-
12.5MB
【问题描述】
在计算机存储中,12.5MB是多少字节?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。1Byte=8Bit,它们之间存在着换算关系。bit中文叫「位/比特」,是计算机中存储数据的最小单位,它的值是0或1;Byte中文叫「字节」,是计算机文件大小的基本计算单位。
1B(字节)=8bit(位)
1KB=1024B
1MB=1024KB
1GB=1024M
1TB=1024Gres = 12.5 * 1024 * 1024 print(res)13107200
-
最多边数
【问题描述】
一个包含有2019个结点的有向图,最多包含多少条边?(不允许有重边)
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。设结点数为n
无向图边数:n * (n - 1) / 2
有向图边数:n * (n - 1)
res = 2019 * (2019 - 1) print(res)4074342
问题描述
一个包含有2019个结点的无向连通图,最少包含多少条边?
答案提交
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。答案:2018
解决办法:一个具有n个节点的无向连通图,其最少含有的边为n-1(其实就是这个图的生成树)。 -
单词重排
【问题描述】
将LANQIAO中的字母重新排列,可以得到不同的单词,如LANQIAO、AAILNOQ等,注意这7个字母都要被用上,单词不一定有具体的英文意义。
请问,总共能排列如多少个不同的单词。
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。首先利用递归的思想去求所有的组合结果,然后利用**set()**集合去重。
- 先确定整个字符串的第一个字母是谁,对于长度为n的字符串吗,共有n种情况;
- 然后,问题就简化成从 返回的字符串中的字母的排列组合 变成了 返回第一个字母+除去第一个字母外的字符串的排列组合 ,类似于分治法的思想,解决一个大问题很难解决,我们就去解决它的子问题,利用子问题去解决大问题,其实就是递归思想。
def perm(s=''): # 默认参数为空字符串 if len(s) <= 1: return s s1 = set() # 集合去重 for i in range(len(s)): for j in perm(s[0:i] + s[i+1:]): # 去除一个字符剩下的串的排列组合 s1.add(s[i] + j) # 存储排列的字符串,集合特性自动去重 return s1 def main(): s = 'LANQIAO' s1 = perm(s) # print(s1) print(len(s1)) # 2520 if __name__ == '__main__': main()上边为python模块的正规写法,考试时建议不要这么干,直接写就行,这里吐槽一下IDLE,真难用,而且考试还要用!
考试时这样写就行:
def perm(s=''): # 默认参数为空字符串 if len(s) <= 1: return s s1 = set() # 集合去重 for i in range(len(s)): for j in perm(s[0:i] + s[i+1:]): # 去除一个字符剩下的串的排列组合 s1.add(s[i] + j) # 存储排列的字符串,集合特性自动去重 return s1 print(len(perm('LANQIAO'))) -
括号序列
【问题描述】
由1对括号,可以组成一种合法括号序列:()。
由2对括号,可以组成两种合法括号序列:()()、(())。
由4对括号组成的合法括号序列一共有多少种?
【答案提交】
这是一道结果填空的题,你只需要算出结果后提交即可。本题的结果为一个整数,在提交答案时只填写这个整数,填写多余的内容将无法得分。首先就四对括号,那么手动暴力破解:
- 深度为1:()()()() 1
- 深度为2:(())(()) (())()() ()(())() ()()(()) (()())() ()(()()) (()()()) 7
- 深度为3:((()))() ()((())) ((()())) (()(())) ((())()) 5
- 深度为4:(((()))) 1
一共 1 + 7 + 5 + 1 = 14 种
其次代码当然也是可以解决的!
def f(left, right): # 利用递归解决 global ans if left == 0 or right == 0: # 无论左括号用完还是右括号匹配完就结束函数 ans += 1 # 方法加1 return f(left - 1, right) # 先用一个左括号 if left < right: # 检测左括号数目如果小于右括号数目,则使用右括号 f(left, right - 1) ans = 0 f(4,4) # 一共4对括号 print(ans) -
反倍数
【问题描述】
给定三个整数 a, b, c,如果一个整数既不是 a 的整数倍也不是 b 的整数倍还不是 c 的整数倍,则这个数称为反倍数。
请问在 1 至 n 中有多少个反倍数。
【输入格式】
输入的第一行包含一个整数 n。
第二行包含三个整数 a, b, c,相邻两个数之间用一个空格分隔。
【输出格式】
输出一行包含一个整数,表示答案。
【样例输入】
30
2 3 6
【样例输出】
10
【样例说明】
以下这些数满足要求:1, 5, 7, 11, 13, 17, 19, 23, 25, 29。
【评测用例规模与约定】
对于 40% 的评测用例,1 <= n <= 10000。
对于 80% 的评测用例,1 <= n <= 100000。
对于所有评测用例,1 <= n <= 1000000,1 <= a <= n,1 <= b <= n,1 <= c <= n。很简单,这里只说一下处理输入数据时的问题。
首先input()是输入数据,类型为字符串,我们先strip()一下去掉左右两边的空白,结果仍为一个字符串;然后再用split()分隔(默认是一空白分割),返回的是一个列表;之后再用map()对列表数据进行int格式化成整形,返回的是一个生成器格式数据;最后用list()一次性全部接收生成器中的所有元素,类型为列表。
n = int(input()) lst = list(map(int, input().strip().split())) count = 0 # arr = [] for i in range(1, n+1): if i % lst[0] !=0 and i % lst[1] != 0 and i % lst[2] != 0: count += 1 arr.append(i) print(count) # print(arr) -
凯撒加密
【问题描述】
给定一个单词,请使用凯撒密码将这个单词加密。
凯撒密码是一种替换加密的技术,单词中的所有字母都在字母表上向后偏移3位后被替换成密文。即a变为d,b变为e,...,w变为z,x变为a,y变为b,z变为c。
例如,lanqiao会变成odqtldr。
【输入格式】
输入一行,包含一个单词,单词中只包含小写英文字母。
【输出格式】
输出一行,表示加密后的密文。
【样例输入】
lanqiao
【样例输出】
odqtldr
【评测用例规模与约定】
对于所有评测用例,单词中的字母个数不超过100。s = input() res = '' for i in s: """加上 x y z 这三种特殊情况""" res += chr(((ord(i) - ord('a') + 3) % 26) + ord('a')) print(res) -
螺旋
【问题描述】
对于一个 n 行 m 列的表格,我们可以使用螺旋的方式给表格依次填上正整数,我们称填好的表格为一个螺旋矩阵。
例如,一个 4 行 5 列的螺旋矩阵如下:
1 2 3 4 5
14 15 16 17 6
13 20 19 18 7
12 11 10 9 8
【输入格式】
输入的第一行包含两个整数 n, m,分别表示螺旋矩阵的行数和列数。
第二行包含两个整数 r, c,表示要求的行号和列号。
【输出格式】
输出一个整数,表示螺旋矩阵中第 r 行第 c 列的元素的值。
【样例输入】
4 5
2 2
【样例输出】
15
【评测用例规模与约定】
对于 30% 的评测用例,2 <= n, m <= 20。
对于 70% 的评测用例,2 <= n, m <= 100。
对于所有评测用例,2 <= n, m <= 1000,1 <= r <= n,1 <= c <= m。def make_mat(x, y): global count while count <= m * n: while y < m and mat[x][y] == 0: # y<m这个条件一定要放在mat[x][y]===0前边提前判断,否则,先判断是否值为0时会导致循环结束时的y值为m而报数组越界的错误 mat[x][y] = count y += 1 count += 1 y -= 1 # 上个循环结束后,y的值为m,需要减一,否则越界 x += 1 # 上一行读完后,行值加1 while x < n and mat[x][y] == 0: # 下边同理 mat[x][y] = count x += 1 count += 1 x -= 1 # 上个循环结束后x值为n,要减一 y -= 1 # 最后一列读完,往左推一列 while y >= 0 and mat[x][y] == 0: mat[x][y] = count y -= 1 count += 1 y += 1 # 同理 x -= 1 while x >= 0 and mat[x][y] == 0: mat[x][y] = count x -= 1 count += 1 x += 1 # 同理 y += 1 n, m = list(map(int, input().split())) r, c = list(map(int, input().split())) count = 1 mat = [[0] * m for i in range(n)] # 注意二维数组的定义方法,不然会导致编一个位置其他行的相同位置也会随之改变 make_mat(0, 0) # for line in mat: # print(*line) print(mat[r - 1][c - 1]) -
摆动序列
【问题描述】
如果一个序列的奇数项都比前一项大,偶数项都比前一项小,则称为一个摆动序列。即 a[2i]<a[2i-1], a[2i+1]>a[2i]。
小明想知道,长度为 m,每个数都是 1 到 n 之间的正整数的摆动序列一共有多少个。
【输入格式】
输入一行包含两个整数 m,n。
【输出格式】
输出一个整数,表示答案。答案可能很大,请输出答案除以10000的余数。
【样例输入】
3 4
【样例输出】
14
【样例说明】
以下是符合要求的摆动序列:
2 1 2
2 1 3
2 1 4
3 1 2
3 1 3
3 1 4
3 2 3
3 2 4
4 1 2
4 1 3
4 1 4
4 2 3
4 2 4
4 3 4
【评测用例规模与约定】
对于 20% 的评测用例,1 <= n, m <= 5;
对于 50% 的评测用例,1 <= n, m <= 10;
对于 80% 的评测用例,1 <= n, m <= 100;
对于所有评测用例,1 <= n, m <= 1000。具体详解可参考https://blog.csdn.net/the_ZED/article/details/106029631这篇的博主是用c写的,我用python写的代码在下边。
这个题用普通的搜索肯定很难解决,而且造成递归树过大。这时候我们通常可以用记忆化搜索或动态规划来解决。首先,动态规划解决的话我们首先要做的就是寻找状态转移方程。有两个关键的地方:
-
位置的奇偶会影响当前位置上的取值规则;
- 所取值必须停在区间[1,n]中。
对于第一点的规则就是奇数项都比前一项大,偶数项都比前一项小,这个我们可以通过用一个二维状态(
dp[i][j])来进行标记。比如对于dp[i][j]=x,其具体的逻辑意义是:在第i个位置上选择数字j时共有x个方案。怎么来得到dp[i][j]呢?这显然和i的奇偶性有关:当i是奇数时,由于其比前面的每一项都大,因此对于dp[i][j]而言,其前面可以存在的合法项就有:dp[i-1][1]、dp[i-1][2]、dp[i-1][3]、……、dp[i-1][j-1]。换言之dp[i][j]=dp[i-1][1]+dp[i-1][2]+dp[i-1][3]+……+dp[i-1][j-1];当i是偶数时,由于其比前面的每一项都小,因此对于dp[i][j]而言,其前面可以存在的合法项就有:dp[i-1][j+1]、dp[i-1][j+2]、dp[i-1][j+3]、……、dp[i-1][n]。换言之dp[i][j]=dp[i-1][j+1]+dp[i-1][j+2]+dp[i-1][j+3]+……+dp[i-1][n];
于是我们就得到了本题的状态转移方程为:
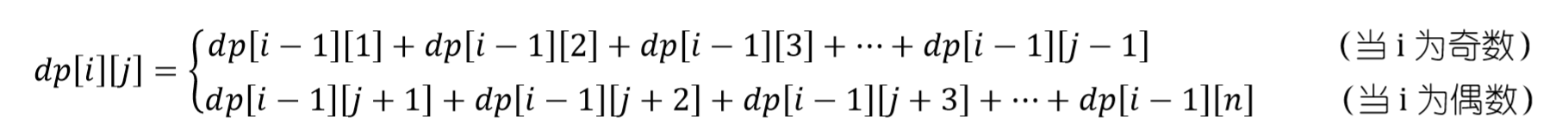
最后还需要对dp数组进行初始化。试想,对于序列的首项而言,其并不存在所谓的“前一项”,因此在首项处可以任意取值,当然,其每个取值都只有一种方案。即:
dp[1][1]=1,dp[1][2]=1,dp[1][3]=1,……,dp[1][n]=1。
求出dp数组后怎么使用呢?要知道dp[i][j]的逻辑意义是在第i个位置上选择数字j时的方案数,那么在长度为m,取值范围为[1,n]的前提下,总的摆动序列的数量就可以用dp[m][1]+dp[m][2]+dp[m][3]+……+dp[m][n]来表示。下面直接给出基于上述思路写出的完整代码(看不太懂的减一把程序copy进pycharm然后进行debug观察变量的变化情况,非常直观,不会的可以留言,我找时间会做个详细教程):
def dp(m, n): ans = 0 temp = 0 for i in range(1, n+1): lst[1][i] = 1 # 初始化数组 for i in range(2, m+1): for j in range(1, n+1): temp = 0 if i % 2 != 0: # 奇数 for k in range(1, j): temp = (temp + lst[i-1][k]) % MOD else: # 偶数 for k in range(j+1, n+1): temp = (temp + lst[i-1][k]) % MOD lst[i][j] = temp for i in range(1, n+1): ans = (ans + lst[m][i]) % MOD return ans m, n = list(map(int, input().split())) MOD = 10000 lst = [[0] * (n+2) for i in range(m+2)] print(dp(m, n))这个代码很容易理解,但是问题也很突出,那就是在DP时,我们用到了3层循环!!!(更严格的说,其时间复杂度为
O(n3))这在m=n=1000的极限情况下超时无疑,因此我们不得不进行优化。在上面之所以用了3层循环,是因为dp[i][j]这个状态表示的是其在第i个位置上选择数字j时的方案数,这是一个“1对1”的存储模式。它导致程序在后面进行状态转移时,需要对每一个dp[x][y]进行更新维护,而更新维护的时候又是从前一次的{
dp[i-1][1],dp[i-1][2],……,dp[i-1][n]}中寻找。遍历dp[x][y]是一个二重循环,更新维护又是一重循环,因此上面的程序是一个三重循环。如果我们试图降低本程序的时间复杂度,就不得不从上面的短板中寻找突破。
一个比较直观,且容易想到的改进是:能不能对dp[i][j]这个存储模式进行更改?如果我们直接将dp[i][j]的存储模式改为“1对多”,那就相当于降低了一重循环。
现在我们就来着手实现对dp[i][j]的模式更改。由于位置i的奇偶性会影响当前位置上的取值规则,因此我们也可以将dp[i][j]的意义根据位置的奇偶性进行如下重定义:- 当i为奇数时,
dp[i][j]表示第i个数选择大于等于数j的方案数; - 当i为偶数时,
dp[i][j]表示第i个数选择小于等于数j的方案数。
这样的改变有点类似于将奇数位上的数用后缀数组来表达,而偶数位上的数用前缀数组来表达。那么此时我们的动态转移方程也会发生相应的改变,如下:
- 当i为奇数时,由于奇数项都比前一项大,那么其前一项只能是
dp[i-1][j-1]。又由于此时dp[i][j]表示的是“第i个数选择大于等于数j的方案数”,那么我们还需要额外加上当前项的后一项,即dp[i][j+1]。因此,此时dp[i][j]=dp[i-1][j-1]+dp[i][j+1]。 - 当i为偶数时,由于偶数项都比前一项小,那么其前一项只能是
dp[i-1][j+1]。又由于此时dp[i][j]表示的是“第i个数选择小于等于数j的方案数”,那么我们还需要额外加上当前项的前一项,即dp[i][j-1]。因此,此时dp[i][j]=dp[i-1][j+1]+dp[i][j-1]。
这样一来,我们就省去了上面那个算法的最内层循环,从而将时间复杂度降低到O(n2)。即使在极限情况下,改进后的算法也能从容应对。
接下来是初始化问题,我们在将
dp[i][j]存储的信息进行更改后,其意义是一个累加值(随当前位置i的奇偶性而决定累加方向)。由于首项dp[1][y]所在位置1是一个奇数,那么其累加方向是自右向左,即:dp[1][1]=n,dp[1][2]=n-1,dp[1][3]=n-2,……,dp[1][n-1]=2,dp[1][n]=1。
现在求出dp数组后又怎么使用呢?还是从dp[i][j]的逻辑意义出发:“当i为奇数时,dp[i][j]表示第i个数选择大于等于数j的方案数;当i为偶数时,dp[i][j]表示第i个数选择小于等于数j的方案数”。显然,这时候我们的结果是依赖于序列长度的奇偶性:
如果序列长度为奇数,那为了能将所有的结果都包含进来,就应该用dp[m][1]来表示该波动序列的总量;
如果序列长度为偶数,那为了能将所有的结果都包含进来,就应该用dp[m][n]来表示该波动序列的总量;下面给出改进后,本题的完整代码:
def dp(m, n): for i in range(1, n+1): lst[1][i] = n - i + 1 # 初始化数组 for i in range(2, m+1): if i % 2 != 0: # 奇数 for j in range(n, 0, -1): lst[i][j] = (lst[i-1][j-1] + lst[i][j+1]) % MOD else: # 偶数 for j in range(1, n+1): lst[i][j] = (lst[i-1][j+1] + lst[i][j-1]) % MOD return lst[m][1] if m % 2 != 0 else lst[m][n] m, n = list(map(int, input().split())) MOD = 10000 lst = [[0] * (n+2) for i in range(m+2)] print(dp(m, n)) -
-
通电
【问题描述】
2015年,全中国实现了户户通电。作为一名电力建设者,小明正在帮助一带一路上的国家通电。
这一次,小明要帮助 n 个村庄通电,其中 1 号村庄正好可以建立一个发电站,所发的电足够所有村庄使用。
现在,这 n 个村庄之间都没有电线相连,小明主要要做的是架设电线连接这些村庄,使得所有村庄都直接或间接的与发电站相通。
小明测量了所有村庄的位置(坐标)和高度,如果要连接两个村庄,小明需要花费两个村庄之间的坐标距离加上高度差的平方,形式化描述为坐标为 (x_1, y_1) 高度为 h_1 的村庄与坐标为 (x_2, y_2) 高度为 h_2 的村庄之间连接的费用为
sqrt((x_1-x_2)*(x_1-x_2)+(y_1-y_2)*(y_1-y_2))+(h_1-h_2)*(h_1-h_2)。
在上式中 sqrt 表示取括号内的平方根。请注意括号的位置,高度的计算方式与横纵坐标的计算方式不同。
由于经费有限,请帮助小明计算他至少要花费多少费用才能使这 n 个村庄都通电。
【输入格式】
输入的第一行包含一个整数 n ,表示村庄的数量。
接下来 n 行,每个三个整数 x, y, h,分别表示一个村庄的横、纵坐标和高度,其中第一个村庄可以建立发电站。
【输出格式】
输出一行,包含一个实数,四舍五入保留 2 位小数,表示答案。
【样例输入】
4
1 1 3
9 9 7
8 8 6
4 5 4
【样例输出】
17.41
【评测用例规模与约定】
对于 30% 的评测用例,1 <= n <= 10;
对于 60% 的评测用例,1 <= n <= 100;
对于所有评测用例,1 <= n <= 1000,0 <= x, y, h <= 10000。可以先学习下python版最小生成树Prim和Kruskal算法
方法一prim的两种解法:
""" 解法1 Prim类接受两个参数n,m,分别表示录入的点和边的个数(点的编号从1开始递增) 接下来是m行,每行3个数x,y,length,表示点x和点y之间存在一条长度为length的边 程序最终会打印出该无向图中的最小生成树的各个边和最小权值 """ import math class Node: """ Node类存放节点信息, node是与某个节点(实际上是用列表索引值代表的)相连接的点 length表示这两个点之间的权值 """ def __init__(self, x, y, h): self.x = x self.y = y self.h = h class Edge: """ Edge类表示边的信息 x,y表示这条边的两个顶点 length为<x,y>之间的距离 """ def __init__(self, x, y, cost): self.x = x self.y = y self.cost = cost class Prim: """Prim算法:求解无向连通图中的最小生成树 """ def __init__(self, n, adj_map): self.n = n # 输入的点个数 self.adj_map = adj_map self.cost = 0 self.node = [0 for i in range(n + 1)] # 存放所有节点之间的可达关系与距离 """图的邻接表的表示法,v是一个二维列表,其索引值代表当前节点,索引值对应的一维列表中存放的 是与以当前索引值为顶点的相连的节点信息""" self.e = [] # 存放与当前已选节点相连的边 self.vis = [False for i in range(n+1)] # 标记每个点是否被访问过,False未访问 def create(self): for i in range(1, self.n): for j in range(i+1, self.n+1): self.adj_map[i][j] = self.adj_map[j][i] = math.sqrt((self.node[i].x - self.node[j].x) ** 2 + (self.node[i].y - self.node[j].y) ** 2) + (self.node[i].h - self.node[j].h) ** 2 def graphy(self): """构建图,这里用的是邻接表""" for i in range(1, self.n+1): x, y, h = list(map(int, input().split())) self.node[i] = Node(x, y, h) self.create() def insert(self, point): self.vis[point] = True for i in range(1, self.n+1): if not self.vis[i]: self.e.append(Edge(point, i, self.adj_map[point][i])) self.e = sorted(self.e, key=lambda e: e.cost) # 把e中的所有边按边的长度从小到大排序 # for i in self.e: # print(i.cost, i.x, i.y) def run(self, start): """执行函数:求解录入的无向连通图的最小生成树""" self.insert(start) # start为选择的开始顶点 selected = 1 # exit() while selected < self.n: for i in range(len(self.e)): if not self.vis[self.e[i].y]: self.cost += self.e[i].cost self.insert(self.e[i].y) selected += 1 break return self.cost def main(): n = int(input()) adj_map = [[0] * (n+1) for i in range(n+1)] prim = Prim(n, adj_map) prim.graphy() # print(adj_map) cost = prim.run(1) print(round(cost, 2)) if __name__ == '__main__': main()import sys import math MAX = sys.maxsize class Prim: ''' prim算法求最小生成树 :param graph: 图 :return: 最小的权值 :n:点的个数 ''' def __init__(self, n, graphy): self.n = n self.cost = 0 self.v = 0 self.graphy = graphy self.lowcost = [] #记录当前顶点集合到剩下的点的最低权值,“-1”表示已访问过的点,无需访问 self.mst = [] ##记录当前被更新的最低权值来自于哪个点,相当于记录是边的起始点,lowcost的下标表示的是最低权值的终止点 def run(self): for i in range(self.n): self.lowcost.append(self.graphy[0][i]) self.mst.append(0) self.lowcost[0] = -1 for i in range(self.n-1): min = MAX for j in range(self.n): if min > self.lowcost[j] and self.lowcost[j] != -1: min = self.lowcost[j] self.v = j self.cost += min # print(f'{self.mst[self.v]}->{self.v}:{min}') self.lowcost[self.v] = -1 for k in range(self.n): if self.lowcost[k] > self.graphy[self.v][k]: self.lowcost[k] = self.graphy[self.v][k] self.mst[k] = self.v return self.cost def main(): n = int(input()) data = [list(map(int, input().split())) for i in range(n)] graphy = [[MAX] * n for i in range(n)] for i in range(n-1): for j in range(i + 1, n): graphy[j][i] = graphy[i][j] = math.sqrt((data[i][0] - data[j][0]) ** 2 + (data[i][1] - data[j][1]) ** 2) + (data[i][2] - data[j][2]) ** 2 # print(data) # print(graphy) prim = Prim(n, graphy) # cost = prim.run() cost = round(prim.run(),2) print(cost) if __name__ == '__main__': main()方法二Krukal方法:
import math class Edge: """ Edge类表示边的信息 x,y表示这条边的两个顶点 length为<x,y>之间的距离 """ def __init__(self, x, y, cost): self.x = x self.y = y self.cost = cost class UnionFindSet: """并查集类,用于连通两个节点以及判断图中的所有节点是否连通 """ def __init__(self, start, n): self.start = start # start和n分别用于指示并查集里节点的起点和终点 self.n = n self.pre = [0 for i in range(self.n - self.start + 2)] # pre数组用于存放某个节点的上级 self.rank = [0 for i in range(self.n - self.start + 2)] # rank数组用于降低关系树的高度 def init(self): """初始化并查集""" for i in range(self.start, self.n+1): self.pre[i] = i self.rank[i] = 1 def find_pre(self, x): """寻找节点x的上一级节点""" if self.pre[x] == x: return x else: self.pre[x] = self.find_pre(self.pre[x]) return self.pre[x] def is_same(self, x, y): """判断x节点和y节点是否连通""" return self.find_pre(x) == self.find_pre(y) def unite(self, x, y): """判断两个节点是否连通,如果未连通则将其连通并返回真,否则返回假""" x = self.find_pre(x) y = self.find_pre(y) if x == y: return False if self.rank[x] > self.rank[y]: """类似于平衡二叉树的概念""" self.pre[y] = x else: if self.rank[x] == self.rank[y]: self.rank[y] += 1 self.pre[x] = y return True def is_one(self): """判断整个无向图中的所有节点是否连通 """ temp = self.find_pre(self.start) for i in range(self.start+1, self.n+1): if self.find_pre(i) != temp: return False return True class Kruskal: """Kruskal算法:求解无向连通图中的最小生成树 """ def __init__(self, n, m): self.n = n # n,m分别表示输入的点和边的个数 self.m = m self.cost = 0 self.node = [0 for i in range(n + 1)] # 存放所有节点之间的可达关系与距离 self.e = [] # 存放录入的无向连通图的所有边 self.s = [] # 存放最小生成树里的所有边 self.u = UnionFindSet(1, self.n) # 并查集:抽象实现Graphnew,并完成节点间的连接工作以及判断整个图是否连通 def create(self): # print(self.node) for i in range(1, self.n): for j in range(i+1, self.n+1): self.e.append(Edge(i, j, math.sqrt((self.node[i].x - self.node[j].x) ** 2 + (self.node[i].y - self.node[j].y) ** 2) + (self.node[i].cost - self.node[j].cost) ** 2)) def graphy(self): """这里只是存储所有边的信息并按边的长度排序""" for i in range(1, self.n+1): x, y, h = list(map(int, input().split())) self.node[i] = Edge(x, y, h) self.create() self.e.sort(key=lambda e: e.cost) # for i in self.e: # print(i.h) self.u.init() def run(self): """执行函数:求解录入的无向连通图的最小生成树 """ for i in range(self.m): if self.u.unite(self.e[i].x, self.e[i].y): self.s.append(self.e[i]) if self.u.is_one(): """一旦Graphnew的连通分支数为1,则说明求出了最小生成树 """ break def print(self): print(f'构成最小生成树的边为:') edge_sum = 0 for i in range(len(self.s)): print(f'边 <{self.s[i].x},{self.s[i].y}> = {self.s[i].cost}') edge_sum += self.s[i].cost print(f'最小生成树的权值为:{edge_sum}') def main(): n = int(input()) m = int((n * (n - 1)) / 2) kruskal = Kruskal(n, m) kruskal.graphy() kruskal.run() kruskal.print() if __name__ == '__main__': main()运行结果(输出自己改一下):
4 1 1 3 9 9 7 8 8 6 4 5 4 构成最小生成树的边为: 边 <2,3> = 2.414213562373095 边 <1,4> = 6.0 边 <3,4> = 9.0 最小生成树的权值为:17.414213562373096 -
植树
【问题描述】
小明和朋友们一起去郊外植树,他们带了一些在自己实验室精心研究出的小树苗。
小明和朋友们一共有 n 个人,他们经过精心挑选,在一块空地上每个人挑选了一个适合植树的位置,总共 n 个。他们准备把自己带的树苗都植下去。
然而,他们遇到了一个困难:有的树苗比较大,而有的位置挨太近,导致两棵树植下去后会撞在一起。
他们将树看成一个圆,圆心在他们找的位置上。如果两棵树对应的圆相交,这两棵树就不适合同时植下(相切不受影响),称为两棵树冲突。
小明和朋友们决定先合计合计,只将其中的一部分树植下去,保证没有互相冲突的树。他们同时希望这些树所能覆盖的面积和(圆面积和)最大。
【输入格式】
输入的第一行包含一个整数 n ,表示人数,即准备植树的位置数。
接下来 n 行,每行三个整数 x, y, r,表示一棵树在空地上的横、纵坐标和半径。
【输出格式】
输出一行包含一个整数,表示在不冲突下可以植树的面积和。由于每棵树的面积都是圆周率的整数倍,请输出答案除以圆周率后的值(应当是一个整数)。
【样例输入】
6
1 1 2
1 4 2
1 7 2
4 1 2
4 4 2
4 7 2
【样例输出】
12
【评测用例规模与约定】
对于 30% 的评测用例,1 <= n <= 10;
对于 60% 的评测用例,1 <= n <= 20;
对于所有评测用例,1 <= n <= 30,0 <= x, y <= 1000,1 <= r <= 1000。考点:两圆之间的位置关系
首先建议先做一下这个题:判断两个圆之间的关系。
下边是本题代码:
import math class Circle: """存储每颗树的位置信息,和它的覆盖面积,并提供判断自身与另一颗树的覆盖范围的位置关系""" def __init__(self, x, y, r): self.x = x self.y = y self.r = r self.absolute_area = r ** 2 def judge_relation(self, *args): """ 判断两圆之间的关系 @args:多值参数 """ if args: # args(这里的args就是一个元组)不为空时 flag = [False for i in range(len(args))] i = 0 for circle in args: dis = math.sqrt((self.x - circle.x) ** 2 + (self.y - circle.y) ** 2) if self.r + circle.r < dis or self.r + circle.r == dis: # 外离和外切 """若两个圆属于外切和外离的情况,置flag[i]为真""" flag[i] = True i += 1 return flag else: # args为空,第一个圆,肯定不会存在与其他圆的位置关系情况,直接返回一个元组,因为后边的all()的参数必须为可迭代对象 return [True, ] class PlantTree: def __init__(self, n): self.n = n # 待植的树的棵数 self.tree = [0 for i in range(n)] # 存放每一颗树的位置信息 self.vis = [] # 存放已经种植的树 self.total_area = 0 # 已经种植的树覆盖的总面积 def init(self): for i in range(self.n): x, y, r = list(map(int, input().split())) self.tree[i] = Circle(x, y, r) self.tree.sort(key=lambda circle: circle.r, reverse=True) # 半径从大到小排序,覆盖面积最大的先种 def plant(self): for i in range(self.n): # flag = all(self.tree[i].judge_relation(*self.vis)) if all(self.tree[i].judge_relation(*self.vis)): """注意all()的参数必须是可迭代对象,vis是一个列表用*打散传入""" # 如果当前树与已种的树不会相交,则把此树放入已种树的列表。 self.vis.append(self.tree[i]) self.total_area += self.tree[i].absolute_area return self.total_area def main(): n = int(input()) plant_tree = PlantTree(n) plant_tree.init() plant_tree.plant() print(plant_tree.total_area) if __name__ == '__main__': main()
蓝桥python组模拟赛2(完结)
猜你喜欢
转载自blog.csdn.net/qq_31910669/article/details/108679544
今日推荐
周排行