数据结构很好的示例网站:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
该网站将数据结构图动态的分析出来了 里面有各种种类数据结构

二叉树:
二叉树会将新增的数据进行排序 小的在左侧 打的在右侧 新增时每一个节点进行判断。
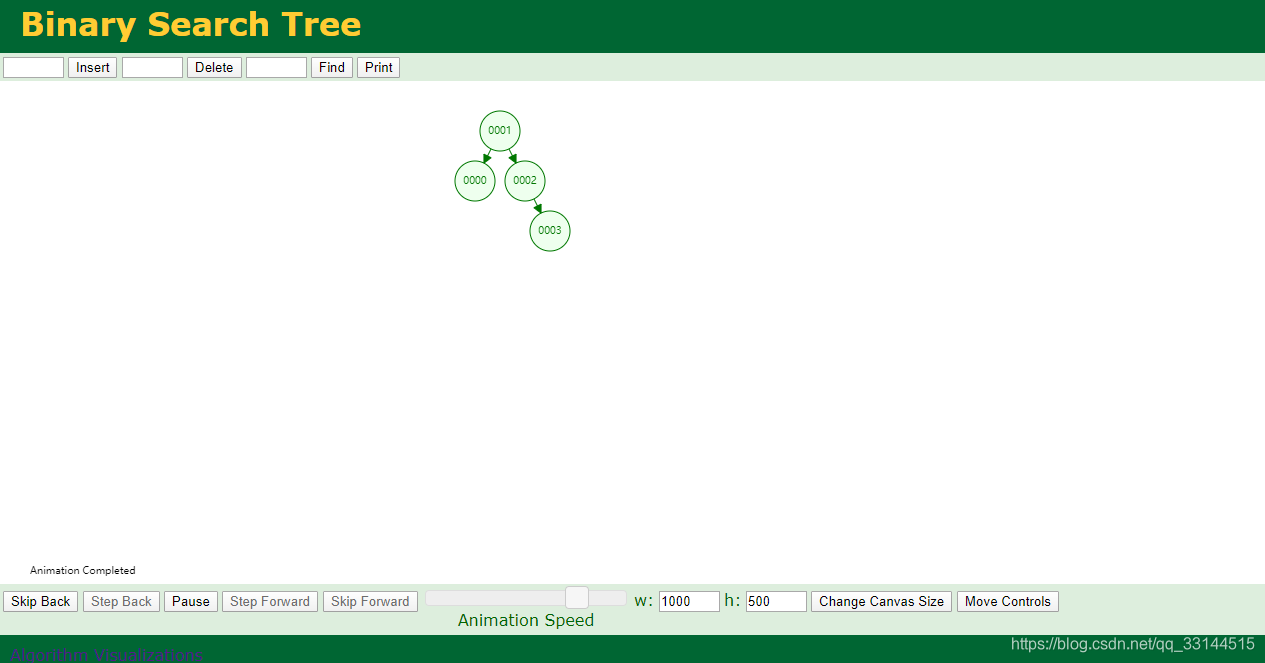
缺点:若相同都会往右侧添加。
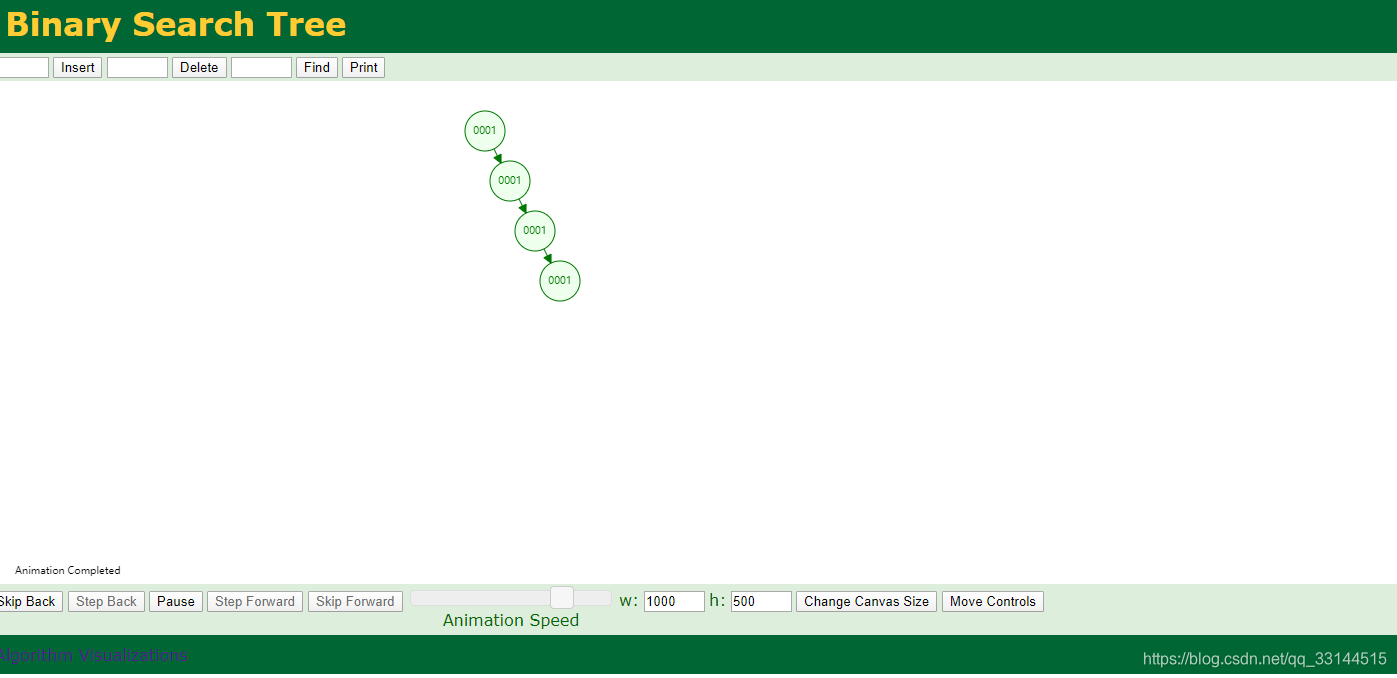
因此衍生红黑树。
红黑树:
红黑树每次新增时会进行判断 将小的添加到左侧 大的添加到右侧 相同都会往右侧进行新增然后提取数据中间部分 提取出做 分母节点。
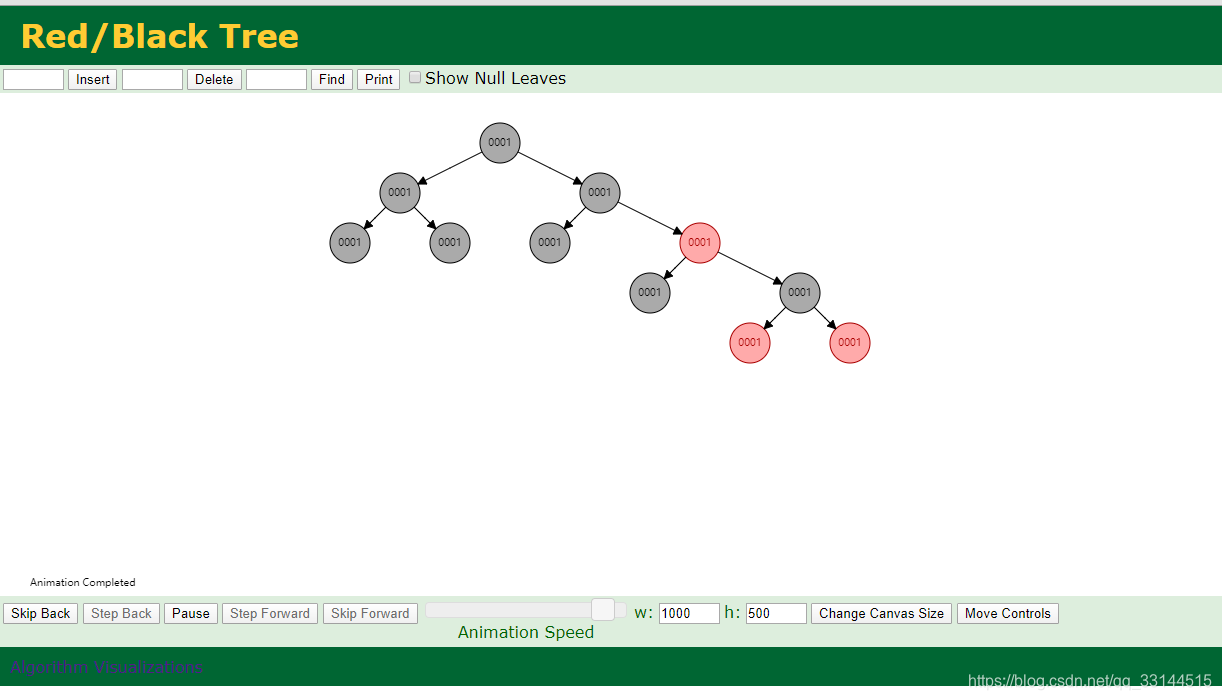
缺点:层级太多 要是查询较大数据 会进行太多次IO 固衍生B TREE
B Tree:
B Tree 将层级缩小 一次IO取多个数据 然后进行判断比对 大的将加入到右侧 小的加入到右侧 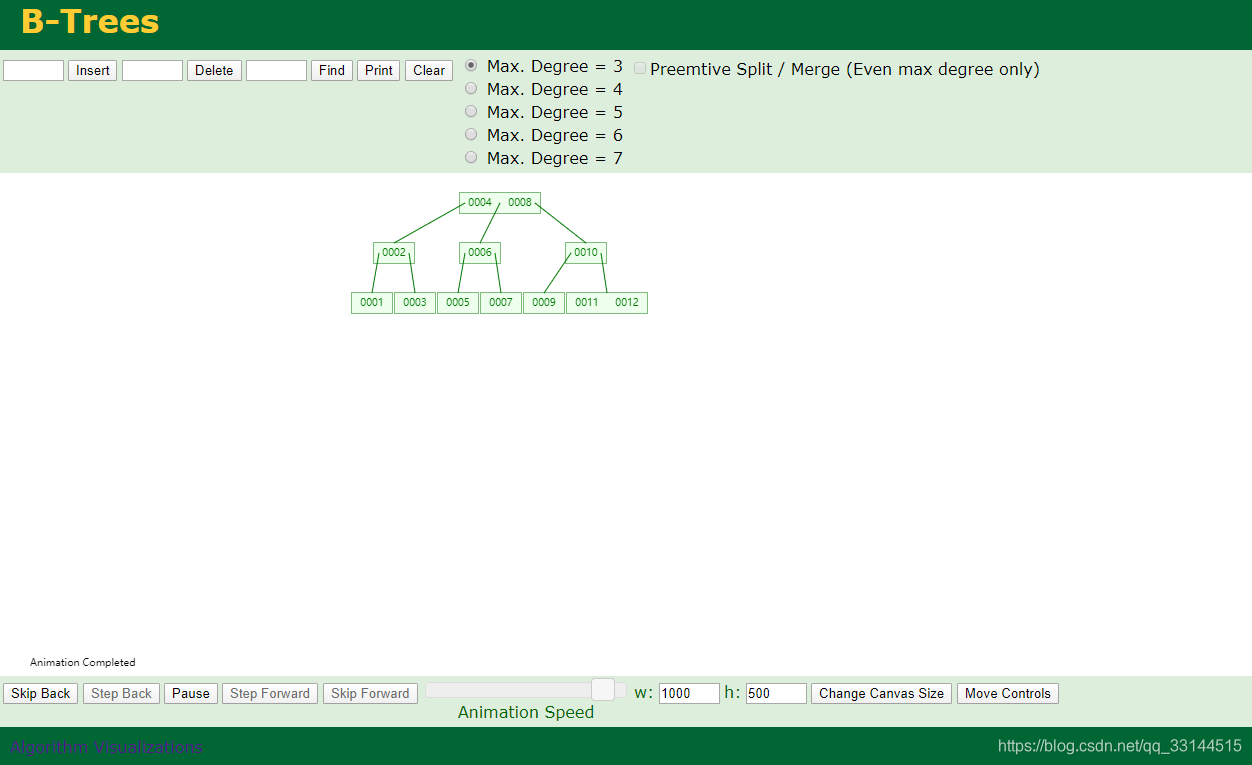
缺点:B Tree 中每一个数据ID 会跟一个Data 这样每次对比IO流数据量较大 则揽胜出B+Tree 会将data加入到叶子节点 每个分母节点都有对应的叶子节点用于存储data。
B+Tree:
B+Tree 数据从左到右 从小到大 若是中文则根据二进制数据比对大小进行存放 B+Tree 的data 都存放在叶子节点中 B+Tree 和B Tree 还有不同在于 叶子节点会有指正有小到大 指向 在末尾在指向到头。 这也就是说明 data都存储在叶子节点中。
目前Mysql innodb结构默认 使用的就是B+Tree 索引数据结构
当然 Mysql中还有hash索引结构 Hash索引结构查询ID相等的数据 非常快速 但是满足的业务较少 比如说要检索大于小于 速度会比B+Tree慢很多 所以一般使用B+Tree 索引结构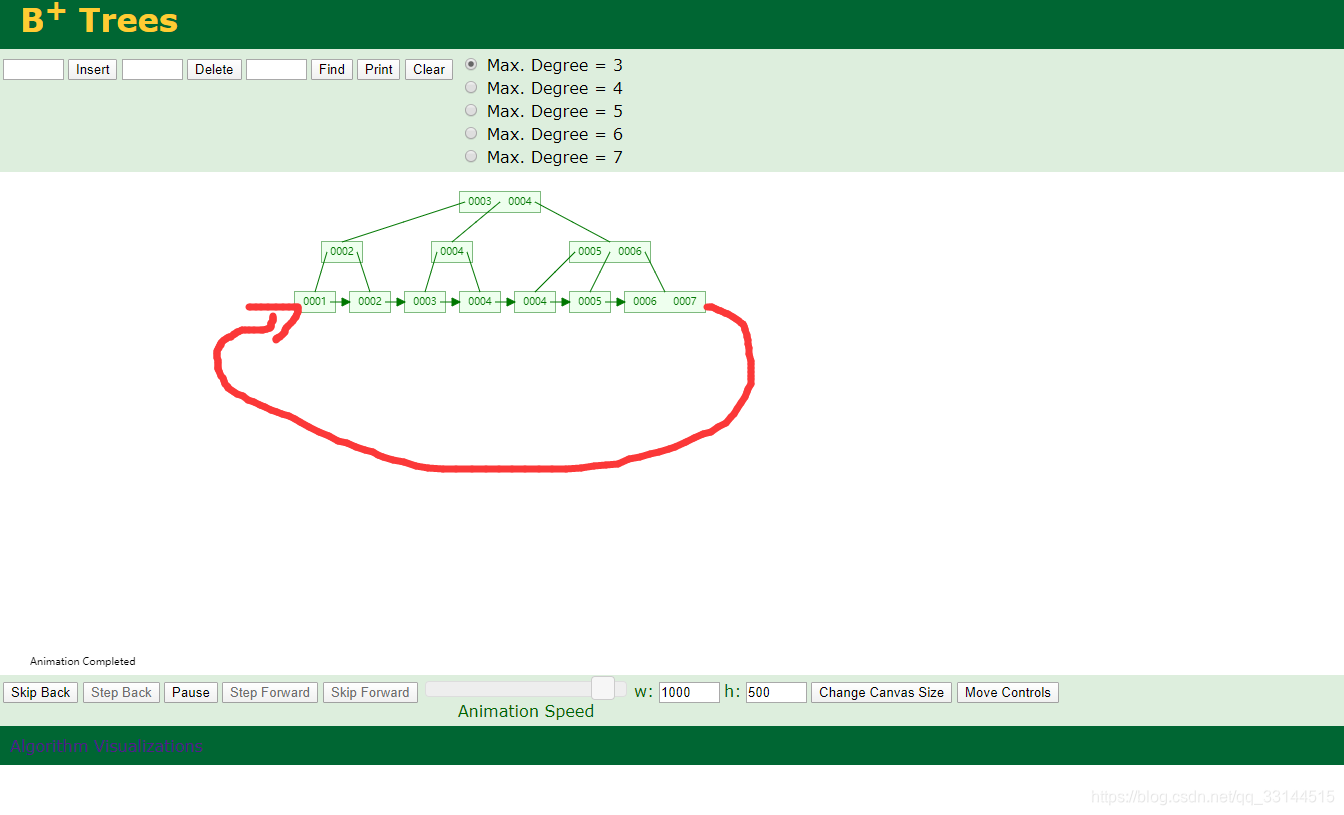
另外还有Lucene 数据结构
倒排索引:
每一个分词过的Key 对应的一个ID
ID相同 词不同 一个词可以对应多个ID 我猜想 ID 可能是1,2,3,4这样存储 所以可以通过该词查出这些ID
lucene 分页取数据纯内存操作 如果要做分页千万不能分太多页 如果有千万级数据 分页到最后一页 内存吃不消会炸掉。 相当于for循环了千万以前的数据 在取后面的数据。
lucene取数据 当然也不是单纯的从1到100 lucene取数据有跳表的概念 类似于 B+Tree 有分母节点 用于判断是否大于或小于
lucene存数据是将数据压缩后进行存储的,存储数据时也会将TF/IDF 进行计算
通过TF/IDF 进行排序
TF:词频
DF:该词在别的文章中 出现的次数 比如说 的 在所有文章都有 则 ‘的’ 的DF很大 那么IDF 很小
IDF:DF取反 DF越小IDF越大
本文到此结束,希望能给予大家帮助。