mlp (SortedRegions, ImageInvert, OCRHandle, Class, Confidence)
dev_display (Image)
set_tposition (3600, 61, 63)
write_string (3600, Class)
字体圆环部分效果图:

环形字体拉直效果图:
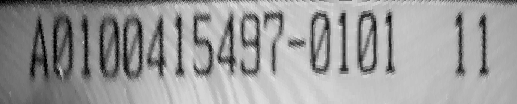
最终结果图:

一般字体所处的圆环部分,两次形态学处理再加一次difference,可以直接得出来,这种套路方法一般也应在找边缘的地方。正常的处理这种圆环中读取OCR,主要就是polar_trans_image_ext这个算子,其他的都是一些预处理手段。
第三种斜体字处理
原图:
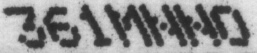
代码如下:
read_image (Image, 'C:/Users/Administrator/Desktop/斜体字练习.png')
dev_close_window()
get_image_size (Image, Width, Height)
dev_open_window (0, 0, Width, Height, 'black', WindowHandle)
dev_display (Image)
fast_threshold (Image, Region, 0, 128, 20)
*获取字体区域偏转的角度
text_line_slant (Region, Image, 45, -0.523599, 0.523599, SlantAngle)
*生成矩阵
hom_mat2d_identity (HomMat2DIdentity)
*这里是获取字体转正的矩阵,SlantAngle这个只是之前获取的字体斜了多少度,那么要转正的话就是纠正
*这个偏转角度,所以就要向相反方向偏正
hom_mat2d_slant (HomMat2DIdentity, -SlantAngle, 'x', 0, 0, HomMat2DSlant)
affine_trans_image (Image, ImageAffinTrans, HomMat2DSlant, 'nearest_neighbor', 'false')
fast_threshold (ImageAffinTrans, Region1, 0, 90, 20)
connection (Region1, ConnectedRegions1)
read_ocr_class_mlp ('DotPrint_0-9A-Z.omc', OCRHandle)
dilation_rectangle1 (Region1, RegionDilation, 2, 5)
connection (RegionDilation, ConnectedRegions)
partition_rectangle (ConnectedRegions, Partitioned, 32, 45)
intersection (Partitioned, ConnectedRegions1, RegionIntersection)
sort_region (RegionIntersection, SortedRegions, 'character', 'true', 'row')
do_ocr_multi_class_mlp (SortedRegions, ImageAffinTrans, OCRHandle, Class, Confidence)
转正后的图片:

处理得到的结果:

以上就是一些需要经过特殊处理之后才能够正常读取OCR的三种常见方法。当然还有一些更为难得项目,就比如那种刻字和本体颜色无差异的,而且字体是下沉或者凸起的,遇到这种的话首先先考虑通过低距离低角度打光突出边缘,如果光源搭设被限制住,那么就可以考虑光度立体这种方法来解决了(diff_of_gauss效果不行的情况下)。