关于K近邻详解与代码实现
本文根据 李航《统计学习方法》第三章和cs231n作业1 整理而来。
0 简介
K近邻法(KNN)是一种基本分类与回归方法。
K近邻法的三个基本要素:
①K值得选择
②距离度量
③分类决策规则
K近邻算法没有显示的学习过程
1 抽象表达
输入:
其中 为实例的特征向量, 为实例的类别,
输出:
实例x所属的类y
(1)根据给定的距离度量,在训练集 中找出与 最近邻的 个点,涵盖着 个点的 领域记作 。
(2)在 中根据分类决策规则决定 的类别 :
其中 为指示函数,即当 时 为1,否则 为0
2 模型
k近邻对应的模型实际上对应于特征空间的划分。模型由三个基本要素①K值得选择②距离度量③分类决策规则决定。
2.1 距离度量
特征空间中两个实例点的距离是两个实例点相似程度的体现。一般的距离是 距离。
令 , ,
则 的 距离定义为
当 时,称为曼哈顿距离,即
当 时,称为欧氏距离,即
当 时,称为切比雪夫距离,即 (可通过在二维平面的特例求极限推导出此公式)
2.2 K值得选择
K值得选择会对k近邻的结果产生重大的影响。
选择较小的K值,就相当于使整体的模型变得复杂,容易发生过拟合。
选择较大的K值,就相当于使整体的模型变得简单,使预测发生错误。
在应用中,k值一般取一个比较小的整数值,通常采用交叉验证法来选取最优的k值。
2.3 分类决策规则
k近邻法中的分类决策规则往往是多数表决,即由输入实例的k个邻近的训练实例中的多数类决定输入实例的类。
3 代码实现
k近邻代码实现包含的三个主要步骤:
① 读取训练数据,本次采用的数据集为CIFAR10数据集;
②分类器通过把每张测试图片与所有的训练图片集比较,并且转化为最相似的K个训练样本
③交叉验证,评估分类器的好坏
3.1 读取数据集
读取数据集,观察训练数据集和测试数据集的形状与数量:
# 加载原始的CIFAR-10 数据集的指定路径
cifar10_dir = 'cs231n/datasets/cifar-10-batches-py'
# 清空变量,防止多次加载引起内存泄漏
try:
del X_train, y_train
del X_test, y_test
print('之前加载的数据已清空!')
except:
pass
# 按照指定路径加载数据集,并读取到内存变量中
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# 为了便于检查,我们输出训练数据集和测试数据集的大小
print('Training data shape:', X_train.shape) # (50000, 32, 32, 3)
print('Training labels shape:', y_train.shape) # (50000,)
print('Test data shape:', X_test.shape) # (10000, 32, 32, 3)
print('Test labels shape:', y_test.shape) # (10000,)对数据集进行预处理,从50000个训练样本中选取前5000个,从10000个训练样本中选取前500个:
# 在本练习中,对数据进行子采样以实现更高效的代码执行
num_training = 5000
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
num_test = 500
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# 将图像数据重新整形为行
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1))
print(X_train.shape) # (5000, 3072)
print(X_test.shape) # (500, 3072)3.2 实现K近邻分类器
采用二重循环的方式计算测试集中图像与所有训练集图像的L2欧几里得距离。
def compute_distances_two_loops(self, X):
"""
输入:
- X: (测试集数,每张图像的总像素点数)---->(500, 3072)
- self.X_train: (训练集数,每张图像的总像素点数)---->(5000, 3072)
输出:
- dists: (测试集数,训练集数)---->(500, 5000)其中dists[i, j]表示测试集中的第i个样本与训练集中第j个样本之间的欧几里得距离
"""
num_test = X.shape[0] # 获取测试集数500
num_train = self.X_train.shape[0] # 获取训练集数5000
dists = np.zeros((num_test, num_train)) # 用0初始化距离矩阵
for i in range(num_test):
for j in range(num_train):
dists[i, j] = np.sqrt(np.sum(np.square(self.X_train[j,:] - X[i,:])))
return dists采用单循环(测试集)的方式计算测试集中图像与所有训练集图像的L2欧几里得距离。
def compute_distances_one_loop(self, X):
num_test = X.shape[0] # 获取测试集数500
num_train = self.X_train.shape[0] # 获取训练集数5000
dists = np.zeros((num_test, num_train)) # 用0初始化距离矩阵
# 采用广播的机制批量计算
for i in range(num_test):
dists[i, :] = np.sqrt(np.sum(np.square(self.X_train - X[i, :]), axis=1))
return dists采用向量的方式计算所有测试集与所有训练集图像的L2欧几里得距离。
def compute_distances_no_loops(self, X):
num_test = X.shape[0] # 获取测试集数500
num_train = self.X_train.shape[0] # 获取训练集数5000
dists = np.zeros((num_test, num_train)) # 用0初始化距离矩阵
# L2距离向量化实现
# np.multiply对应元素相乘;np.dot矩阵乘法
# keepdims=True 保持其本身的维度特性
# 平方差展开公式(X-Y)^2 = X^2+Y^2-2*X*Y
dists = np.multiply(np.dot(X, self.X_train.T), -2)
sq1 = np.sum(np.square(X), axis=1, keepdims=True)
sq2 = np.sum(np.square(self.X_train), axis=1)
dists = np.add(dists, sq1)
dists = np.add(dists, sq2)
dists = np.sqrt(dists)
return dists预测标签,给出测试集与训练集中的距离矩阵,预测每个测试集标签的值
def predict_labels(self, dists, k=1):
"""
输入:
- dists: (测试数据集,训练数据集)
- k: 预测k个最近的样本
输出:
- y: (测试数据集,)
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
closest_y = [] # 长度为k的列表,存储i测试点的k个最近邻居
# argsort返回的是从小到大的索引值
closest_y = self.y_train[np.argsort(dists[i])[:k]]
# 统计出现次数最多的标签对应的索引值即为预测的类别
y_pred[i] = np.argmax(np.bincount(closest_y))
return y_pred3.3 交叉验证
上面我们已经实现了K近邻分类器,现在我们使用交叉验证的方法找出最好的超参数的值。
num_folds = 5 # 使用5折交叉验证
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100]
X_train_folds = []
y_train_folds = []
# 把训练数据集分成不同的小份
X_train_folds = np.array_split(X_train, num_folds)
y_train_folds = np.array_split(y_train, num_folds)
k_to_accuracies = {}
# 执行K折交叉实现找到最好的值
classifier = KNearestNeighbor()
for k in k_choices:
accuracies = np.zeros(num_folds)
for fold in range(num_folds):
temp_X = X_train_folds[:]
temp_y = y_train_folds[:]
X_validata_fold = temp_X.pop(fold)
y_validate_fold = temp_y.pop(fold)
temp_X = np.array([y for x in temp_X for y in x])
temp_y = np.array([y for x in temp_y for y in x])
classifier.train(temp_X, temp_y)
y_test_pred = classifier.predict(X_validata_fold, k=k)
num_correct = np.sum(y_test_pred == y_validate_fold)
accuracy = float(num_correct) / num_test
accuracies[fold] = accuracy
k_to_accuracies[k] = accuracies
# 输出计算的精确度
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy))计算后发现图像为:
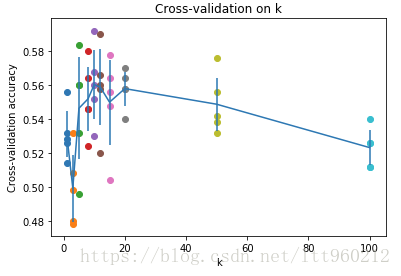
发现,当k=10,K近邻分类器精度最高。