文章目录
一.前言
二.知识储备(基于个人理解)
三.爬取验证码图片
四.数据处理
五.定义、训练、测试神经网络
六.可视化处理与后续应用
七.卷积神经网络模块源代码
一.前言
疫情仍然严重,继写完上一篇博客后我也从零开始学习神经网络,真是绕了很多弯路啊。。这网上资料多归多,有用的属实难找,再加上之前忙美赛,转眼就隔了两周才有进展,这里非常想把自己从一个什么都不懂的小白一步步成长到可以自己定义、训练神经网络的大白之路分享给所有想要入门的伙伴们。如果大家看完这一篇也能够自己进行实践、操作,那么我将感到十分满足~
还有点做这个的心路历程,之前写完爬虫我是想实现自动登陆微人大(我是人大的学生),奈何它有个验证码,我用了手动输入的方法,但觉得太low;用了调用打码平台api的方法,但要交钱;用了tesserocr识别,但准确率太低,因此决定自己整一手机器学习,专门识别微人大的验证码~这就踏上了不归路hhh
再说点题外话,我想在前言里把自己这个假期自学python以及上学期有过一段自己用cocos creator编写游戏的感受总结出3点分享给大家:
1.任务驱动型学习是最有效的。
现在知识太多,我们学习时无法把所有点全都学会,长时间的、漫无目的地研读用户手册无疑是效率最低的做法;我们最好先明确学会了这个软件(语言)后要完成的项目,这样无论是搜索资料、进行学习都会变得容易许多,也更容易获得成就感。
2.我们都站在巨人的肩膀上,原理层面的知识,根据个人需求和时间预算进行深挖。
刚开始学习神经网络时,我甚至连卷积神经网络和BP神经网络都没有分清,甚至弄混了两者的权重矩阵,就直接开始钻研后向传播算法的证明过程,结果什么也没搞懂不说(因为我根本不知道它用在哪个过程),还浪费了很多时间;最后才发现原来pytorch中人家都有封装好的方法进行后向传播。。。吐了
因此,搞清学习某个东西时自己对结果的定位,到底是要全面了解、滴水不漏还是用它完成某件事,如果是后者,请不要浪费太多时间去探寻“为什么”,而是去弄明白"怎么做“。
3.不要过早优化,先试一试再说。
我们初学新的事物时,千万别想一步登天,看到不懂的地方,搞清楚其使用方法后,不要想是不是还有更简单的方法,而是先自己试一试,如果之后了解到更优方法再改,否则就是思而不学则殆
4.闲话说完啦,我们开始吧!还没有安装pytorch的宝贝们可以看看上一篇博客
二.知识储备
这里先贴出一些优质博客:
1.首先我们需要了解,什么是机器学习和深度学习
就我现在的理解,无论是机器学习还是深度学习,其核心只有一个:函数拟合。对于二维平面上离散的点
( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) (x_1,y_1),(x_2,y_2),...,(x_n,y_n) (x1,y1),(x2,y2),...,(xn,yn)
我们可以用数学方法进行二次回归、多项式回归等方法将其拟合在一个直线/曲线上,但是,对于n维空间中的点 ( x 1 ( 1 ) , x 2 ( 1 ) , . . . x n ( 1 ) , y ( 1 ) ) , ( x 1 ( 2 ) , x 2 ( 2 ) , . . . x n ( 2 ) , y ( 2 ) ) , . . . , ( x 1 ( n ) , x 2 ( n ) , . . . x n ( n ) , y ( n ) ) (x_1^{(1)},x_2^{(1)},...x_n^{(1)},y^{(1)}),(x_1^{(2)},x_2^{(2)},...x_n^{(2)},y^{(2)}),...,(x_1^{(n)},x_2^{(n)},...x_n^{(n)},y^{(n)}) (x1(1),x2(1),...xn(1),y(1)),(x1(2),x2(2),...xn(2),y(2)),...,(x1(n),x2(n),...xn(n),y(n)),我们是难用数学直观的进行计算的。但是计算机强大的运算能力可以通过复杂的算法(一般就是梯度下降)来拟合出一个合适的函数,达到用预测值逼近真实值的目的。
对于我们接下来要进行的验证码识别,其拟合的目的就是让计算机识别到验证码图片的特征,将其分为26*4类,也就是让函数在n维空间的不同位置有着26*4种不同的输出。这个在训练网络的部分会细讲
2.什么是BP神经网络(落后),什么是卷积神经网络(重要,必须得看),利用pytorch封装好的方法搭建简单的神经网络(三篇连在一起,主要用来参考,零基础可以先动手实践),以及如何计算图片经过卷积层、池化层后的尺寸(重要)。
个人见解:BP神经网络其实就是卷积神经网络的全连接层,且现在常用的是卷积神经网络,由于本篇博客涉及的验证码识别项目运用的就是卷积神经网络,在此我也只对其进行详细的介绍。
最开始我们必须明确,我们传入卷积神经网络的是图片转化而成的tensor!!但为了方便理解,我们可以认为传入网络的就是一张张图片。
接下来,卷积神经网络中有几个重要的参数,我想通过介绍他们的方式,让大家对卷积神经网络有更直观的了解:
-
e_poch:
首先,我们把让计算机进行”学习“的过程称为训练,联想到训练动物进行杂技表演,只练一次是不会达到目的的,因此我们会训练很多次,每一次训练,称为一次e_poch。
具体进行几轮训练,需要我们人为地进行规定,一般根据经验和模型的反馈进行调整 -
batch_size:
计算机的计算能力很强,我们一次只传入一张图片实在太过寒酸,计算机资源无法得到有效利用。因此,我们每次向网络中传入batch_size张图片,这样不仅更大的利用计算机的资源,还让计算机更好地对图像特征进行分析。
其具体数值地大小,需要我们人为地进行设置,一般根据经验和模型的反馈进行调整 -
宽度和高度:
我们进行图片识别时,传入神经网络的是图片,既然是图片,那么就会有尺寸,即为图片的宽度和高度,这其实就是图片的像素大小,我们右键图片,在属性中的详细信息就可以查看,如下图:
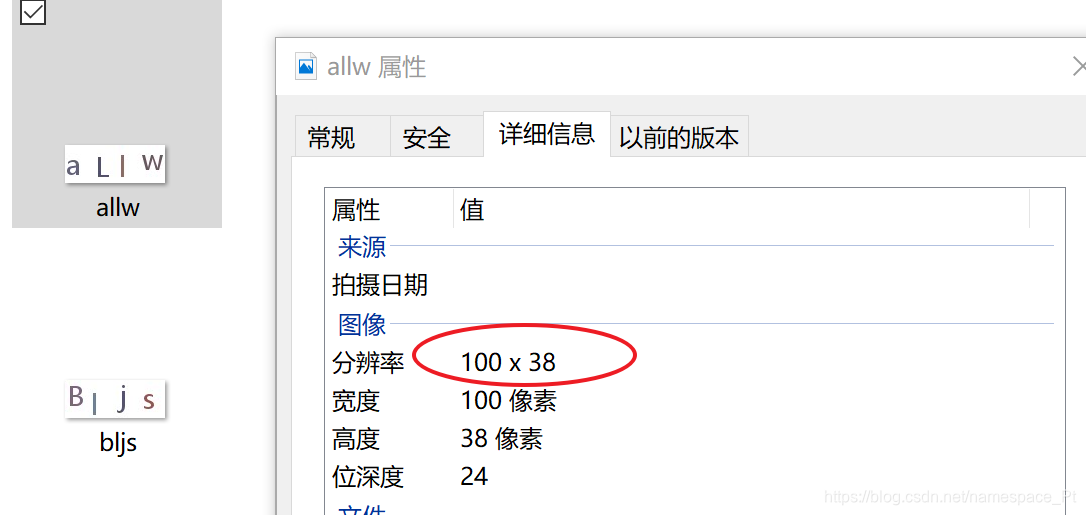
针对这张图片,我们将其理解成由100*38个像素点构成的,每一个点上都包含着图片的信息(主要是颜色),这个信息就是图片的特征,我们神经网络的自变量即为这个特征的倍数,卷积神经网络中卷积、池化、全连接均涉及特征维度的运算,即涉及对尺寸的修改。 -
channels:
翻译为通道数,我们进行图片识别时,传入神经网络的图片是 ( R , G , B ) (R,G,B) (R,G,B)三通道的,我将其理解为三张图片叠在一起。
而只有卷积运算涉及通道层面,卷积运算通过卷积核与图片做Hadamard乘积,将图片的通道数增加,提升计算机对图片特征的辨识能力。因此,对于我们的项目,卷积神经网络第一层卷积的in_channel,即输入的通道数一定为3。
out_channel即为经过这一层卷积运算希望得到的通道数,这个参数只能靠经验和模型的反馈进行设置;同时,第 n − 1 n-1 n−1 层卷积的out_channel一定等于第 n n n 层的in_channel。 -
kernel_size
意为卷积(池化)核的尺寸,通常设置为一个数是因为默认卷积核为方阵,我们也可以指定其为 ( M ∗ N ) (M*N) (M∗N)的矩阵。
其具体数值地大小,需要我们人为地进行设置,一般根据经验和模型的反馈进行调整 -
stride
意为卷积(池化)核每进行一次运算后移动的步长。
其具体数值地大小,需要我们人为地进行设置,一般根据经验和模型的反馈进行调整 -
padding
意为在特征图边框补零的个数,通常设置为一个数是默认各边补一样多个数。
其具体数值地大小,需要我们人为地进行设置,一般根据经验和模型的反馈进行调整 -
经历卷积、池化后图片的尺寸计算公式:
n ′ = n + 2 ∗ p a d d i n g − k e r n e l _ s i z e s t r i d e + 1 n' = \frac{n+2*padding-kernel\_size}{stride}+1 n′=striden+2∗padding−kernel_size+1
其中 n n n可以代入图片的宽或者高
这个公式相当重要,因为在定义网络的过程中,经历过数层卷积和池化后,我们传入全连接层的一定是一个一维向量!而这个向量的长度,即为 c h a n n e l s ∗ w i d t h ∗ h e i g h t channels*width*height channels∗width∗height 其中 c h a n n e l s , w i d t h , h e i g h t channels,width,height channels,width,height分别代表计算后的最终通道数、宽度、高度 -
view()方法(重要!!!)
eg m y _ t e n s o r . v i e w ( m , n ) my\_tensor.view(m,n) my_tensor.view(m,n)
作用是将tensor指定为(m*n)的维度。
eg m y _ t e n s o r . v i e w ( − 1 , n ) my\_tensor.view(-1,n) my_tensor.view(−1,n)
作用是基于my_tensor的元素个数,将其按顺序分配到n列上,即让计算机自行计算所得tensor的行数
在进行过卷积和池化后,我们要将得到的tensor(图片)转化成一维的,一般就会使用这个方法。
三.爬取验证码图片
用python进行数据爬取的系统流程我在第一篇博客中已经讲过了,这里从简,结合代码,讲述一下流程:
- 登陆微人大官网,找到验证码的url:
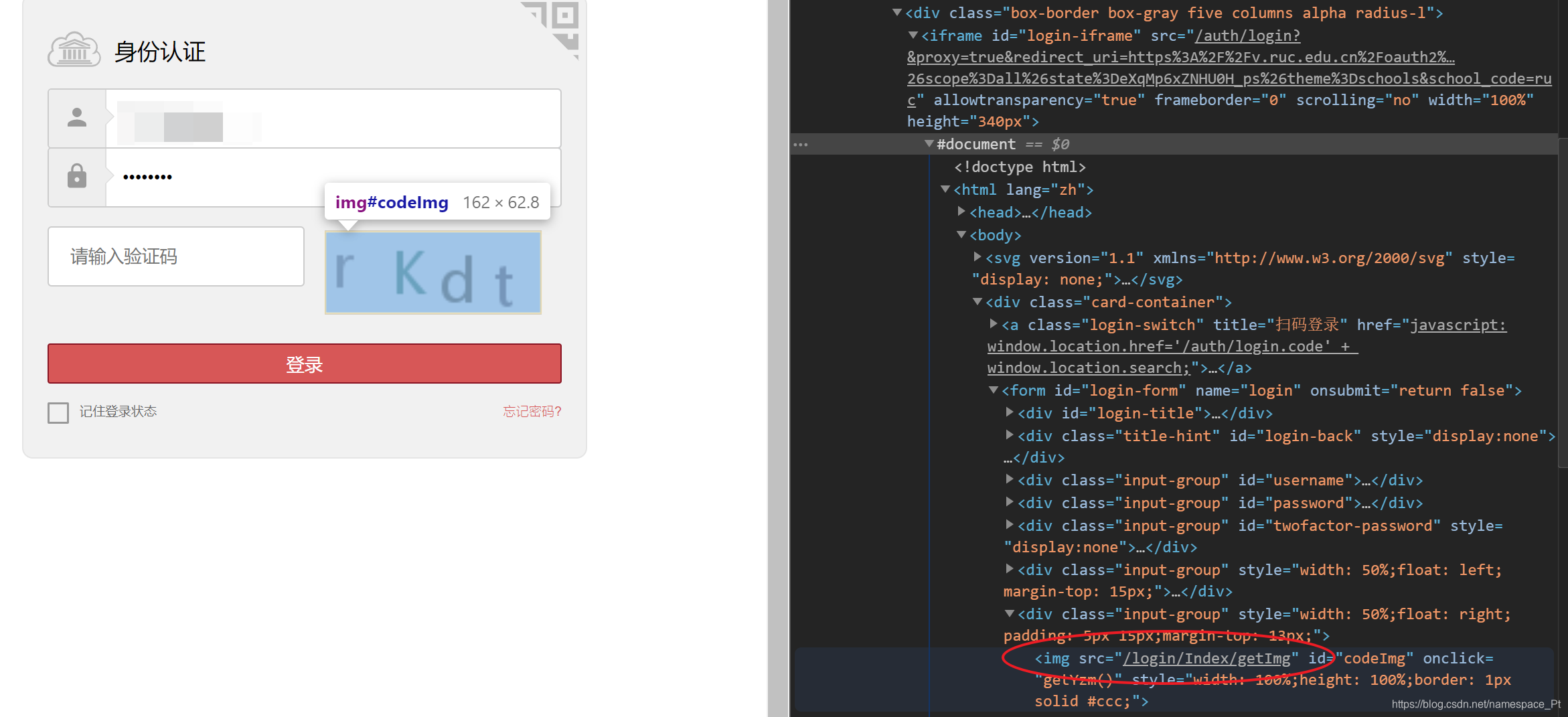
- 访问url,进行图片下载,分别下载1500张训练集,200张测试集:
import requests url = 'https://v.ruc.edu.cn/login/Index/getImg' #下载1500张作为训练集 for i in range(1,1500): #访问url response = requests.get(url) #获取内容 content = response.content #定义路径 path = 'C:\Users\Pt\Pictures\testify_code_train\code-' + str(i) + '.png' #保存进文件 with open(path,'w') as f: f.write(content) #下载300张作为测试集 for i in range(1,300): #访问url response = requests.get(url) #获取内容 content = response.content #定义路径 path = 'C:\Users\Pt\Pictures\testify_code_test\code-' + str(i) with open(path,'w') as f: f.write(content)
四.数据处理
现在我们得到了分别存在两个文件夹中的测试集图片和训练集图片,但是其命名是code-xxx,我们需要将每个验证码图片重命名为其正确内容,这个过程称为打标签;之后要将其加载为pytorch可以载入的数据格式,即dataset和dataloader,我们一个一个来:
1.打标签
针对验证码,由于验证码是我们已经本地下载好的,我们可以选择人工打标签,或者用打码平台打标签;当然,也可以用python自带库生成的标好的验证码集。这里我是用打码平台api的:
-
利用云打码提供的api进行打标签(收费,15块可以打差不多3000张)
具体的操作方法大家注册后可以查看开发人员手册,这里粘贴下代码:import sys import os import re from ctypes import * print('>>>正在初始化...') #平台提供的库 YDMApi = windll.LoadLibrary('C:/Pt_Python/Python调用示例/yundamaAPI-x64.dll') appId = 6666 #软件ID,开发者分成必要参数。登录开发者后台【我的软件】获得! appKey = b'zptzuishuai' #软件密钥,开发者分成必要参数。登录开发者后台【我的软件】获得! username = b'abcd' #用户ID password = b'123456' #用户密码 codetype = 3004 #验证码类型,这里是四位纯英文 result = c_char_p(b" ") timeout = 60 for i in range(1,1500): #找已经下载好的验证码图片的路径 title = 'C:/Users/Pt/Pictures/testify_code_train/code-'+str(i)+'.png' #定义编码方式 filename = title.encode('cp936') #调用api captchaId = YDMApi.YDM_EasyDecodeByPath(username, password, appId, appKey, filename, codetype, timeout, result) #定义新的文件名(验证码内容) newName = 'C:/Users/Pt/Pictures/testify_code/' + result.value.decode('cp936') + '.png' #查看目录中是否咦存在相同的 if os.path.exists(newName): continue #不存在则重命名 os.rename(title,newName) #对于测试集也是相同的方法,这里不再赘述 -
当然啦,我也会把我已经打好标签的验证码图片上传到百度云(我现在在新疆百度云用不了,等回到北京再更新),大家有需要数据集的可以评论区留邮箱,我发你们邮箱。 而且由于我当时下载时意外中断,总共获得了1584张训练集图片和198张测试集图片。
2.Dataset和Dataloader
首先呢,大家必须明确,pytorch有自己封装好的数据加载类Dataloader,这意味着pytorch通过Dataloader来读取外来数据;**在Dataloader中,又封装着一个存放数据的类Dataset,同时,Dataset是一个抽象类,只能被继承,不能直接实例化。**而要继承Dataset,有三个方法必须由用户自己做覆盖,他们分别是:
__init__(self,arguments)即初始化这个类,
__len__(self)即获取数据集的长度,
__getitem__(self,index)即返回数据集中某一个元素
神经网络、Dataloader和Dataset大致的工作流程是:我们将原始的图片通过对Dataset的初始化,存入继承后的Dataset的某个属性中,之后Dataloader通过调用Dataset的核心方法__len__(self)和__getitem__(self,index)得到图片,进行相应的transform(一般是图片与处理,核心是把图片转换成tensor)后每次提供batch_size个tensor供神经网络计算使用。
我们现在从如何继承Dataset并将图片存入说起。
-
Dataset
一般来说,对于本地的数据,我们把每一张图片的路径和它对应的标签,用空格隔开后连成一行,逐行存入一个.txt文件中。这样是方便像Dataset中添加属性,先上代码:
import os import sys import re #声明图片路径 dir_train = 'C:/Users/Pt/Pictures/testify_code_train/' dir_test = 'C:/Users/Pt/Pictures/testify_code_test/' #列出所有图片的名字 fileDist_train = os.listdir(dir_train) fileDist_test = os.listdir(dir_test) train = open('./Pytorch/dists/train.txt','a') #a为追加模式 test = open('./Pytorch/dists/test.txt','a') for file in fileDist_train: #取.png前的部分,作为标签,将路径和标签中间隔一个空格后逐行写入.txt文件中 name = dir_train + file + ' ' + re.split('\.',file)[0] + '\n' train.write(name) for file in fileDist_test: name = dir_test + file + ' ' + re.split('\.',file)[0] + '\n' test.write(name) test.close() train.close()现在我们需要考虑如何把这个.txt文件物尽其用:
__init__(self,arguments)中的arguments一般包含几项:path,transform,target_transform和loader- path代表生成的.txt文件的路径
- transform是要对图片对象进行的预操作
- target_transform是要对标签进行的预操作
- loader是在__getitem__(self,index)中取得图片路径时加载图片的方法,这里就是将图片转换成RGB三通道的格式
#定义loader,需要将图片转换成RGB三通道的模式 def default_loader(path): return Image.open(path).convert('RGB')
在这个初始化函数中,我们先通过缺省的方式给出transform、target_transform的值,之后在Dataloader调用Dataset时,相应的transform会更新;再通过逐行读取.txt文件的方法将图片的路径和图片的标签存入Dataset的属性之中(属性都是用户自己定义的)
但是问题来了,计算机能拟合出的结果一定是一个tensor,而字符串类型的验证码没有办法转换成tensor,那么怎么办呢??
我们通过自定义一个将字符串转换为数组的编码方式来解决
def myEncode(string): #string为验证码 result = [] for char in string: #对每一位验证码,创造一个26位均为0的列表,将其在字母表中对应的位置改为1 vec = [0] * 26 vec[ord(char) - 97] = 1 #每一位验证码都对应这样一个仅有一位为1的列表,将这些列表连在一起,成为最终26*4的一维数组,之后转换成tensor result += vec return result这样准备工作已经完全,我们开始重写三个方法:
class MyDataset(Dataset): #初始化,transform缺省为None def __init__(self,txt,transform=None,target_transform=None,loader=default_loader): #先调用基类的__init__()方法 super().__init__() #创建空列表 imgs = [] with open(txt,'r') as f: #逐行读入.txt文件内容 for line in f: #去除末尾的换行符 line = line.rstrip('\n') #找到路径和标签间隔的空格,将字符串一分为二,前者为图片路径,后者为标签 attrs = line.split(' ') #编码 label = myEncode(attrs[1].lower()) #加入列表 imgs.append((attrs[0],label)) #添加属性,这里的imgs是元组构成的列表,每一个元组有两个元素,前者为图片路径,后者为编码后的标签 self.imgs = imgs #添加属性 self.transform = transform #添加属性 self.target_transform = target_transform #添加属性 self.loader = loader def __getitem__(self,index): #分别取得图片路径和标签 src,label = self.imgs[index] #加载图片 img = self.loader(src) #在取出图片时根据设定的transform方式进行预变换 if self.transform is not None: img = self.transform(img) #在取出图片时根据设定的target_transform方式进行预变换 if self.target_transform is not None: label = self.target_transform(label) return img,torch.tensor(label) def __len__(self): #数据集的长度即为imgs的长度 return len(self.imgs) #定义预变换 tf = transforms.Compose([ transforms.ToTensor() ]) #调用类进行数据存入 data_train = MyDataset('Pytorch/dists/train.txt',transform=tf) data_test = MyDataset('Pytorch/dists/test.txt',transform=tf) -
Dataloader
Dataloader的可选参数有很多,**必须传入的有Dataset的实例,比较重要的是batch_size和shuffle,batch_size我们已经介绍过了,shuffle的意思是是否进行随机打乱。**值得注意的是,训练集数据最好随机打乱,但测试集不用。上代码:
batch_size = 64 train_loader = DataLoader(data_train,batch_size=batch_size,shuffle=True) test_loader = DataLoader(data_test,batch_size=batch_size,shuffle=False)至此,数据处理结束。
五.定义、训练和测试神经网络
-
定义卷积神经网络
一般来说,我们的神经网络的定义是继承torch.nn.Module类的,要完成自己神经网络的设计,我们需要重写它的__init__(self) 方法 和 forward(self,input) 方法。
我默认大家已经了解过卷积神经网络的结构,因此我这里结合代码,着重给出每一次计算后的tensor在各维度上的大小:
class CNN(nn.Module): def __init__(self): #先调用父类的__init__()方法 super().__init__() #####ORIGINAL-----batch_size * channels * width * height = 64*3*100*38-----##### self.net = nn.Sequential( nn.Conv2d(3,16,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(16),nn.ReLU(), #batch_size * channels * width * height = 64*16*50*19 nn.Conv2d(16,64,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(64),nn.ReLU(), #batch_size * channels * width * height = 64*64*25*9 nn.Conv2d(64,512,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(512),nn.ReLU() #batch_size * channels * width * height = 64*512*12*4 ) self.fc = nn.Sequential( #这里只传入channels*width*height #全连接层得到的应该是最终的分类数,验证码每个位置有四种可能,符合加法原理 nn.Linear(512*12*4,26*4) ) def forward(self,x): #先进行卷积和池化 x = self.net(x) #将tensor展成一维 x = x.view(-1,512*12*4) #全连接 x = self.fc(x) return x -
训练网络
训练网络,即将图片和标准验证码传入我们定义的神经网络中,让计算机进行函数的拟合,每一个e_poch结束后更新一次loss值,我们还是结合代码进行说明:
#定义模型 model = CNN() if torch.cuda.is_available(): #转移到gpu,加速运算 model = model.cuda() #采用pytorch自带的多标签多分类的损失函数 lossFunc = nn.MultiLabelSoftMarginLoss() #采用Adam算法进行权重参数的调整 optimizer = optim.Adam(model.parameters()) #训练60波 for e_poch in range(1,60): #开启训练模式,激活BatchNorm2d函数 model.train() #每一波训练的loss值 loss_train = 0.0 #loss_test = 0.0 #acc_train = 0.0 #acc_test = 0.0 #每一波训练的总图片数 count = 0 #从train_loader(训练集)即Dataloader中加载数据 for each in train_loader: #因定义的时候是元组,这里也要分别取出元组的元素 img = each[0] label = each[1] #转移到gpu上 if torch.cuda.is_available(): img = img.cuda() label = label.cuda() #前向传播,这里隐式调用了forward()方法 out = model(img) #计算loss loss = lossFunc(out,label) #将梯度置0 optimizer.zero_grad() #后向传播 loss.backward() #用Adam算法优化权重参数 optimizer.step() #accuracy = getAcc(out,label) #总loss loss_train+=loss #acc_train += accuracy #总图片数 count += 1 #每进行一波训练,打印一次 print('e_poch:{},loss_train:{:.4}'.format(e_poch,loss_train/count)) -
测试网络
训练后我们肯定要对网络的效果进行评估,这时测试集就派上了用场。同时,loss值过于不直观,我们引进一个新的指标:acc,即神经网络的准确率。
还记得我们最开始讲到的,神经网络的核心是拟合,且其操作对象是tensor。它的输出无法达到完全与我们编码得到的只含有1和0的向量,相对的,输出tensor的每一位基本都是小数,这个小数足够逼近1或0,因此我们要找到输出tensor中最大的元素,把这个元素对应位置当作1对待,剩下的位置都相当于0。这个过程可以形象的理解为给tensor解码,因此我们定义准确率函数:def getAcc(pred,label): #每次神经网络的输出和标准的验证码尺寸均为[batch_size,26*4],这里先将其转为每行26列的形式,即每行代表一个字母 pred,label = pred.view(-1,26),label.view(-1,26) #pred = nn.functional.softmax(pred,dim=1) #得到每一行最大的数的列序号,即得到这一行代表的字母 pred = torch.argmax(pred,dim=1) label = torch.argmax(label,dim=1) #再转为一行四个字母,即一行代表一个验证码 pred,label = pred.view(-1,4),label.view(-1,4) #记录是否正确的列表 correct_list = [] for i in range(pred.size(0)): #如果有pred和label的相应行相等,代表四个字母都相同,验证码预测正确 if torch.equal(pred[i],label[i]): correct_list.append(1) #反之错误 else: correct_list.append(0) #计算正确率 acc = sum(correct_list)/len(correct_list) return acc在测试网络的时候,我们用acc作为衡量网络效果的标准,同时也可以显示loss值,与训练集进行对比,下面给出测试网络的代码:
#测试其实是包含在e_poch的循环中的,位置在train后面 #记录每一波训练的图片总数 count = 0 #进入测试模式,关闭BatchNorm2d. model.eval() #加载测试集中数据,一次加载batch_size张图片 for each in test_loader: #因定义的时候是元组,这里也要分别取出元组的元素 img = each[0] label = each[1] if torch.cuda.is_available(): #转移到gpu img = img.cuda() label = label.cuda() #前向传播 out = model(img) #计算loss loss = lossFunc(out,label) #计算准确率 accuracy = getAcc(out,label) #一波训练总loss loss_test+=loss #一波训练总准确率 acc_test += accuracy #更新图片个数 count += 1 #输出这一波训练的平均loss和平均准确率 print('e_poch:{},loss_test:{:.4},acc_test:{:.4}'.format(e_poch,loss_test/count,acc_test/count))我们让训练过程也输出准确率(代码中注释掉的部分),得到结果如下(每次训练效果都会不尽相同):
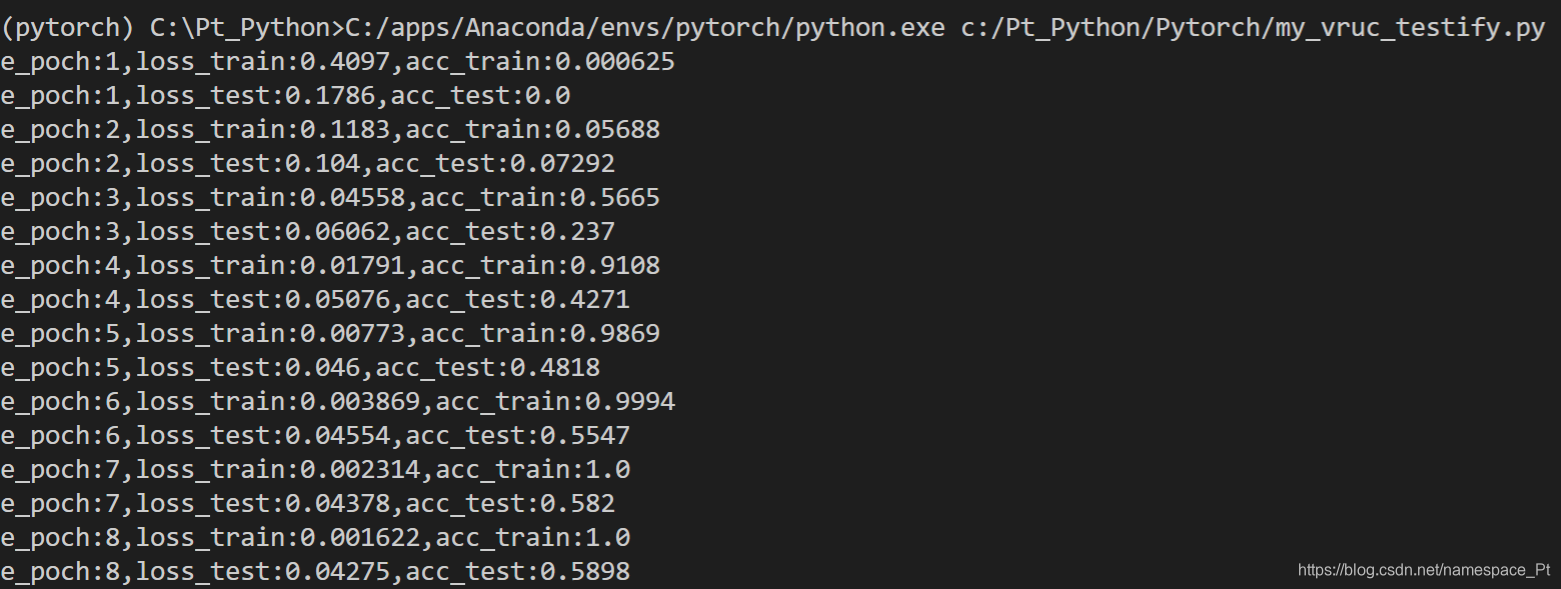
可以看到前8轮训练,loss_train迅速降低,acc_train迅速升高,且在第八波acc_train就已经达到1即训练集中所有图片都已经全部拟合正确,此时测试集中数据的预测准确率acc_test在58.98%
继续训练:(这里的图片是之前训练70轮的时候截的,后来改成60波的时候忘记截图了。。。但数据是差不多的,60波训练最终也能达到75%的准确率)

可以看到,训练集一直保持过拟合的状态,训练集的准确率最终达到了75% 已经相当理想了,再训练的话因为过拟合,准确率反而会降低。
如果还想提高准确率,只能扩大训练集,但是懒得弄了。。
至此,我们的卷积神经网络的定义、训练和测试全部结束。
六.可视化处理与后续应用
1.模型的保存和加载
- 我们已经将网络训练完毕,我们要实现让别的程序都能用这个训练好的模型进行验证码识别,必须把模型保存下来,这里使用torch.save():
#注意一定要保存训练好的模型model,而不是我们定义的模型CNN,路径是自己定义的,注意文件后缀.pth torch.save(model,'Pytorch/modules/code_recognition_vruc_111.pth') - 保存后,我们就可以在别的程序中使用torch.load进行加载,注意这里就已经将model的变量名和其对应网络的各项参数全都加载进来了:
model = torch.load('Pytorch/modules/code_recognition_vruc.pth')
2.可视化测试图片及输出预测、真实验证码
- 别忘了,我们从神经网络中得到的预测值是tensor类型的数据,我们需要将其转换成字符~~因此在这里定义自己的解码函数:
def myDecode(pred,label): #每次传入的是尺寸为[1,4*26]的tensor,这里先将其转为每行26列的形式,即每行代表一个字母 pred,label = pred.view(-1,26),label.view(-1,26) #得到每一行最大的数的列序号,即得到这一行代表的字母;注意转换成cpu()形式后再转为numpy数组,这样才能解码 pred = torch.argmax(pred,dim=1).cpu().numpy() label = torch.argmax(label,dim=1).cpu().numpy() #创建空字符串 pre_str = '' tar_str = '' #把每一行的数字转换为字母 for pre_num,tar_num in zip(pred,label): #97是'a'的ascii值,用chr()方法得到对应字母,加入预测码和真实码的字符串中 pre_str += chr(pre_num+97) tar_str += chr(tar_num+97) #这样就得到了一对预测验证码和真是验证码 return pre_str,tar_str - 接下来将验证码图片可视化,用到matplotlib库的imshow方法和show方法:
def predict_visibal():
#加载模型
cnn = torch.load('Pytorch/modules/code_recognition_vruc.pth')
#每次加载batch_size张图片tensor
for each in test_loader:
#分别取元组的第一、第二个元素作为图片和标签
imgs,labels = each[0],each[1]
#转移到gpu
if torch.cuda.is_available():
imgs = imgs.cuda()
labels = labels.cuda()
#前向传播
preds = cnn(imgs)
#将batch_size个tensor分开进行可视化和解码
for i in range(1,batch_size):
#用permute方法改变tensor的维度顺序,从batch_size*channels*width*height转为batch_size*width*height*channels
#取四维数组的第一维第i个元素,即width*height*channels得图片,并将其转移到cpu上后转换为numpy数组
plot.imshow(imgs.permute((0,2,3,1))[i].cpu().numpy())
#显示图片
plot.show()
#解码
pre_str,tar_str = myDecode(preds[i],labels[i])
#打印
print('pre_str:{}||tar_str:{}'.format(pre_str,tar_str))
至此,可视化已经完成,贴一下效果图:
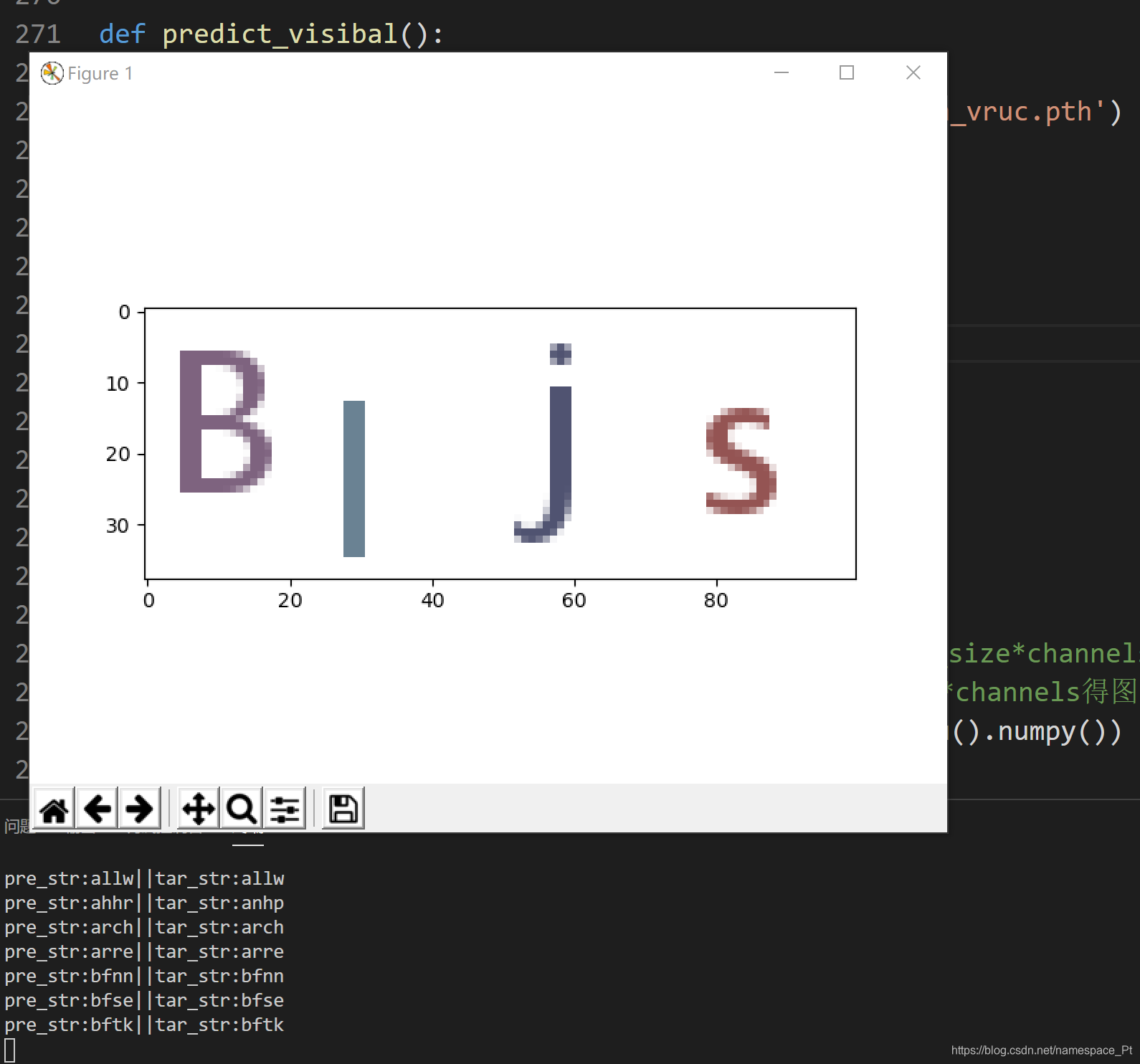
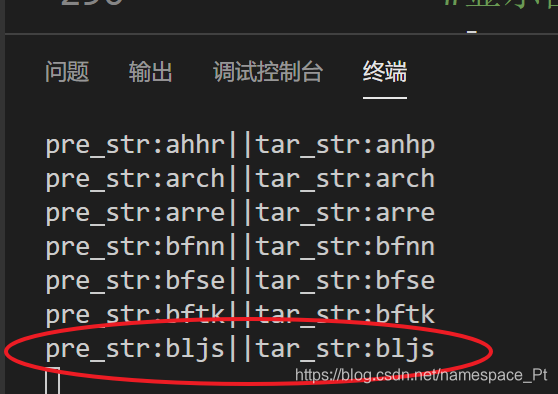
到这里,我们利用卷积神经网络进行验证码识别的项目就结束啦!!大家有没有收获呢?
七.卷积神经网络模块源代码
由于本人对于python将源代码分开保存还不是很精通,因此这里将所有源码放在一个.py文件中
import torch
import torchvision
#import tensorboard
import numpy
import matplotlib.pyplot as plot
from alphabet import alphabet
from PIL import Image
from torch import nn,optim
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader,Dataset
#定义loader,需要将图片转换成RGB三通道的模式
def default_loader(path):
return Image.open(path).convert('RGB')
def myEncode(string):
#string为验证码
result = []
for char in string:
#对每一位验证码,创造一个26位均为0的列表,将其在字母表中对应的位置改为1
vec = [0] * 26
vec[ord(char) - 97] = 1
#每一位验证码都对应这样一个仅有一位为1的列表,将这些列表连在一起,成为最终26*4的一维数组,之后转换成tensor
result += vec
return result
def myDecode(pred,label):
#每次传入的是尺寸为[1,4*26]的tensor,这里先将其转为每行26列的形式,即每行代表一个字母
pred,label = pred.view(-1,26),label.view(-1,26)
#得到每一行最大的数的列序号,即得到这一行代表的字母;注意转换成cpu()形式后再转为numpy数组,这样才能解码
pred = torch.argmax(pred,dim=1).cpu().numpy()
label = torch.argmax(label,dim=1).cpu().numpy()
#创建空字符串
pre_str = ''
tar_str = ''
#把每一行的数字转换为字母
for pre_num,tar_num in zip(pred,label):
#97是'a'的ascii值,用chr()方法得到对应字母,加入预测码和真实码的字符串中
pre_str += chr(pre_num+97)
tar_str += chr(tar_num+97)
#这样就得到了一对预测验证码和真是验证码
return pre_str,tar_str
def getAcc(pred,label):
#每次神经网络的输出和标准的验证码尺寸均为[batch_size,26*4],这里先将其转为每行26列的形式,即每行代表一个字母
pred,label = pred.view(-1,26),label.view(-1,26)
#pred = nn.functional.softmax(pred,dim=1)
#得到每一行最大的数的列序号,即得到这一行代表的字母
pred = torch.argmax(pred,dim=1)
label = torch.argmax(label,dim=1)
#再转为一行四个字母,即一行代表一个验证码
pred,label = pred.view(-1,4),label.view(-1,4)
#记录是否正确的列表
correct_list = []
for i in range(pred.size(0)):
#如果有pred和label的相应行相等,代表四个字母都相同,验证码预测正确
if torch.equal(pred[i],label[i]):
correct_list.append(1)
#反之错误
else:
correct_list.append(0)
#计算正确率
acc = sum(correct_list)/len(correct_list)
return acc
class MyDataset(Dataset):
#初始化,transform缺省为None
def __init__(self,txt,transform=None,target_transform=None,loader=default_loader):
#先调用基类的__init__()方法
super().__init__()
#创建空列表
imgs = []
with open(txt,'r') as f:
#逐行读入.txt文件内容
for line in f:
#去除末尾的换行符
line = line.rstrip('\n')
#找到路径和标签间隔的空格,将字符串一分为二,前者为图片路径,后者为标签
attrs = line.split(' ')
#编码
label = myEncode(attrs[1].lower())
#加入列表
imgs.append((attrs[0],label))
#添加属性,这里的imgs是元组构成的列表,每一个元组有两个元素,前者为图片路径,后者为编码后的标签
self.imgs = imgs
#添加属性
self.transform = transform
#添加属性
self.target_transform = target_transform
#添加属性
self.loader = loader
def __getitem__(self,index):
#分别取得图片路径和标签
src,label = self.imgs[index]
#加载图片
img = self.loader(src)
#在取出图片时根据设定的transform方式进行预变换
if self.transform is not None:
img = self.transform(img)
#在取出图片时根据设定的target_transform方式进行预变换
if self.target_transform is not None:
label = self.target_transform(label)
return img,torch.tensor(label)
def __len__(self):
#数据集的长度即为imgs的长度
return len(self.imgs)
#定义预变换
tf = transforms.Compose([
transforms.ToTensor()
])
#调用类进行数据存入
data_train = MyDataset('Pytorch/dists/train.txt',transform=tf)
data_test = MyDataset('Pytorch/dists/test.txt',transform=tf)
batch_size = 64
train_loader = DataLoader(data_train,batch_size=batch_size,shuffle=True)
test_loader = DataLoader(data_test,batch_size=batch_size,shuffle=False)
class CNN(nn.Module):
def __init__(self):
#先调用父类的__init__()方法
super().__init__()
#####ORIGINAL-----batch_size * channels * width * height = 64*3*100*38-----#####
self.net = nn.Sequential(
nn.Conv2d(3,16,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(16),nn.ReLU(),
#batch_size * channels * width * height = 64*16*50*19
nn.Conv2d(16,64,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(64),nn.ReLU(),
#batch_size * channels * width * height = 64*64*25*9
nn.Conv2d(64,512,kernel_size=3,padding=(1,1)),nn.MaxPool2d(kernel_size=2,stride=2),nn.BatchNorm2d(512),nn.ReLU()
#batch_size * channels * width * height = 64*512*12*4
)
self.fc = nn.Sequential(
#这里只传入channels*width*height
#全连接层得到的应该是最终的分类数,验证码每个位置有四种可能,符合加法原理
nn.Linear(512*12*4,26*4)
)
def forward(self,x):
#先进行卷积和池化
x = self.net(x)
#将tensor展成一维
x = x.view(-1,512*12*4)
#全连接
x = self.fc(x)
return x
def train():
#定义模型
model = CNN()
if torch.cuda.is_available():
#转移到gpu,加速运算
model = model.cuda()
#采用pytorch自带的多标签多分类的损失函数
lossFunc = nn.MultiLabelSoftMarginLoss()
#采用Adam算法进行权重参数的调整
optimizer = optim.Adam(model.parameters())
#训练60波
for e_poch in range(1,60):
#开启训练模式,激活BatchNorm2d函数
model.train()
#每一波训练的loss值
loss_train = 0.0
loss_test = 0.0
acc_train = 0.0
acc_test = 0.0
#每一波训练的总图片数
count = 0
#从train_loader即Dataloader中加载数据
for each in train_loader:
#因定义的时候是元组,这里也要分别取出元组的元素
img = each[0]
label = each[1]
#转移到gpu上
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
#前向传播,这里隐式调用了forward()方法,输出尺寸是[batch_size,26*4]
out = model(img)
#计算loss
loss = lossFunc(out,label)
#将梯度置0
optimizer.zero_grad()
#后向传播
loss.backward()
#用Adam算法优化权重参数
optimizer.step()
accuracy = getAcc(out,label)
#总loss
loss_train+=loss
acc_train += accuracy
#总图片数
count += 1
#每进行一波训练,打印一次
print('e_poch:{},loss_train:{:.4},acc_train:{:.4}'.format(e_poch,loss_train/count,acc_train/count))
#记录每一波训练的图片总数
count = 0
#进入测试模式,关闭BatchNorm2d.
model.eval()
#加载测试集中数据,一次加载batch_size张图片
for each in test_loader:
#因定义的时候是元组,这里也要分别取出元组的元素
img = each[0]
label = each[1]
if torch.cuda.is_available():
#转移到gpu
img = img.cuda()
label = label.cuda()
#前向传播
out = model(img)
#计算loss
loss = lossFunc(out,label)
#计算准确率
accuracy = getAcc(out,label)
#一波训练总loss
loss_test+=loss
#一波训练总准确率
acc_test += accuracy
#更新图片个数
count += 1
#输出这一波训练的平均loss和平均准确率
print('e_poch:{},loss_test:{:.4},acc_test:{:.4}'.format(e_poch,loss_test/count,acc_test/count))
torch.save(model,'Pytorch/modules/code_recognition_vruc_111.pth')
def test():
count = 0
accuracy = 0
acc_test = 0
model = torch.load('Pytorch/modules/code_recognition_vruc.pth')
for each in test_loader:
img = each[0]
label = each[1]
if torch.cuda.is_available():
img = img.cuda()
label = label.cuda()
out = model(img)
accuracy = getAcc(out,label)
acc_test += accuracy
count += 1
print('acc_test:{:.4}'.format(acc_test/count))
def predict_visibal():
#加载模型
cnn = torch.load('Pytorch/modules/code_recognition_vruc.pth')
cnn.dump_patches = True
#每次加载batch_size张图片tensor
for each in test_loader:
#分别取元组的第一、第二个元素作为图片和标签
imgs,labels = each[0],each[1]
#转移到gpu
if torch.cuda.is_available():
imgs = imgs.cuda()
labels = labels.cuda()
#前向传播
preds = cnn(imgs)
#将batch_size个tensor分开进行可视化和解码
for i in range(1,batch_size):
#用permute方法改变tensor的维度顺序,从batch_size*channels*width*height转为batch_size*width*height*channels
#取四维数组的第一维第i个元素,即width*height*channels得图片,并将其转移到cpu上后转换为numpy数组
plot.imshow(imgs.permute((0,2,3,1))[i].cpu().numpy())
#显示图片
plot.show()
#解码
pre_str,tar_str = myDecode(preds[i],labels[i])
#打印
print('pre_str:{}||tar_str:{}'.format(pre_str,tar_str))
train()