对于网站流量指标统计,一般可以分为如下维度
- 统计每一天的页面访问量
- 统计每一天的独立访客数(按人头数)
- 统计每一天的独立会话数
- 按访客地域统计
- 按统计访客ip地址
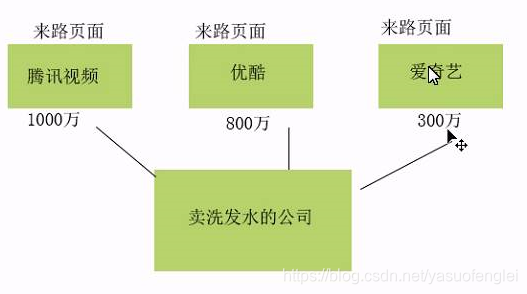
- 按来路页面分析
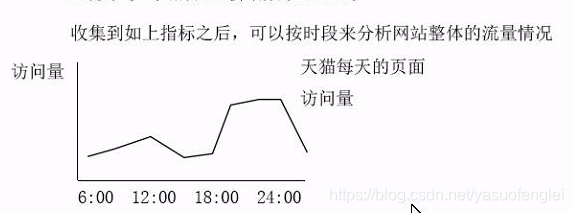
收集到如上指标之后,可以按时段来分析网站整体的情况
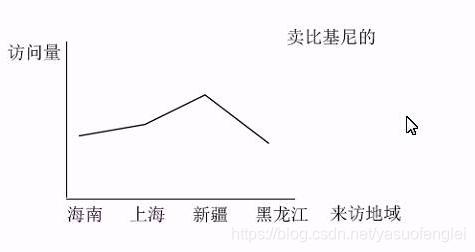
本项目统计的指标总结如下
- PV,页面访问量。用户点击一次页面,就算做一个PV,刷新操作也算。我们会统计一天内总的PV。
- UV,独立访客数。按人头来统计,我们会统计一天内有多少不同的用户来访问网站。处理思路:当一名用户访问网站时,后台会为此用户生成一个用户id(uvid),然后将uvid存到用户浏览器的cookie里,待下次此用户访问时,会携带此uvid信息。所以这个指标实际就是统计一天之内有多少不同的uvid。
- VV,独立会话(Session)数。统计一天之内有多少不同的会话,产生新会话的条件:1.关闭浏览器,再次打开,会产生一个新会话。2过了会话的操作超时时间(通常半小时),会产生一个新会话。实现思路:当产生一个新会话时,后台会为此会话生成一个会话id(ssid),然后存到cookie里。所以统计VV,实际上就是统计一天之内有多少不同的ssid。
- BR,页面跳出率(跳出会话数/VV总的会话数)。跳出会话指的是:只产生一次访问行为的会话。所以BR这个指标可以衡量网站的优良性。这个指标越高,说明对用户的吸引力越低,则需要改进。
- NewCust,新增用户数。今天的某个用户在历史数据中从未 出现过,则此用户算作一个新增用户。统计今天的uvid在历史数据中没有出现过的数量。
- NewIp,新增IP数。统计今天的ip在历史数据中未出现过的个数。
- AvgDepp,平均会话访问深度。AvgDeep=总的会话访问深度/总的会话数(VV)。其中,总的会话访问深度=每个会话访问深度求和,每一个会话的访问深度=访问多少不同的url地址。
- AvgTime,平均的会话访问时长。AvgTime=总的会话访问时长/总的会话数(VV)。其中,总的会话时长=每个会话时长求和。
我们可以统计获取打开页面时的时间戳,统计出每个会话的总的访问时长。但是在生产环境,计算的理论值要小于真实值,因为最后一个页面的停留时长无法获取。
统计每个会话的总时长,即:Max TimeStamp-Min TimeStamp。
数据的埋点和采集

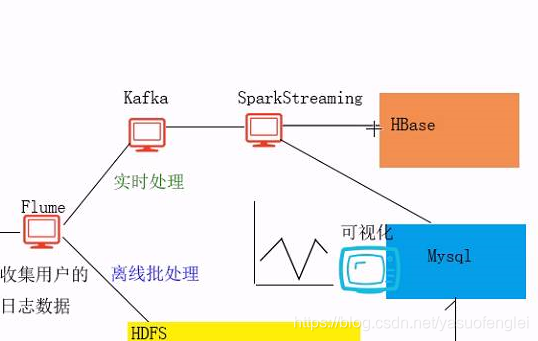
项目架构
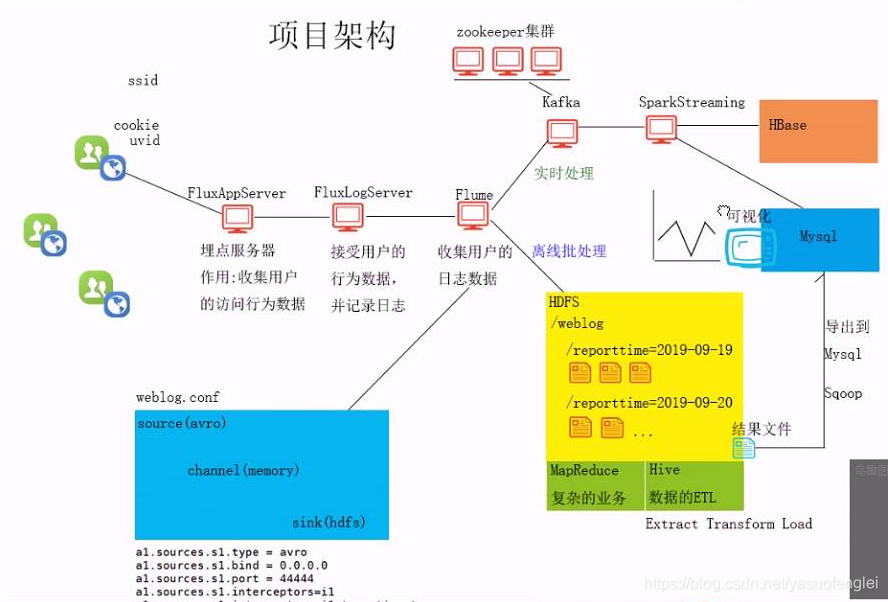
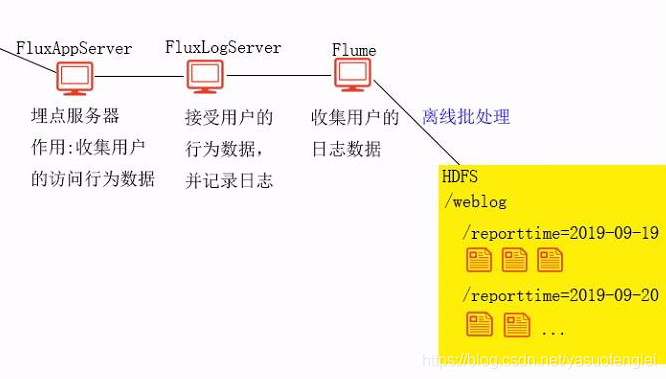
离线批处理可采用:MapReduce,Hive 数据的ETL(Extract Transform Load)
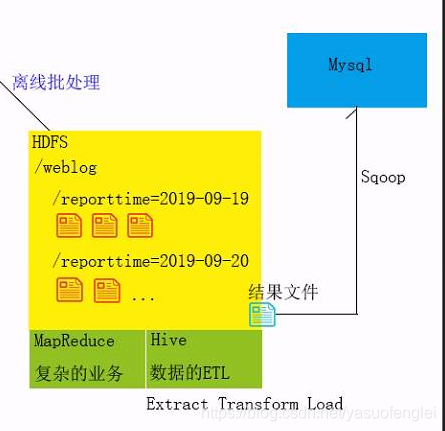
结果文件导出到数据库。做数据可视化。前端通过从数据库提取数据。

flume配置
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 44444
a1.sources.s1.interceptors=i1
a1.sources.s1.interceptors.i1.type=timestamp
a1.channels.c1.type = memory
#配置flume的通道容量,表示最多1000个Events事件。在生产环境 ,建议在5万-10万
a1.channels.c1.capacity = 1000
#批处理大小,生产环境建议在1000以上。(capacity和transactionCapacity )这两个参数决定了Flume的吞吐能力
a1.channels.c1.transactionCapacity = 100
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://hadoop01:9000/weblog/reporttime=%Y-%m-%d
//按时间周期滚动生成一人和。生产环境,建议在1小时及以上。避免生成大量小文件。
a1.sinks.k1.hdfs.rollInterval=30
#按文件大小滚动生成新文件。默认是1kb。如果是0,表示不按此条件滚动
a1.sinks.k1.hdfs.rollSize=0
#按文件中行数滚动。默认是10行
a1.sinks.k1.hdfs.rollCount=0
#Flume在HDFS生成文件时的格式,1默认格式是二进制格式。2DataStream
a1.sinks.k1.hdfs.fileType=DataStream
a1.sources.s1.channels = c1
a1.sinks.k1.channel =c1
启动flume
…/bin/flume-ng agent -n a1 -c …/conf/ -f weblog.conf -Dflume.root.logger=INFO,console
Hive做离线数据处理
- 建立总表(外部表+分区表)。加载和管理所有的字段数据,比如url,urlname,color…等
- 为总表添加分区信息
- 建立清洗表(内部表),清洗出有用的业务字段。
- 从总表中将清洗后的字段数据插入到清洗表。
- 建立业务表,用于存储统计后的各个指标,本项目的pv,uv,vv…
- 总表建表语句:
create external table flux (url string,urlname string,title string,chset string,scr string,col string,lg string,je string,ec string,fv string,cn string,ref string,uagent string,stat_uv string,stat_ss string,cip string) PARTITIONED BY (reportTime string) row format delimited fields terminated by ‘|’ location ‘/weblog’;
- 数据清洗表
create table dataclear(reporttime string,url string,urlname string,uvid string,ssid string,sscount string,sstime string,cip string) row format delimited fields terminated by ‘|’;
插入清洗数据
insert overwrite table dataclear
select reporttime,url,urlname,stat_uv,split(stat_ss,"")[0],split(stat_ss,"")[1],split(stat_ss,"_")[2],cip from flux;
- 创建业务表
create table tongji(reportTime string,pv int,uv int,vv int, br double,newip int, newcust int, avgtime double,avgdeep double) row format delimited fields terminated by ‘|’;
- 最终统计表插入数据语句:
insert overwrite table tongji select ‘2019-09-19’,tab1.pv,tab2.uv,tab3.vv,tab4.br,tab5.newip,tab6.newcust,tab7.avgtime,tab8.avgdeep from (select count() as pv from dataclear where reportTime = ‘2019-09-19’) as tab1,(select count(distinct uvid) as uv from dataclear where reportTime = ‘2019-09-19’) as tab2,(select count(distinct ssid) as vv from dataclear where reportTime = ‘2019-09-19’) as tab3,(select round(br_taba.a/br_tabb.b,4)as br from (select count() as a from (select ssid from dataclear where reportTime=‘2019-09-19’ group by ssid having count(ssid) = 1) as br_tab) as br_taba,(select count(distinct ssid) as b from dataclear where reportTime=‘2019-09-19’) as br_tabb) as tab4,(select count(distinct dataclear.cip) as newip from dataclear where dataclear.reportTime = ‘2019-09-19’ and cip not in (select dc2.cip from dataclear as dc2 where dc2.reportTime < ‘2019-09-19’)) as tab5,(select count(distinct dataclear.uvid) as newcust from dataclear where dataclear.reportTime=‘2019-09-19’ and uvid not in (select dc2.uvid from dataclear as dc2 where dc2.reportTime < ‘2019-09-19’)) as tab6,(select round(avg(atTab.usetime),4) as avgtime from (select max(sstime) - min(sstime) as usetime from dataclear where reportTime=‘2019-09-19’ group by ssid) as atTab) as tab7,(select round(avg(deep),4) as avgdeep from (select count(distinct urlname) as deep from dataclear where reportTime=‘2019-09-19’ group by ssid) as adTab) as tab8;