这是一篇从采样方式去优化联邦学习模型的文章,有点难,看得云里雾里的…
要解决的问题
这篇文章主要解决的问题是由于不同节点的计算能力/通信能力不同,如果在进行采样的时候采到了这些节点,那么在这个节点上的很多数据都用不上,导致这些数据的信息被浪费掉。为了解决这个问题,论文采用了data offloading的方式将这些数据共享到其他节点上去,利用其他节点的更强大的计算能力/通信能力来将这些数据的信息利用起来
Data Offloading
数据分流(data offloading)这个概念出现在通信网络的场景中,是为了应对密集区域迅速增加的数据流量。智能数据/流量分流是从蜂窝网络到WiFi(如果可能也可以在相反方向上)的受控数据流量分流。在这个过程中用户不需要搜索适当的网络,也不需要输入用户证明(如口令)。举个例子,当智能手机从住宅或办公室移动穿过城市时,智能手机自动将数据流量切换给可用的WiFi热点
D2D Setting
该论文的方法是居于D2D(Device-to-Device)的,因此需要某两个节点直接相互信任,允许传输数据。我们用一个邻接矩阵来表示这个关系:
A ( t ) = [ A i , j ( t ) ] 1 ⩽ i , j ⩽ N A(t) = [A_{i,j}(t)]_{1\leqslant i,j \leqslant N} A(t)=[Ai,j(t)]1⩽i,j⩽N
其中 A i , j = 1 A_{i,j}=1 Ai,j=1表示节点 i , j i,j i,j之间是信任的, A i . j = 0 A_{i.j}=0 Ai.j=0表示节点 i , j i,j i,j之间是不信任的
Φ i , j ( t ) \Phi_{i,j}(t) Φi,j(t)表示节点 i , j i,j i,j之间data offloading的比率
Data Similarity Model
由于不同节点的数据可能有重合的部分,那么这些将这些数据进行data offloading将没什么特别的意义,因此我们需要定义数据的相似度,来避免传输那些“重合”的数据
相似度矩阵:
λ ( t ) = [ λ i , j ( t ) ] 1 ⩽ i , j ⩽ N , 其 中 0 ⩽ λ i , j ( t ) ⩽ 1 \lambda (t) = [\lambda_{i,j}(t)]_{1\leqslant i,j \leqslant N},其中0 \leqslant \lambda_{i,j}(t) \leqslant 1 λ(t)=[λi,j(t)]1⩽i,j⩽N,其中0⩽λi,j(t)⩽1
λ i , j ( t ) \lambda_{i,j}(t) λi,j(t)代表的是节点 i i i上的“相似数据”的百分比,“相似数据”的定义是在节点 j j j上至少有一个数据点与该数据“相似”,这个“相似”的定义为在数据的label的相同的情况下, ∣ ∣ x d i − x d j ∣ ∣ ||x_{d_i} - x_{d_j}|| ∣∣xdi−xdj∣∣小于一个给定的阀值
居于D2D和相似度矩阵,定义一个connectivity-similarity矩阵:
Λ ( t ) = λ ( t ) ⨀ A ( t ) \Lambda(t) = \lambda(t) \bigodot A(t) Λ(t)=λ(t)⨀A(t)
⨀ \bigodot ⨀表示Hadamard乘积
Similarity-aware D2D offloading
假设节点 i i i从节点 k k k中接受到的数据为 Φ k , j ( t ) D k ( t − 1 ) \Phi_{k,j}(t)D_k(t-1) Φk,j(t)Dk(t−1),则重合的数据的部分为 Φ k , j ( t ) D K ( t − 1 ) Λ k , j ( t − 1 ) \Phi_{k,j}(t)D_K(t-1)\Lambda_{k,j}(t-1) Φk,j(t)DK(t−1)Λk,j(t−1),非重合的数据为 Φ k , j ( t ) D K ( t − 1 ) ( 1 − Λ k , j ( t − 1 ) ) \Phi_{k,j}(t)D_K(t-1)(1-\Lambda_{k,j}(t-1)) Φk,j(t)DK(t−1)(1−Λk,j(t−1)),在经过一次data offloading之后,我们再去重新计算 Λ k , i ( t ) \Lambda_{k,i}(t) Λk,i(t)
Offloading-Aware Smart Device Sampling
接下来就是采样方式,我们根据参与联邦学习节点所组成的网络结构,假设 π i = [ D i ( 0 ) , P i ( 0 ) , p i ( 0 ) , θ i ( 0 ) ] \pi_i = [D_i(0),P_i(0),p_i(0),\theta_i(0)] πi=[Di(0),Pi(0),pi(0),θi(0)], A ~ = Λ ( 0 ) + I N \widetilde{A} = \Lambda(0) + I_N A =Λ(0)+IN
并且GCN的每一层输出如下:
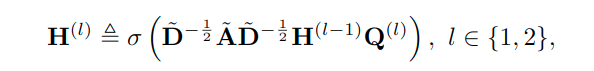
且令:
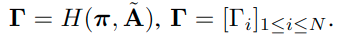
初始化一个集合S为采样集,则每一次我们都根据下式找出需要加入S的节点:
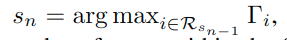
将它加入S中,直至达到需要采样的数量
感想
这篇论文着实有点难懂,后面还会继续仔细看看