承接上一篇:PyTorch 入门实战(三)——Dataset和DataLoader
PyTorch入门实战
1.博客:PyTorch 入门实战(一)——Tensor
2.博客:PyTorch 入门实战(二)——Variable
3.博客:PyTorch 入门实战(三)——Dataset和DataLoader
4.博客:PyTorch 入门实战(四)——利用Torch.nn构建卷积神经网络
5.博客:待更新...
目录
一、概念
1.需要声明的是构建卷积神经网络需要有一定的面向对象基础,因为所有建立的模型结构都是继承自nn.Module这个基类所完成的
2.我们需要新建一个子类,并且构造函数和前向传播等方法需要被重写才能实现自己编写的网络
3.我们还需要知道torch中卷积层,池化层,全连接层等部分的编写方法和拼接方式
二、使用nn.Module创建一个网络框架
1.声明一个类,并继承自nn.Module:
class testNet(nn.Module):2.定义构造函数,例如我们建立一个用于分类的网络,类别数是10:
class testNet(nn.Module):
def __init__(self, num_classes=10):3.初始化方法使用父类的方法即可,super这里指的就是nn.Module这个基类,第一个参数是自己创建的类名:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络4.我们还需要定义自己的前向传播函数,注意forward函数需要有返回值:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
def forward(self,x):
#定义自己的前向传播方式
return x5.到目前为止,我们基本上算是搭了一个具体的框架,但是里面没有“肉”,接下来就讲解如何填“肉”~
三、利用PyTorch卷积模块填充网络框架
1.卷积层nn.Con2d()
常用参数:
- in_channels:输入通道数(深度)
- out_channels:输出通道数(深度)
- kernel_size:滤波器(卷积核)大小,宽和高相等的卷积核可以用一个数字表示,例如kernel_size=3;否则用不同数字表示,例如kernel_size=(5,3)
- stride:表示滤波器滑动的步长
- padding:是否进行零填充,padding=0表示四周不进行零填充,padding=1表示四周进行1个像素点的零填充
- bias:默认为True,表示使用偏置
- groups:groups=1表示所有输入输出是相关联的;groups=n表示输入输出通道数(深度)被分割为n份,并分别对应,且需要被groups整除
- (dilation:卷积对输入的空间间隔,默认为dilation=1)
举个例子,构建一个输入通道为3,输出通道为64,卷积核大小为3x3,四周进行1个像素点的零填充的conv1层:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
def forward(self,x):
#定义自己的前向传播方式
return x除此之外,我们还需要在forward函数里使用conv1构建传播方法:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
return out这样一个只含有一个卷积层的网络就搭建好了。
2.池化层——最大值池化nn.MaxPool2d()和均值池化nn.AvgPool2d(),
常用参数:
- kernel_size、stride、padding、dilation在卷积层部分定义和这里一致
- return_indices:表示是否返回最大值的下标,默认为False,即不返回
- ceil_mode:默认为False,即不使用方格代替层结构
- (均值池化函数中)count_include_pad:默认为True,表示包含零填充
举个例子,构建一个卷积核大小为2x2,步长为2的pool1层,并且加入到forward中:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.pool1(out)
return out事实上,池化层可以不必紧跟在卷积层之后,中间可以加入激活层和BatchNorm层,甚至可以在多个卷积操作后添加池化操作
3.加快收敛速度一一批标准化层nn.BatchNorm2d()
常用参数为:
- num_features:输入通道数(深度)
- eps:为数值稳定性而添加到分母的值, 默认值为1e-5
- momentum:用于running_mean和running_var计算的值;对于累积移动平均值(即简单平均值),可以设置为“无”。 默认值为0.1
- affine:当设置为True时,该模块具有可学习的仿射参数。 默认为True
- track_running_stats:当设置为True时,该模块跟踪运行的均值和方差,当设置为False时,该模块不跟踪这样的统计数据,并且总是在训练和评估模式。 默认为True
举个例子,构建一个输入通道为64的BN1层,与卷积层输出通道数64对应,并加入到forward中:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.pool1(out)
return out4.增加网络的非线性——激活函数nn.ReLU(True)
参数:
- inplace:可以选择就地进行操作。 默认值为False
因此设置为True的意义就是改变当前的原始对象
ReLU,线性整流函数(Rectified Linear Unit),定义如下:
![]()

举个例子,在卷积层(或BN层)之后,池化层之前,添加激活函数,并加入到forward中:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
return out5.利用nn.Sequential()按顺序构建网络
(1)利用add_module()函数添加层,第一个参数是层名,第二个参数是实现方法
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2可以看到layer2里有四个部分:卷积层conv2,批标准化层BN2,激活函数relu2和最大池化层pool2
不要忘记forward函数里添加,只不过变得简单了,其实博主也建议利用Sequential()的方式
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
out = self.layer2(out)
return out(2)直接在Sequential()里写:
self.layer3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)forward函数不要忘记加上
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2
self.layer3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
out = self.layer2(out)
out = self.layer3(out)
return out6.线性分类器(全连接层)——线性回归函数nn.Linear()
y=wx+b
四个属性:
- in_features: 上层神经元个数
- out_features:本层神经元个数
- weight:权重, 形状
[out_features,in_features] - bias:偏置, 形状[out_features]
三个参数:
- in_features:上层网络神经元的个数
- out_features: 该网络层神经元的个数
- bias: 网络层是否有偏置,默认为True,且维度为[out_features]
其实Linear是一个类,在linear.py中有定义,里面的构造函数就告诉了我们一样的信息:
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()举个例子,我们设计一个分类器,in_features为128,out_features可以为我们的类别数num_classes=10
self.classifier = nn.Sequential(
nn.Linear(128,num_classes),
)注意在forward中一般需要将之前的结果,即多维度的Tensor展平成一维以便分类,可参看博主博客:
torch x = x.view(x.size(0),-1)的理解
代码为:
out = out.view(out.size(0), -1)
out = self.classifier(out)最终一个简单的分类网络如下:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2
self.layer3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)
self.classifier = nn.Sequential(
nn.Linear(128,num_classes),
)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out7.防止过拟合——nn.Dropout()
参数:
- p:元素归零的概率。 默认值为0.5
- inplace:如果设置为True,将就地执行此操作。 默认值为False
函数功能的解释为:
在训练期间,使用伯努利分布的样本随机地将输入张量的一些元素归零:p使得在每个前向呼叫中随机化零元素。
事实证明,这是一种有效的正则化技术,可以防止神经元的共同适应,如“通过阻止特征检测器的共同适应改善神经网络”所述。
通俗易懂地,就是使神经元部分失活,即在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,本次训练过程中不更新权值,也不参与神经网络的计算,但是它的权重得保留下来。
实际上,分类器如果想达到好的效果,可以加上多个激活层和Dropout的组合操作,再得出结果,例如:
self.classifier = nn.Sequential(
nn.Linear(128,256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256,num_classes),
)最终的网络为:
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2
self.layer3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)
self.classifier = nn.Sequential(
nn.Linear(128,256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256,num_classes),
)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out四、自己写一个VGG-16带有BatchNorm层的网络
1.VGG-16(含有BN层)的网络架构:
VGG16(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace)
(6): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(7): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(9): ReLU(inplace)
(10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(12): ReLU(inplace)
(13): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(14): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(16): ReLU(inplace)
(17): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(19): ReLU(inplace)
(20): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(21): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(22): ReLU(inplace)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(26): ReLU(inplace)
(27): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(28): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(29): ReLU(inplace)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(32): ReLU(inplace)
(33): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(36): ReLU(inplace)
(37): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(38): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(39): ReLU(inplace)
(40): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(41): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(42): ReLU(inplace)
(43): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(44): AvgPool2d(kernel_size=1, stride=1, padding=0)
)
(classifier): Sequential(
(0): Linear(in_features=512, out_features=4096, bias=True)
(1): ReLU(inplace)
(2): Dropout(p=0.5)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace)
(5): Dropout(p=0.5)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)2.其实这个是print出来的。那么我们想得到这样的结构,需要写出这样一个网络结构,博主的代码如下:
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
#1
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
#2
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#3
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
#4
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#5
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#6
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#7
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#8
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#9
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#10
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#11
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#12
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#13
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.AvgPool2d(kernel_size=1,stride=1),
)
self.classifier = nn.Sequential(
#14
nn.Linear(512,4096),
nn.ReLU(True),
nn.Dropout(),
#15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
#16
nn.Linear(4096,num_classes),
)
#self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out3.创建VGG16类对象再打印即可:
if __name__ == '__main__':
import torch
#使用gpu
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
net = VGG16().to(device)
print(net)代码整体为:
import torch.nn as nn
class VGG16(nn.Module):
def __init__(self, num_classes=10):
super(VGG16, self).__init__()
self.features = nn.Sequential(
#1
nn.Conv2d(3,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
#2
nn.Conv2d(64,64,kernel_size=3,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#3
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
#4
nn.Conv2d(128,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#5
nn.Conv2d(128,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#6
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
#7
nn.Conv2d(256,256,kernel_size=3,padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#8
nn.Conv2d(256,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#9
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#10
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
#11
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#12
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
#13
nn.Conv2d(512,512,kernel_size=3,padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.AvgPool2d(kernel_size=1,stride=1),
)
self.classifier = nn.Sequential(
#14
nn.Linear(512,4096),
nn.ReLU(True),
nn.Dropout(),
#15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
#16
nn.Linear(4096,num_classes),
)
#self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
class testNet(nn.Module):
def __init__(self, num_classes=10):
super(testNet, self).__init__()
#定义自己的网络
self.conv1 = nn.Conv2d(3,64,kernel_size=3,padding=1)
self.BN1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(True)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2)
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(64,64,kernel_size=3,padding=1))
layer2.add_module('BN2',nn.BatchNorm2d(64))
layer2.add_module('relu2',nn.ReLU(True))
layer2.add_module('pool2',nn.MaxPool2d(kernel_size=2,stride=2))
self.layer2 = layer2
self.layer3 = nn.Sequential(
nn.Conv2d(64,128,kernel_size=3,padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
)
self.classifier = nn.Sequential(
nn.Linear(128,256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256,num_classes),
)
def forward(self,x):
#定义自己的前向传播方式
out = self.conv1(x)
out = self.BN1(out)
out = self.relu1(out)
out = self.pool1(out)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
if __name__ == '__main__':
import torch
#使用gpu
use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
net = VGG16().to(device)
print(net)结果为:
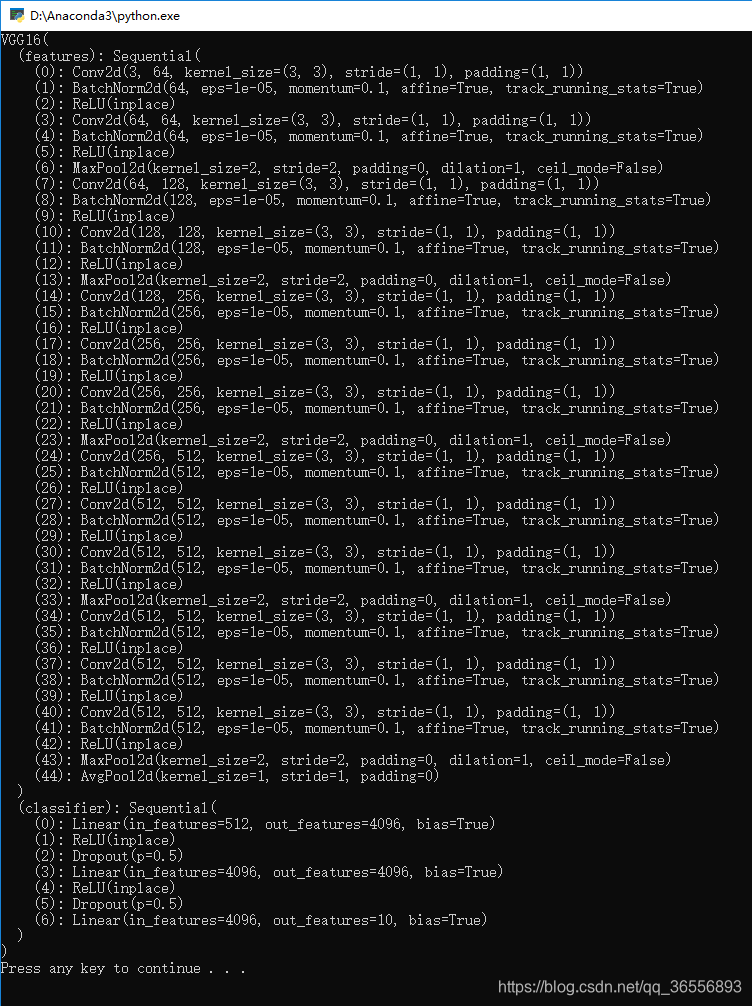
五、总结
1.nn.Module是一个基类,需要派生一个子类构造自己的网络,需要改写的方法有__init__,forward等,nn.Sequential()函数按照定义顺序构建网络。
2.nn中各种模块的使用需要注意输入输出的衔接以及顺序。
3.forward函数中的层层之间的输入输出的大小也要注意匹配