原文链接:https://arxiv.org/pdf/1411.1784.pdf
简介
核心思想:在判别器与生成器的输入中加上标签等而外信息作为条件信息来约束生成器。

相比原始的GAN所生成的图片只能拟合到整个训练集X的数据分布,而无法控制具体生成其中某种标签的数据。但是如果加上了标签信息作为而外的信息输入,我们就能以此来对生成数据具体拟合范围进行约束,用不同的标签就能生成不同的数据。感性上来理解,判别器不仅要判断输入图片是否为真,还要判断输入图片与标签是否匹配,只不过两个任务由判别器一次完成罢了。相应的生成器不仅要生成与X相类似分布的数据,还要保证生成的数据要与输入标签匹配。
基础结构
由于本篇文章发布时间较早,WGAN,f-GAN等改进优化的方案还未出现,其仅是在原始GAN的上做了修改。主要优化流程如下:
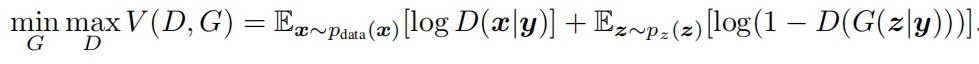
上式在乍看之下好像没什么问题,但是稍微细心些就会发现其实作者把后面那个D中的条件写漏了,如果按照其画出来的流程写全了的话:
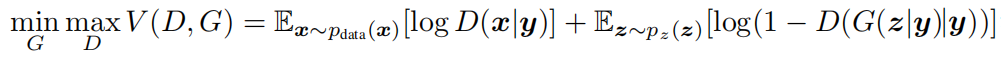
假设式子前半部分的y是源数据集中x对应的标签,那后半部分对应生成数据的y即对应输入噪声的y就应该是在所有标签中的随机采样。至于,如何然如何让模型接受条件y,此文采用了较为直接的方式:在输入后,将条件y处理为向量然后直接与原输入向量拼接后,一同进入模型。
应用创新
此篇文章突破了GAN的生成器只以随机分布作为输入的先例,引入更多样的输入数据来作为生成器的“原料”,就可以完从图片到标签的转换,或是更深远的从文字到图片,从图片到视频等,正真实现了从一种数据到另一种数据的生成转换。下面是文章对网络图片进行类别标注的结果展示,虽然和分类模型很像,但这可以理解为从图片到类别名称的转换:

代码和实践结果
import argparse
import os
import numpy as np
import math
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args()
print(opt)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.label_emb = nn.Embedding(opt.n_classes, opt.n_classes)
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim + opt.n_classes, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, noise, labels):
# Concatenate label embedding and image to produce input
gen_input = torch.cat((self.label_emb(labels), noise), -1)
img = self.model(gen_input)
img = img.view(img.size(0), *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.label_embedding = nn.Embedding(opt.n_classes, opt.n_classes)
self.model = nn.Sequential(
nn.Linear(opt.n_classes + int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 512),
nn.Dropout(0.4),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1),
)
def forward(self, img, labels):
# Concatenate label embedding and image to produce input
d_in = torch.cat((img.view(img.size(0), -1), self.label_embedding(labels)), -1)
validity = self.model(d_in)
return validity
# Loss functions
adversarial_loss = torch.nn.MSELoss()
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
adversarial_loss.cuda()
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
def sample_image(n_row, batches_done):
"""Saves a grid of generated digits ranging from 0 to n_classes"""
# Sample noise
z = Variable(FloatTensor(np.random.normal(0, 1, (n_row ** 2, opt.latent_dim))))
# Get labels ranging from 0 to n_classes for n rows
labels = np.array([num for _ in range(n_row) for num in range(n_row)])
labels = Variable(LongTensor(labels))
gen_imgs = generator(z, labels)
save_image(gen_imgs.data, "images/%d.png" % batches_done, nrow=n_row, normalize=True)
# ----------
# Training
# ----------
for epoch in range(opt.n_epochs):
for i, (imgs, labels) in enumerate(dataloader):
batch_size = imgs.shape[0]
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)
# Configure input
real_imgs = Variable(imgs.type(FloatTensor))
labels = Variable(labels.type(LongTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise and labels as generator input
z = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))
gen_labels = Variable(LongTensor(np.random.randint(0, opt.n_classes, batch_size)))
# Generate a batch of images
gen_imgs = generator(z, gen_labels)
# Loss measures generator's ability to fool the discriminator
validity = discriminator(gen_imgs, gen_labels)
g_loss = adversarial_loss(validity, valid)
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Loss for real images
validity_real = discriminator(real_imgs, labels)
d_real_loss = adversarial_loss(validity_real, valid)
# Loss for fake images
validity_fake = discriminator(gen_imgs.detach(), gen_labels)
d_fake_loss = adversarial_loss(validity_fake, fake)
# Total discriminator loss
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
optimizer_D.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
batches_done = epoch * len(dataloader) + i
if batches_done % opt.sample_interval == 0:
sample_image(n_row=10, batches_done=batches_done)
minist测试
