本文是作者 诸葛子房 投稿,欢迎大家投放原创优质稿件!
一、背景
相信大家做过实时指标统计的,肯定会遇到一个问题,算的指标是不是对的呢?pv、uv、dau、gmv、订单等等统计数据,但是怎么知道自己算的gmv是不是正确的呢?
二、实时数据统计方案
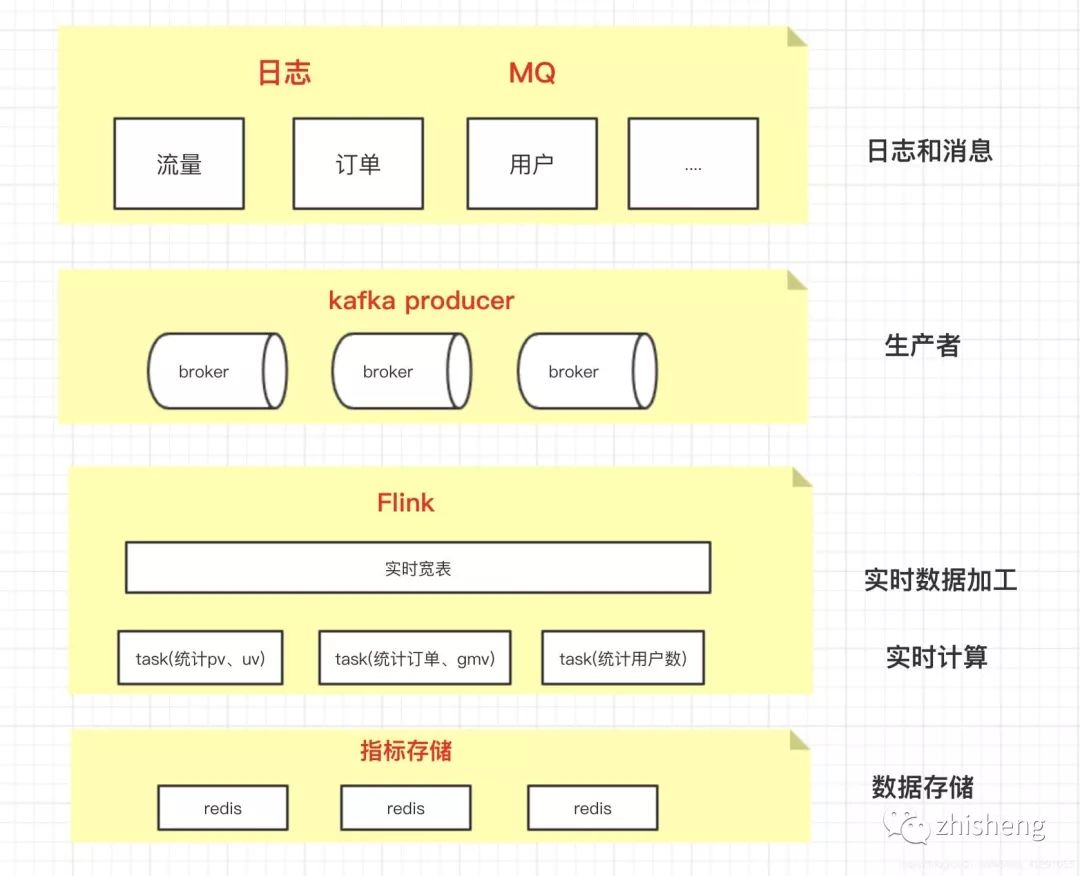
上述流程图描述了一般的实时数据计算流程,从消息的接收(kafka)、处理、计算(Flink),以及最终的存储(redis),最后查询出redis中的数据即可提供给大屏、看板等前端使用。
但是在整个过程中,不得不思考一下,最后计算出来的存储在redis中指标数据是不是正确的呢?怎么能给用户或者老板一个信服的理由呢?相信这个问题一定是困扰所有做实时数据开发的朋友。
比如说:离线的同事说离线昨天的数据订单是1w,实时昨天的数据确实2w,存在这么大的误差,到底是实时计算出问题了,还是离线出问题了呢?
三、解决方案
还是拿上面离线和实时的订单数据为例,两者不一致。离线的同事说,这边有明细数据,可以对,但是实时这边只有redis的统计结果数据,肯定是没办法说服别人的。因此,对于上图中加工的实时宽表数据,可以进行持久化,进行存储。
这样,实时数据也有明细数据,就可以和离线数据进行比对了,到底是日志丢失还是消息没有发送或者计算的业务逻辑有问题,就能够一目了然。
这就需要对flink加工的实时宽表进行存储了,这边考虑两种解决方案。
(1)实时宽表数据存储至elasticsearch

但是有一些朋友可能会说,es对应的sqlcount、group语法操作,非常复杂,况且也不是用来做线上服务,而只是用与对数,所以时效性也不需要完全考虑。
(2)实时宽表数据存储至hdfs,通过hive进行查询

优点:
a.学习成本低、会sql的基本就可以了
b.可以和离线表数据进行关联查询,容易找出两张表的数据差异
四、总结
实时计算能给提供给用户查看当前的实时统计数据,但是数据的准确性确实一个很大的问题,如何说服用户或者领导数据计算是没有问题的,就需要和其他的数据提供方进行比对了。问题的关键就在于,只要有明细数据,就可以和任意一方进行比对,毕竟有明细数据。不服?我们就对一对啊。明细数据的存储、设计也很有讲究,可以和离线或者其他提供方的数据字段进行对其,这样就非常方便进行比对了,而采用hive这种方式又是最简便的方式了,毕竟大多数人都是会sql的,无论开发人员还是数据人员或者BI人员。
原文链接地址:https://blog.csdn.net/weixin_43291055/article/details/102594978
END
关注我
