一. 索引的数据结构分类
- Hash
- B+Tree
二. Hash
-
无序的Hash表
【特点介绍】:虽然无序的Hash表可以快速的精确查询,但是不支持范围查询。若索引采用无序的Hash表,需扫描全部的数据,导致查询速度很慢;
【使用场景】:等值查询,即Key—Value场景,如:Redis; -
有序的Hash表
【特点介绍】:有序的Hash表适合查询静态数据。当进行增、删、改数据时候就会改变其结构。如:进行增操作时,新增的位置后的所有节点都要后移,成本很高。
【使用场景】:等值查询、范围查询。可做为静态存储引擎,保存静态数据。如:淘宝购物账单。
三. B+Tree
-
B-Tree
一个节点可以存储多个元素,B-Tree的树高比完全平衡二叉树整体的树高低,提高了磁盘的IO效率。 -
B+Tree
【特点介绍】:B+Tree是对B-Tree的改进。非叶子节点只存储键值信息,所有叶子节点之间都有一个链指针,数据记录都存放在叶子节点中,提高了范围查找的效率。
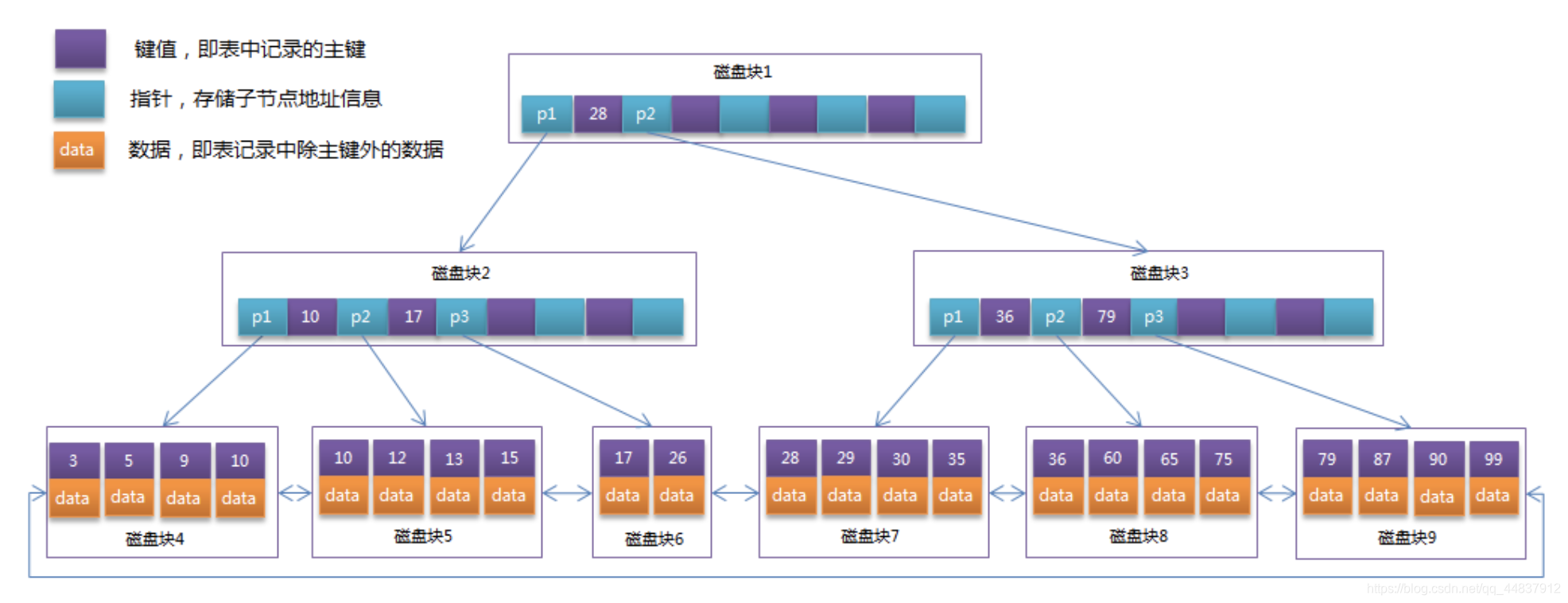
【使用场景】:Mysql的索引使用B+树,提高查询索引时的磁盘IO和范围查询效率。【注】:
B+树中一个节点为页的倍数最为合适,不是页的倍数会造成资源的浪费。
