上一篇博客我对决策树做了介绍,当然那是自己编写的算法去实现决策树的构造和图的绘制,在sklearn库中sklearn.tree模块提供了决策树模型供我们使用,所以对它来个简单介绍。
回顾:
决策树是一种用于分类和回归的非参数监督学习方法。目的是创建一个模型,该模型通过学习从数据特征推断出的简单决策规则来预测目标变量的值。我们将用sklearn库中的模块对决策树进行构造。
sklearn.tree.DecisionTreeClassifier
决策树的构建函数class sklearn.tree.DecisionTreeClassifier(*, criterion=‘gini’, splitter=‘best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=‘deprecated’, ccp_alpha=0.0),其中有12个参数,当然有些也并不常用,所以我对常用的参数做个简介。
criterion:特征选则的标准,它有“gini”和“entropy”两种可选参数,其中“gini”是默认参数,它代表的是基尼不纯度,(简单地说就是从一个数据 集中随机选取子项,度量其被错误分类到其他分组里的概率),我们这里介绍的主要是“entropy”,它就是香农熵。
splitter:分割器,也就是特征划分点的选择标准,就是确定最优的特征属性,有“best”和“random”两种可选参数,默认参数是“best”,“best”参数是根据算法选择最佳的划分特征,比如“gini”和“entropy”,而“random”参数是随机从数据中的局部划分点中选取最优划分特征,数据量很大的时候选择“random”。
其它的参数我们这里用不到,也就不作过多的解释,感兴趣的伙伴的可以自行了解。与此同时,sklearn.tree.DecisionTreeClassifier()也提供了一些方法给我们使用,可以更加快捷方便的构建决策树和对决策树进行操作:
| apply(X[, check_input]) | 返回每个样本被预测为叶子节点的索引值 |
| decision_path(X[, check_input]) | 返回决策树中的决策路径 |
| fit(X, y[, sample_weight, check_input, …]) | 根据训练集(X,y)构建决策树分类器 |
| get_depth() | 返回决策树的深度 |
| get_n_leaves() | 返回决策树的叶子节点数 |
| get_params([deep]) | 获取此估计量的参数 |
| cost_complexity_pruning_path(X,y [,…]) | 在最小化成本复杂性修剪期间计算修剪路径 |
| predict(X[, check_input]) | 预测X的类或回归值 |
| predict_log_proba(X) | 预测输入样本X的类对数概率 |
| predict_proba(X[, check_input]) | 预测输入样本X的类别概率 |
| score(X, y[, sample_weight]) | 返回给定测试数据和标签上的平均准确度 |
| set_params(**params) | 设置此估算器的参数 |
我们还是用上篇博客提到的书中的内容数据,隐形眼镜的镜片类型。我们下载放入与py文件同目录下,写下代码创建决策树:
from sklearn.tree import DecisionTreeClassifier
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
#读取文件全部行,删除换行符和空格,并以'\t'分隔每行内容形成列表
lensesLabels = ['age','prescript','astigmatic','tearRate']
#将数据集的特征属性标签加入列表
glasses = DecisionTreeClassifier(criterion='entropy')
#以香农熵作为最优特征选择标准
glasses.fit(lenses,lensesLabels)
运行结果出错:
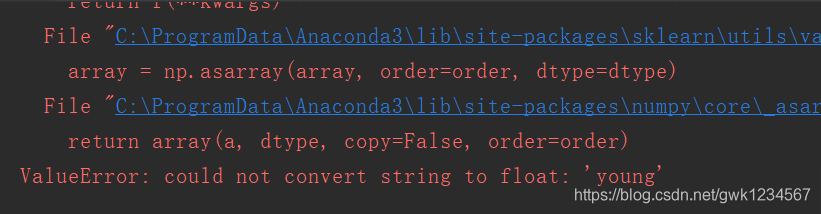
报错的意思是要转换成浮点数的字符串中包含了非数字字符的东西,比如空格,字母等都不能转换成浮点数,同时fit()函数不能接受string类型的数据。在我们之前的数据集中,我们有no surfacing 和flippers两种特征,特征值在表格中用是和否来表示,但是用代码进行构造决策树时我们也转换成0和1来表示,所以这里的错误就比较明显了,我们文件中的数据是这种形式:
我看了其他一些博客,可以采用LabelEncoder来解决,就是将字符串转为增量值,我们要对数据集进行编码,我们先对数据进行生成pandas数据,然后将string类型数据序列化(就是将数据信息转换成可以存储或传输得形式的过程)。生成pandas数据,我们也需要引入pandas包,
放代码讲解:
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
#读取文件全部行,删除换行符和空格,并以'\t'分隔每行内容形成列表
lenses_target = []
#定义列表,存储每组的类别
for i in lenses:
lenses_target.append(i[-1])
#数据集中最后一列是列别
lensesLabels = ['age','prescript','astigmatic','tearRate']
#将数据集的特征属性标签加入列表
lenses_list = []#临时存放lenses数据
lenses_dict = {
}#保存lenses数据的字典,用于生成pandas
for i in lensesLabels:#遍历特征属性列表
for j in lenses:#遍历数据集
lenses_list.append(j[lensesLabels.index(i)])
#临时列表中添加根据每个特征在列表中的索引找到数据集中全部属于
#该特征的值
lenses_dict[i] = lenses_list#字典键值对应
lenses_list = []#清空临时列表,以便于下一次的遍历存储
lenses_pd = pd.DataFrame(lenses_dict)
#生成pandas数据
print(lenses_pd)
#glasses = DecisionTreeClassifier(criterion='entropy')
#以香农熵作为最优特征选择标准
#glasses.fit(lenses,lensesLabels)
运行的结果是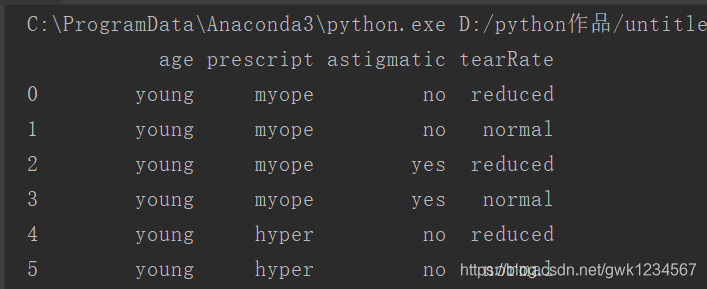
它将原来文件中的数据进行整理排列,使之更加有序化,对应化,而这也是pandas的功能,它专门为处理表格和混杂数据设计的,使数据预处理、清洗、分析工作变得更快更简单。
之后我们要将数据序列化,上代码:
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.preprocessing import LabelEncoder
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
#读取文件全部行,删除换行符和空格,并以'\t'分隔每行内容形成列表
lenses_target = []
#定义列表,存储每组的类别
for i in lenses:
lenses_target.append(i[-1])
#数据集中最后一列是列别
lensesLabels = ['age','prescript','astigmatic','tearRate']
#将数据集的特征属性标签加入列表
lenses_list = []#临时存放lenses数据
lenses_dict = {
}#保存lenses数据的字典,用于生成pandas
for i in lensesLabels:#遍历特征属性列表
for j in lenses:#遍历数据集
lenses_list.append(j[lensesLabels.index(i)])
#临时列表中添加根据每个特征在列表中的索引找到数据集中全部属于
#该特征的值
lenses_dict[i] = lenses_list#字典键值对应
lenses_list = []#清空临时列表,以便于下一次的遍历存储
lenses_pd = pd.DataFrame(lenses_dict)#生成pandas数据
print(lenses_pd)
l = LabelEncoder()
#创建LabelEncoder对象,用于序列化
for col in lenses_pd.columns:
lenses_pd[col] = l.fit_transform(lenses_pd[col])
#以每一列的特征为标准进行序列化
#fit_transform的作用就是先拟合数据,然后转化它为标准形式
print(lenses_pd)#打印序列化后的数据集
#glasses = DecisionTreeClassifier(criterion='entropy')
#以香农熵作为最优特征选择标准
#glasses.fit(lenses,lensesLabels)
运行结果: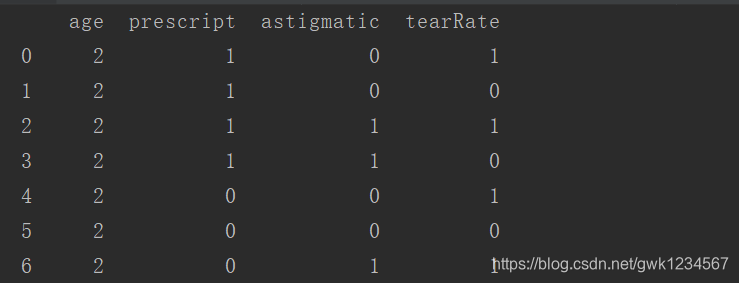
我们可以看到数据就与之前的表格数据一样转为数字模型,那我们就可以创建决策树了。
当然创建了决策树,我们就会想到绘制决策树,这里我们可以使用Graphviz进行绘制,这个图形绘制工具,它可以很方便用来绘制结构化的图形网络,支持多种格式输出,生成图片的质量和速度都不错。它的输入是一个用dot语言编写的绘图脚本,通过对输入脚本的解析,分析出其中的点,边以及子图,然后根据属性进行绘制。是使用Sklearn生成的决策树就是dot格式的,因此我们可以直接利用Graphviz将决策树可视化。在这之前,我们需要安装pydotplus和Graphviz。
下载完成后我们可以使之可视化:
from sklearn.tree import DecisionTreeClassifier
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from six import StringIO
import pydotplus
from sklearn import tree
fr = open('lenses.txt')
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
#读取文件全部行,删除换行符和空格,并以'\t'分隔每行内容形成列表
lenses_target = []
#定义列表,存储每组的类别
for i in lenses:
lenses_target.append(i[-1])
#数据集中最后一列是列别
lensesLabels = ['age','prescript','astigmatic','tearRate']
#将数据集的特征属性标签加入列表
lenses_list = []#临时存放lenses数据
lenses_dict = {
}#保存lenses数据的字典,用于生成pandas
for i in lensesLabels:#遍历特征属性列表
for j in lenses:#遍历数据集
lenses_list.append(j[lensesLabels.index(i)])
#临时列表中添加根据每个特征在列表中的索引找到数据集中全部属于
#该特征的值
lenses_dict[i] = lenses_list#字典键值对应
lenses_list = []#清空临时列表,以便于下一次的遍历存储
lenses_pd = pd.DataFrame(lenses_dict)#生成pandas数据
print(lenses_pd)
l = LabelEncoder()
#创建LabelEncoder对象,用于序列化
for col in lenses_pd.columns:
lenses_pd[col] = l.fit_transform(lenses_pd[col])
#以每一列的特征为标准进行序列化
#fit_transform的作用就是先拟合数据,然后转化它为标准形式
print(lenses_pd)#打印序列化后的数据集
glasses = DecisionTreeClassifier(criterion='entropy')
#以香农熵作为最优特征选择标准
glasses.fit(lenses_pd.values.tolist(),lenses_target)
dot_data = StringIO()
tree.export_graphviz(glasses,out_file=dot_data,feature_names=lenses_pd.keys(),class_names=glasses.classes_,filled=True,rounded=True,special_characters=True)#绘制决策树
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("tree.pdf")#以pdf形式存储绘制好的决策树
运行后,同目录下
会生成一个pdf文件,打开可以看看结果:
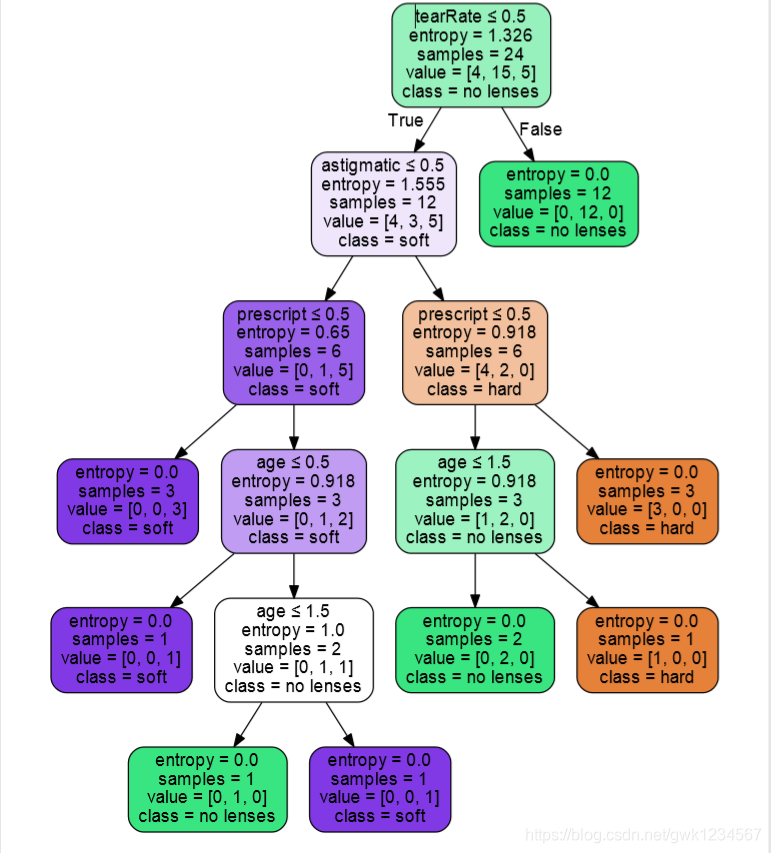
最后如果要进行预测分类,可以使用predict方法即可。
最后这里给出官方文档地址文档地址。