文章目录
mplfinance是专用于金融数据的可视化分析模块,是基于matplotlib的实用模块程序。
一、从mpl-finance转到mplfinance
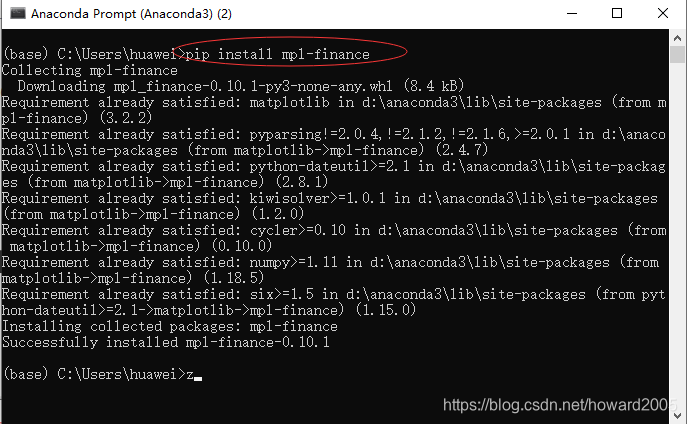
1、安装mpl-finance模块
pip install mpl-finance
2、导入mpl_finance模块出现警告
import mpl_finance as mpf
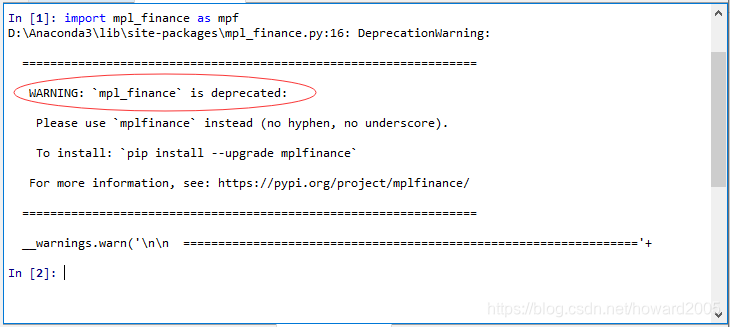
- 弹出警告信息:
mpl_finance被废弃了,请使用mplfinance(没有短横线,没有下划线)。
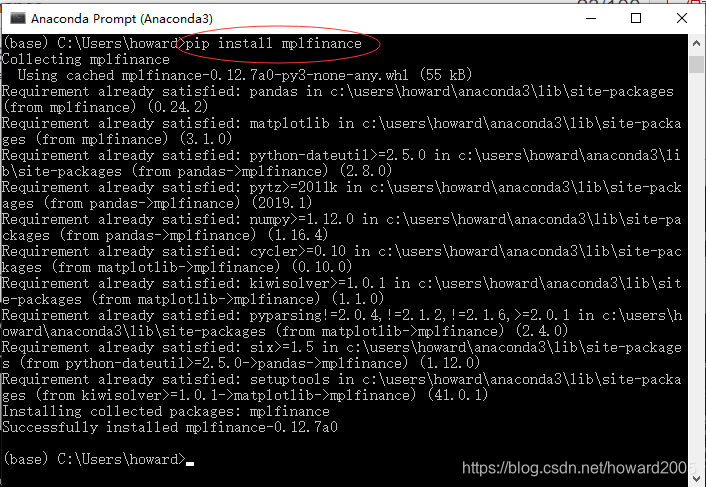
3、安装mplfinance模块
pip install mplfinance
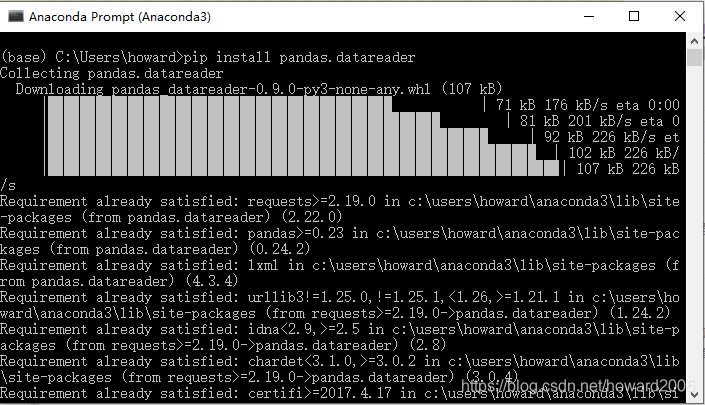
4、安装pandas.datareader模块
pip install pandas.datareader
扫描二维码关注公众号,回复:
12091825 查看本文章

二、获取在线数据,绘制K线图
1、利datareader读取在线股市数据
import pandas_datareader as pdr
dir(pdr)
结果:
['DataReader',
'Options',
'__all__',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'__version__',
'_utils',
'_version',
'av',
'bankofcanada',
'base',
'compat',
'data',
'econdb',
'enigma',
'eurostat',
'exceptions',
'famafrench',
'fred',
'get_components_yahoo',
'get_dailysummary_iex',
'get_data_alphavantage',
'get_data_enigma',
'get_data_famafrench',
'get_data_fred',
'get_data_moex',
'get_data_quandl',
'get_data_stooq',
'get_data_tiingo',
'get_data_yahoo',
'get_data_yahoo_actions',
'get_iex_book',
'get_iex_data_tiingo',
'get_iex_symbols',
'get_last_iex',
'get_markets_iex',
'get_nasdaq_symbols',
'get_quote_yahoo',
'get_recent_iex',
'get_records_iex',
'get_summary_iex',
'get_tops_iex',
'iex',
'io',
'moex',
'nasdaq_trader',
'naver',
'oecd',
'quandl',
'stooq',
'tiingo',
'yahoo']
import pandas_datareader as pdr
data = pdr.get_data_yahoo('INTC', '2020/9/1', '2020/10/1')
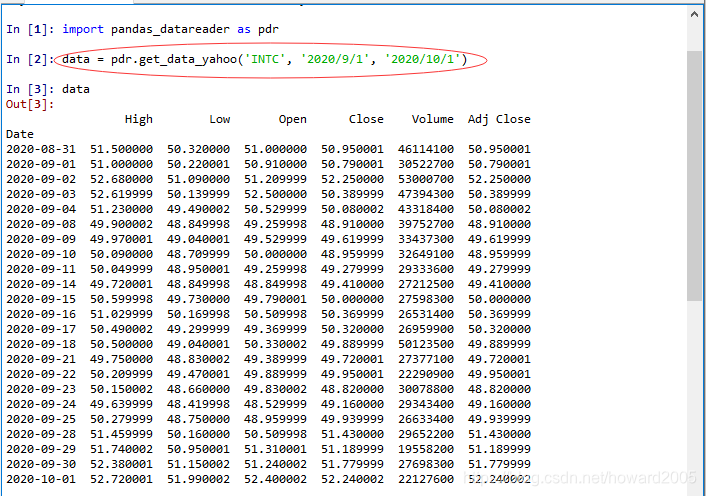
- 如果你要访问IBM公司的股票数据,将第一个参数改成‘IBM’即可
data = pdr.get_data_yahoo(‘IBM’, ‘2020/9/1’, ‘2020/10/1’)
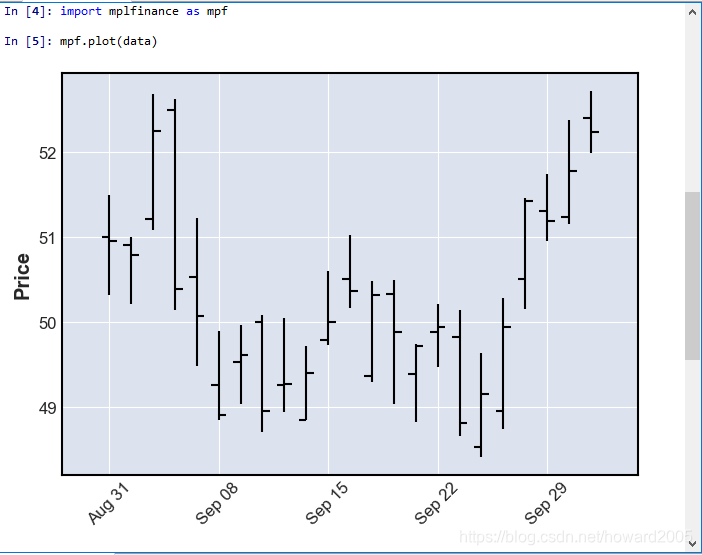
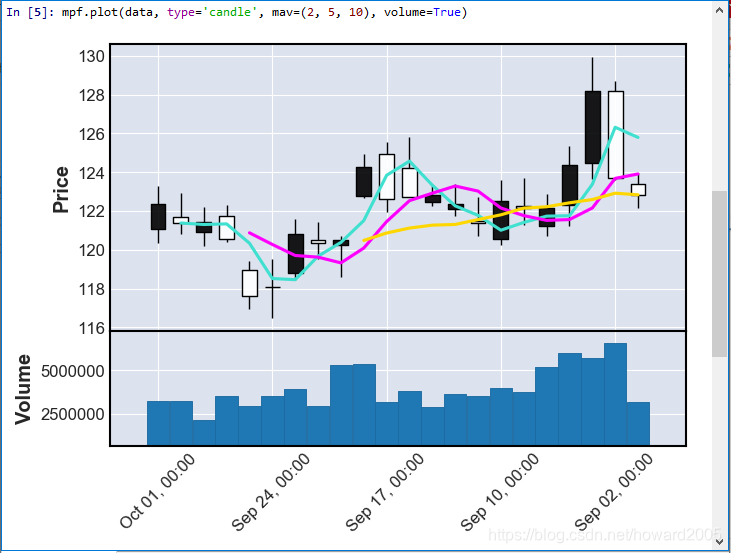
2、利用mplfinace的plot()绘制K线图
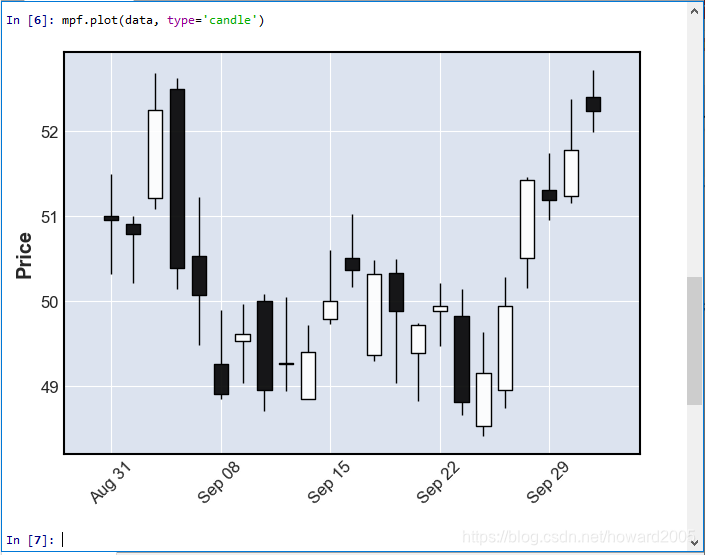
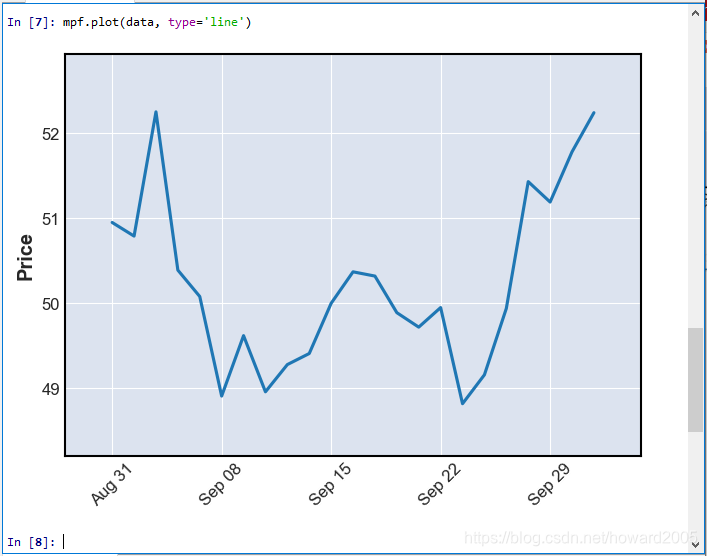
3、修改plot绘图类型
- 通过参数type修改绘图类型,默认是ohlc,可改成type=‘candle’ 或者 type=‘line’
4、增加绘制均线
- 关键字参数 mav=(2, 5, 10),多条均线使用元组,只绘制一条均线,可以mav=10
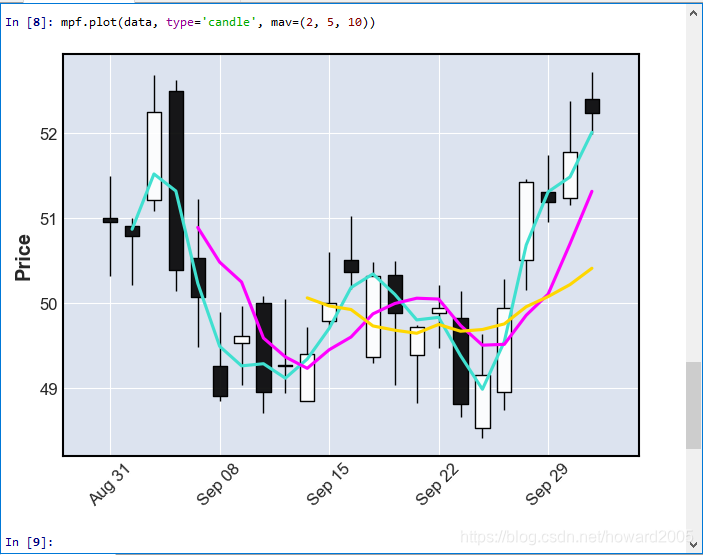
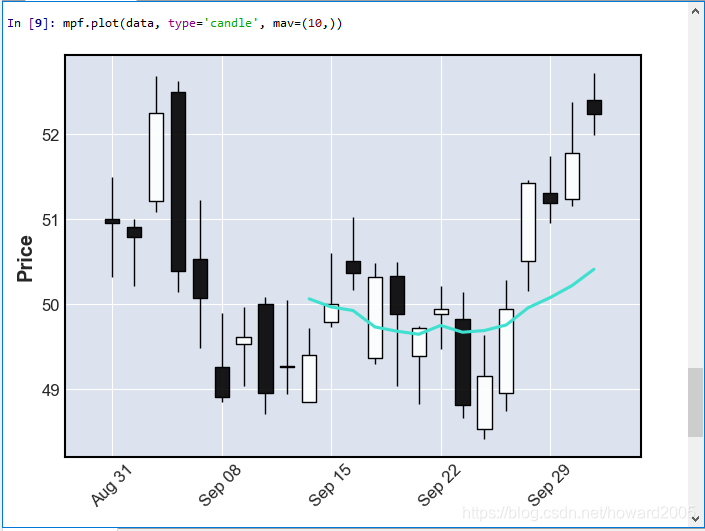
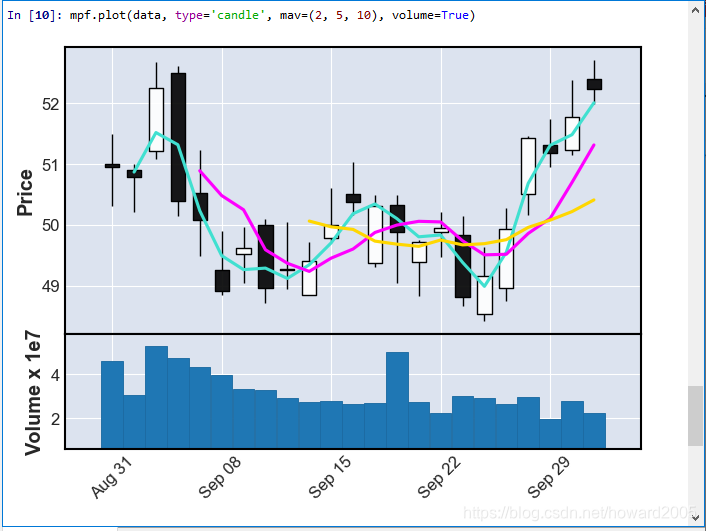
5、绘制成交量
- 关键字参数volume=True
6、自动剔除非交易日空白
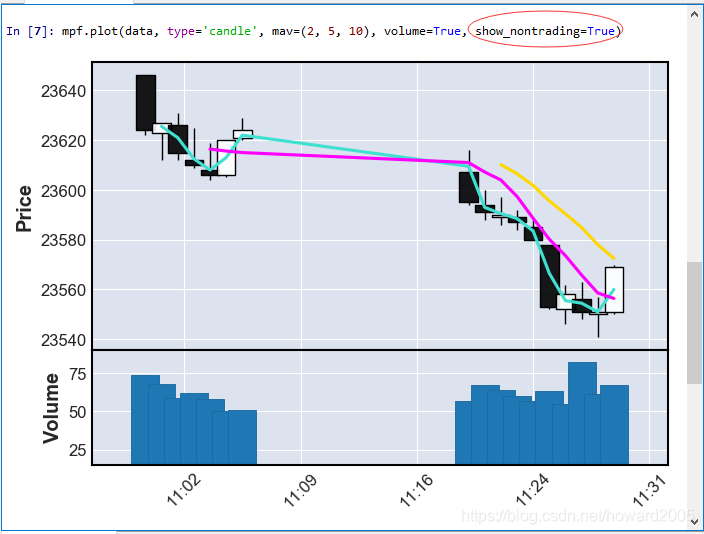
- 关键字参数show_nontrading,默认是False,设置为True,就可以看到停盘的时间段
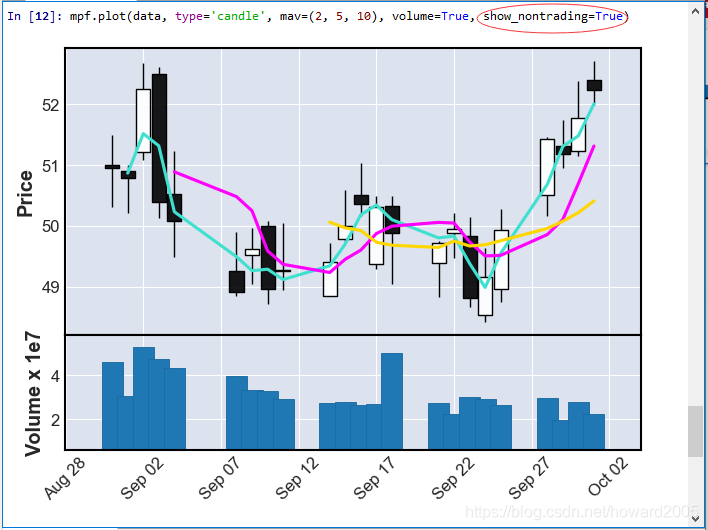
- 由于上述读取的数据没有停盘时间段,因此绘图没有什么不同。
7、绘制IBM公司股票2020年9月K线图
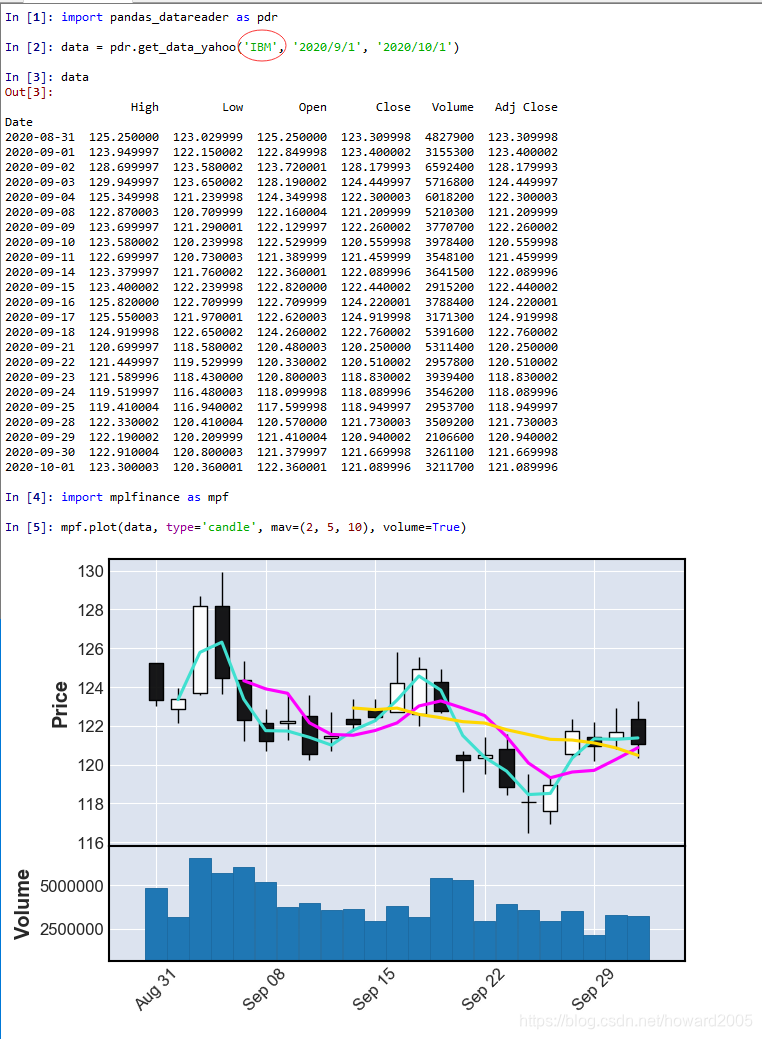
三、读取本地数据,绘制K线图
1、查看本地数据
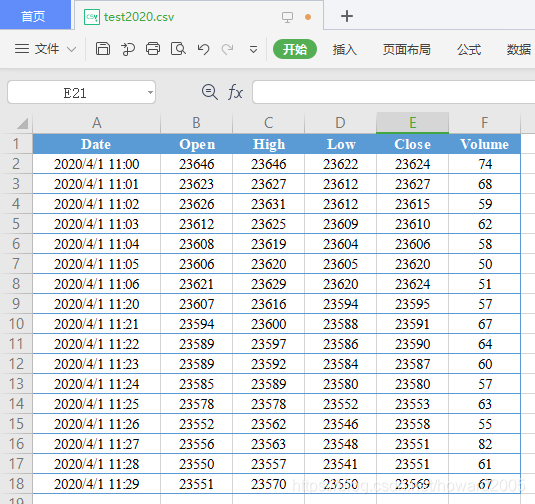
- 说明,plot()函数的参数data必须是pandas.DataFrame数据类型,对所包含的列也有要求,必须包含’Open’, ‘High’, ‘Low’ 和 ‘Close’ 数据(注意首字母必须大写),而且行索引必须是pandas.DatetimeIndex,行索引的名称必须是’Date‘,此外还有一列是’Volume’是可选项。
2、读取本地数据
import pandas as pd
import mplfinance as mpf
data = pd.read_csv('d:/python_work/202010/test2020.csv', index_col='Date')
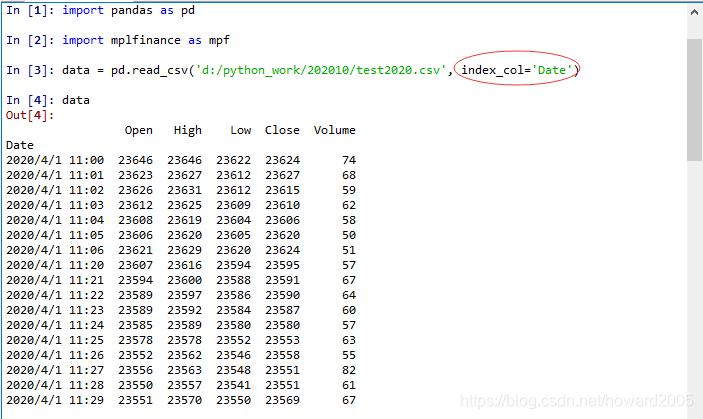
3、将索引类型更改为DatetimeIndex
data.index = pd.DatetimeIndex(data.index)

4、绘制K线图,剔除非交易时段
mpf.plot(data, type=‘candle’, mav=(2, 5, 10), volume=True)
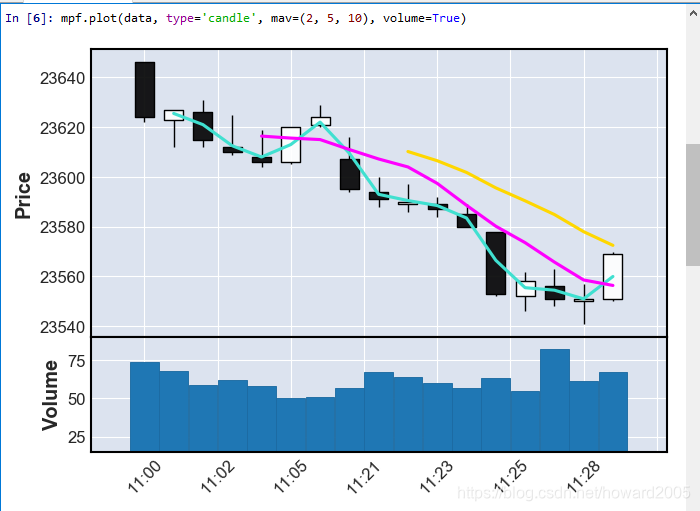
5、绘制K线图,显示非交易时段
mpf.plot(data, type=‘candle’, mav=(2, 5, 10), volume=True, show_nontrading=True)
四、设置plot()函数的addplot参数
1、读取IBM公司2020年10月1日到10月23日数据
import mplfinance as mpf
import pandas_datareader as pdr
data = pdr.get_data_yahoo('IBM', '2020/10/1', '2020/10/23')
data.head(5)
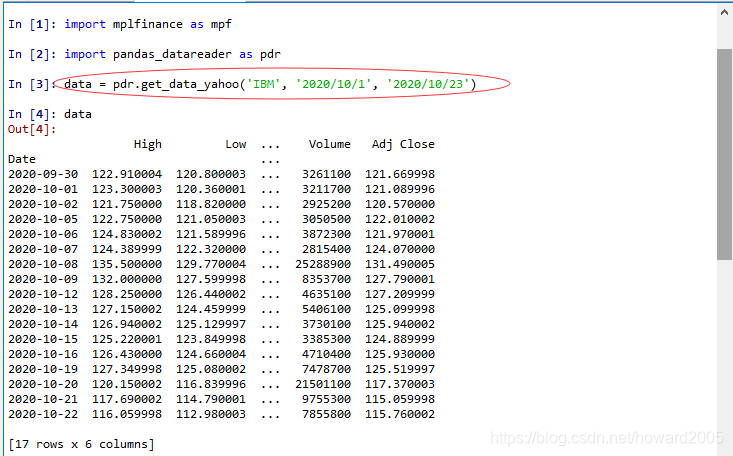
- 将数据导出到ibm_data.csv

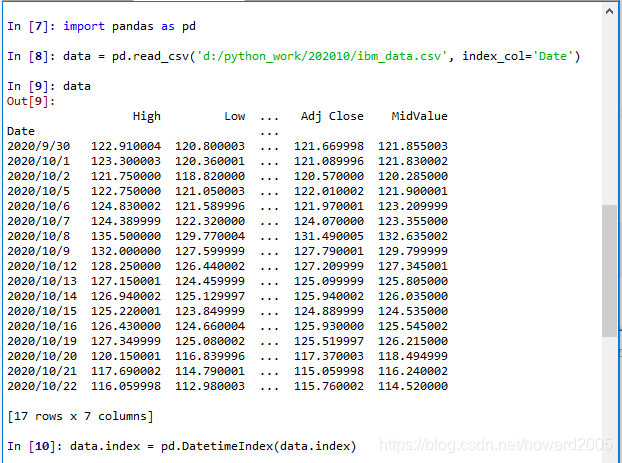
- 打开ibm_data.csv,添加一列MidValue

- 读取本地的数据文件 - ibm_data.csv
data = pd.read_csv('d:/python_work/202010/ibm_data.csv', index_col='Date')
data.index = pd.DatetimeIndex(data.index)
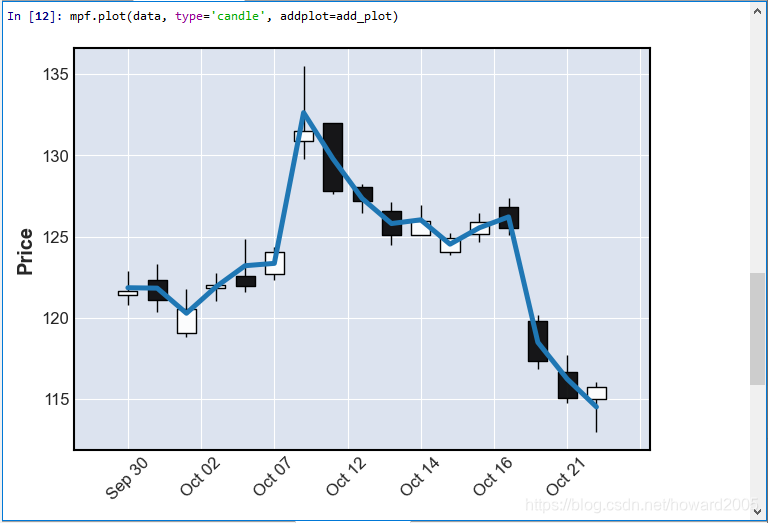
- 现在,我们要在K线图上添加刚才新增列 - MidValue
2、利用make_addplot()函数定义addplot参数值
add_plot = mpf.make_addplot(data['MidValue'])

3、绘制K线图,增加MidValue列对应的曲线
mpf.plot(data, type='candle', addplot=add_plot)
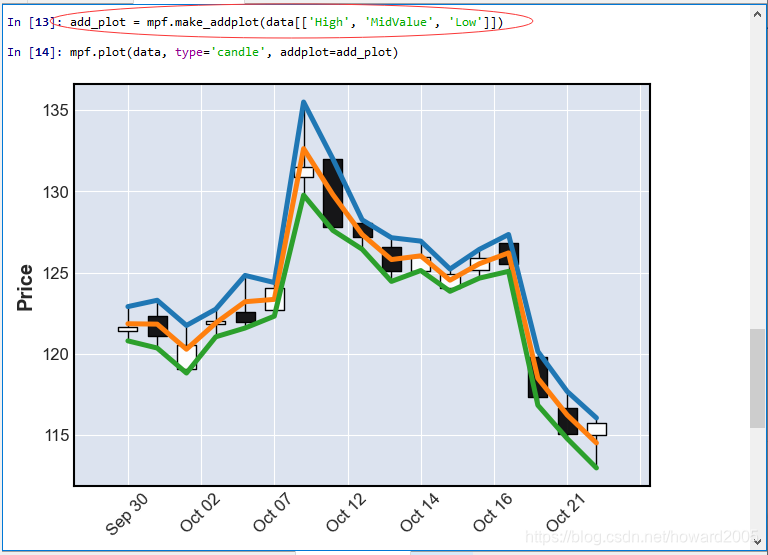
4、绘制K线图,添加High、MidValue和Low对应的曲线
add_plot = mpf.make_addplot(data[['High', 'MidValue', 'Low']])
mpf.plot(data, type='candle', addplot=add_plot)
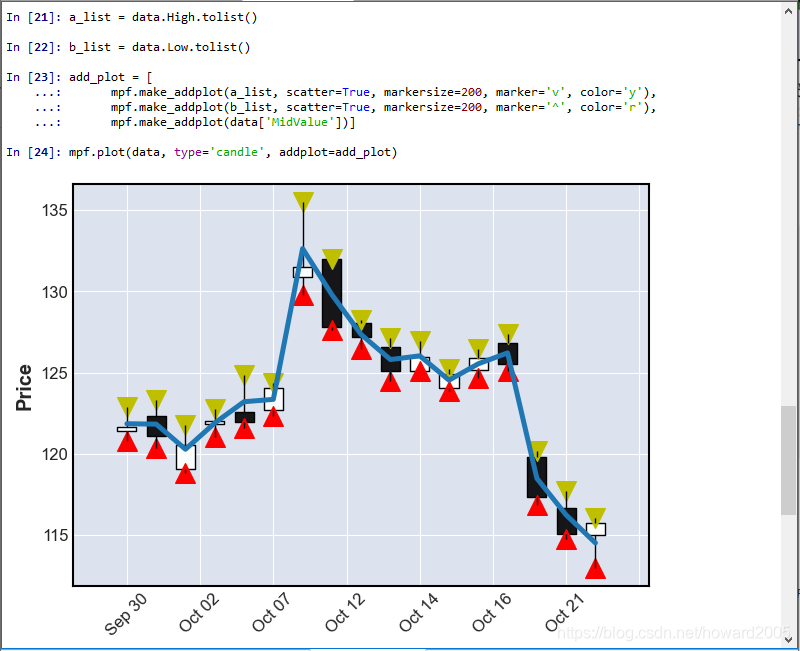
5、在结果图上添加标记
a_list = data.High.tolist()
b_list = data.Low.tolist()
add_plot = [
mpf.make_addplot(a_list, scatter=True, markersize=100, marker='v', color='y'),
mpf.make_addplot(b_list, scatter=True, markersize=100, marker='^', color='r'),
mpf.make_addplot(data['MidValue'])]
mpf.plot(data, type='candle', addplot=add_plot)
五、pandas_datareader补充说明
1、可访问的公司与机构
pandas_datareader是一个远程获取金融数据的Python工具,利用它可方便获得下面公司和机构的数据:
- 雅虎金融:Yahoo! Finance
- 谷歌金融:Google Finance
- Enigma公共数据搜索提供商: Enigma
- 圣路易斯联邦储备银行:St.Louis FED (FRED)
- 肯尼斯弗兰奇资料库:Kenneth French’s data library
- 世界银行:World Bank
- 经合组织:OECD
- 欧盟统计局:Eurostat
- 美国联邦政府管理离退休的组织:Thrift Savings Plan
- 纳斯达克交易符号定义:Nasdaq Trader symbol definitions
2、访问谷歌金融数据
- 访问IBM公司2020年9月份股票数据
- 绘制IBM公司2020年9月份股票K线图
- 访问IBM公司2020年1月1日到10月22日股票数据
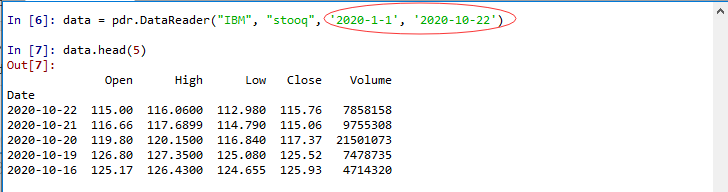
- 绘制IBM公司2020年1月1日到10月22日股票K线图
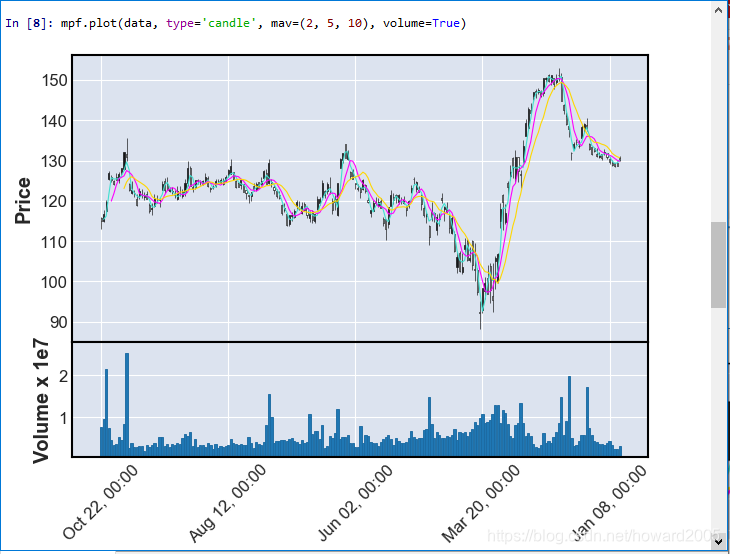
3、访问纳斯达克交易符号定义
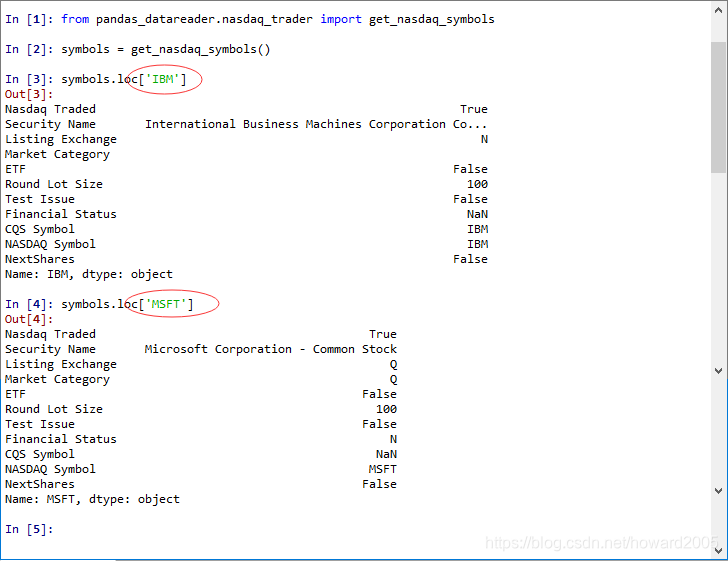
4、访问世界银行NY.GDP.PCAP.KD数据
- 获取美国、中国、日本最近二十年的NY.GDP.PCAP.KD数据
from pandas_datareader import wb
data = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'CN', 'JP'], start=2001, end=2020)
data
Out[3]:
NY.GDP.PCAP.KD
country year
China 2020 NaN
2019 8254.300930
2018 7806.953095
2017 7346.611355
2016 6907.962011
2015 6500.281937
2014 6103.590270
2013 5710.587873
2012 5325.160106
2011 4961.234689
2010 4550.453596
2009 4132.902312
2008 3796.633363
2007 3480.152725
2006 3062.534905
2005 2732.165880
2004 2467.132843
2003 2253.929689
2002 2061.162284
2001 1901.407630
Japan 2020 NaN
2019 49187.833090
2018 48766.133663
2017 48510.609409
2016 47403.046912
2015 47102.580878
2014 46484.155267
2013 46249.209589
2012 45276.874335
2011 44538.726191
2010 44507.676386
2009 42724.760370
2008 45165.787919
2007 45687.273815
2006 44995.494492
2005 44393.626384
2004 43671.679974
2003 42744.011285
2002 42190.804873
2001 42239.184926
United States 2020 NaN
2019 55670.235709
2018 54659.198268
2017 53382.764823
2016 52555.518032
2015 52116.738813
2014 51028.824895
2013 50171.237133
2012 49603.253474
2011 48866.053277
2010 48467.515777
2009 47648.813250
2008 49319.478865
2007 49856.281491
2006 49405.767296
2005 48499.812376
2004 47287.593772
2003 45980.514585
2002 45087.367279
2001 44728.597475
- 求三个国家数据的均值
data['NY.GDP.PCAP.KD'].groupby(level=0).mean()
Out[4]:
country
China 4702.903026
Japan 45359.972092
United States 49701.871926
Name: NY.GDP.PCAP.KD, dtype: float64
- 美国、中国、日本近二十年人均GDP对比图
from pandas_datareader import wb
dat = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'CN', 'JP'], start=2001, end=2020)
dat
Out[3]:
NY.GDP.PCAP.KD
country year
China 2020 NaN
2019 8254.300930
2018 7806.953095
2017 7346.611355
2016 6907.962011
2015 6500.281937
2014 6103.590270
2013 5710.587873
2012 5325.160106
2011 4961.234689
2010 4550.453596
2009 4132.902312
2008 3796.633363
2007 3480.152725
2006 3062.534905
2005 2732.165880
2004 2467.132843
2003 2253.929689
2002 2061.162284
2001 1901.407630
Japan 2020 NaN
2019 49187.833090
2018 48766.133663
2017 48510.609409
2016 47403.046912
2015 47102.580878
2014 46484.155267
2013 46249.209589
2012 45276.874335
2011 44538.726191
2010 44507.676386
2009 42724.760370
2008 45165.787919
2007 45687.273815
2006 44995.494492
2005 44393.626384
2004 43671.679974
2003 42744.011285
2002 42190.804873
2001 42239.184926
United States 2020 NaN
2019 55670.235709
2018 54659.198268
2017 53382.764823
2016 52555.518032
2015 52116.738813
2014 51028.824895
2013 50171.237133
2012 49603.253474
2011 48866.053277
2010 48467.515777
2009 47648.813250
2008 49319.478865
2007 49856.281491
2006 49405.767296
2005 48499.812376
2004 47287.593772
2003 45980.514585
2002 45087.367279
2001 44728.597475
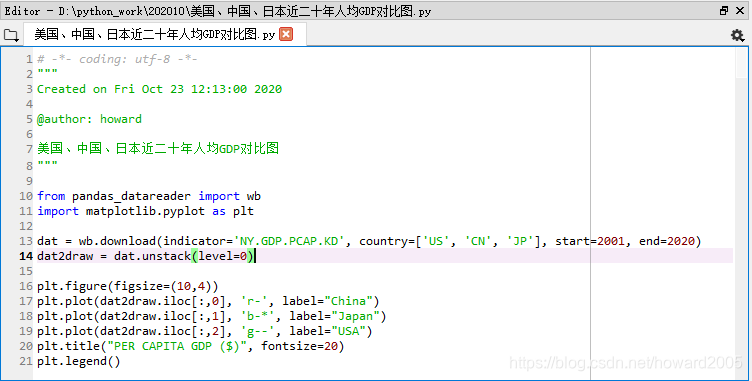
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 23 12:13:00 2020
@author: howard
美国、中国、日本近二十年人均GDP对比图
"""
from pandas_datareader import wb
import matplotlib.pyplot as plt
dat = wb.download(indicator='NY.GDP.PCAP.KD', country=['US', 'CN', 'JP'], start=2001, end=2020)
dat2draw = dat.unstack(level=0)
plt.figure(figsize=(10,4))
plt.plot(dat2draw.iloc[:,0], 'r-', label="China")
plt.plot(dat2draw.iloc[:,1], 'b-*', label="Japan")
plt.plot(dat2draw.iloc[:,2], 'g--', label="USA")
plt.title("PER CAPITA GDP ($)", fontsize=20)
plt.legend()
- 运行程序,查看结果
