如以下几张途中data为表中对应的数据信息,例如用户表,则data为name,age,sex等信息,id和信息直接存储在节点中,但是data比较大占用磁盘会导致每块磁盘存储的数据量太少,导致树的高度增大,io增多,导致查询时间增长效率较慢。但是B+tree,节点只存储主键排好序的,data只存储在叶子节点,所以每块磁盘存储的信息量就会指数增长,从而减少树的高度,增加查询效率所以主键索引是比较快的,因为data都存储在叶子节点。B+Tree辅助索引中普通节点存储的是索引的值(按照一定顺序排序),叶子节点存储id主键,找到id(主键)之后再去主键索引查找data数据。InnoDB默认数据页大小为16k 即为16384 个字节 (4+10) = 1170 个Key;即非叶子节点(一个磁盘)存储键值(扇出系数) = 16384 / (4+10) = 1170 个Key;
所以在高度h=3时,索引里检索的key为:1170^3 ≈ 16亿,即只需要3次IO就能检索16亿的key。
如果是varchar等其他字符类型,占用Page字节较大,非叶子节点存储键值会减少,相应可检索的key也减少,树高度就有可能会升高,IO会就多一次,从而导致相对变慢。一般2~4层高度大部分已经够用了。所以这就是为什么需要指定主键int自增长,如果是varchar的话,一个磁盘存储的键值就会减少,导致查询时间较长。这也是为什么主键索引效率最高,字节少占用空间少,每个磁盘存储的也多。
BTree:
BTree是为磁盘存储而专门设计的一类平衡搜索树,文件系统和数据库系统一般都采用BTree的数据结构,主要为提升排序和检索的效率。
由于BTree的所有节点都存储数据,这就限制了BTree节点拥有孩子节点个数,如果数据量特别大,会导致树的高度变高,IO就会增多。

模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存。
但如果我们想进行范围查找,查询10~79之间的数据,就需要从跟节点一个一个往下查,范围跨度越大,则磁盘IO的次数就越多,性能越差。因此在BTree的基础上就有了B+Tree。
B+Tree:
B+Tree是在BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
B+Tree相对于BTree有几点不同:
1、非叶子节点只存储键值信息。
2、所有叶子节点之间都有一个双向链指针。
3、数据记录都存放在叶子节点中。

这样索引树不用太高,就能满足需要对数据的检索需求,使查询更快速,例如:
定义一棵B+Tree,高度h = 3;
我们知道MySQL InnoDB默认数据页大小为16k;
-
MySQL root@[mysql]>show global status like 'Innodb_page_size'; -
+------------------+-------+ -
| Variable_name | Value | -
+------------------+-------+ -
| Innodb_page_size | 16384 |
假设字符集为utf8,在一个int字符类型的字段加索引(int固定占4个字节);
一个Page除去页号、页类型等10个字节(如下图);

非叶子节点存储键值(扇出系数) = 16384 / (4+10) = 1170 个Key;
所以在高度h=3时,索引里检索的key为:1170^3 ≈ 16亿,即只需要3次IO就能检索16亿的key。
如果是varchar等其他字符类型,占用Page字节较大,非叶子节点存储键值会减少,相应可检索的key也减少,树高度就有可能会升高,IO会就多一次,从而导致相对变慢。一般2~4层高度大部分已经够用了。
B+Tree主键索引:
InnoDB中主键索引的叶子节点的数据区域存储的是数据记录,辅助索引存储的是主键值。

B+Tree辅助索引:
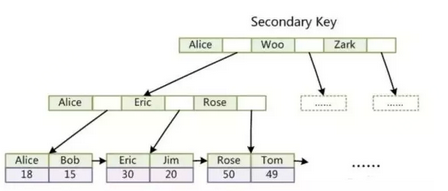
B+Tree辅助索引: