声明
本文参考了《机器学习实战》书中代码,结合该书讲解,并加之自己的理解和阐述
机器学习实战系列博文
- 机器学习实战--k近邻算法改进约会网站的配对效果
- 机器学习实战--决策树的构建、画图与实例:预测隐形眼镜类型
- 机器学习实战--朴素贝叶斯算法应用及实例:利用贝叶斯分类器过滤垃圾邮件
- 机器学习实战--Logistic回归与实例:从疝病症预测病马的死亡率
决策树建立
决策树的定义
通俗来讲,决策树就是用几个特征值将信息层层分开,像一棵树一样,树的叶子就是被归类的类型
首先要讲解一下树建立的依据,大家可以自行百度查看一下信息和信息熵的概念,决策树建立的目标就是使树按照某一特征分类后信息熵能够最小。信息熵又称为香农熵,公式为:
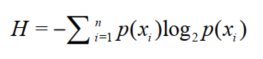
计算信息熵
将数据集中的每个特征都统计一下数量,求出概率,再按照上文公式计算。
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob*log(prob,2)
return shannonEnt接下来就要给某一个特征进行数据集划分,目的是将训练数据按某一个特征分成多个数据集。
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis]==value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet我们遍历划分的方式,换句话说就是每个特征都划分一次,然后计算信息熵,信息熵最小的对应的那个特征就是即将进行分类的依据。
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob*calcShannonEnt(subDataSet)
infoGain = baseEntropy-newEntropy
if(infoGain>bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature下边考虑如果我们用完了所有特征,但是在某一树杈上的数据依旧不属于同一类,那我们就必须采用最原始的少数服从多数的方法来决定这些数据的所属类型。
def majorityCnt(classList):
classCount = {}
for vote in classCount:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]建立决策树
到目前为止,准备工作就做完了,下面开始正式建立决策树
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
#类别完全相同,停止分类
if classList.count(classList[0]) == len(classList):
return classList[0]
#用完了所有特征后,用少数服从多数决定类型
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
#一个递归建立所有子树
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(
dataSet,bestFeat,value),subLabels)
return myTree这个递归可能不太好理解,举个例子,其实就是当我的决策树选择了特征t时,特征t中有m个不同的值,那么我的树就要分m个叉,每个叉对应一个值,然后我的每一个叉又是一个对剩余数据建立的决策树,这样一来就递归的将决策树建立完毕。
下面进行一下验证,看下面的表格,我们对下边五种动物进行归类,数据处理见代码:

def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels然后我们对该数据集建立决策树
myData ,labels = createDataSet()
myTree = createTree(myData,labels)
print(myTree)结果为:{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
按照我们人脑来看,这样的分类已经是很合理了。
决策树绘制
其实这个绘制就是用线框画的一棵树,加上了一些标签,直接将代码放到这里了,原书中代码是python2的,我这里改成了python3的代码,如下:
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
for keyss in myTree:
firstStr = keyss
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
for keyss in myTree:
firstStr = keyss
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt): # if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) # this determines the x width of this tree
depth = getTreeDepth(myTree)
for keyss in myTree:
firstStr = keyss
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key], cntrPt, str(key)) # recursion
else: # it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
# if you do get a dictonary you know it's a tree, and the first element will be another dict
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
这个画图没有涉及到很多算法,所以就不多做解释了,想用的话大家可以直接调用createPlot即可,有兴趣的也可以再看看代码,比如我们上一部分算出的决策树,画出来就是:

有点粗糙,其实画树python有很多实用的GUI库可以调用,这里就不多说了
实例:预测隐形眼镜类型
问题描述
隐形眼镜数据集是非常著名的数据集,它包含很多患者眼部状况的观察条件以及医生推荐的隐形眼镜类型。隐形眼镜类型包括硬材质、软材质以及不适合佩戴隐形眼镜,数据来源于UCI数据库,为了更容易显示数据,本书对数据做了简单的更改,数据如下图所示:

由前边四种类型数据来判定该隐形眼镜属于硬材质、软材质以及不适合佩戴型的三种的哪一种
决策树分类
#数据文件
fr = open("lenses.txt")
lenses = [inst.strip().split('\t') for inst in fr.readlines()]
#数据标签
lensesLabels = ['age','prescript','astigmatic','tearRate']
#建立决策树
lensesTree = createTree(lenses,lensesLabels)然后得到了分类:
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic': {'yes': {'prescript': {'hyper': {'age': {'presbyopic': 'no lenses', 'pre': 'no lenses', 'young': 'hard'}}, 'myope': 'hard'}}, 'no': {'age': {'presbyopic': {'prescript': {'hyper': 'soft', 'myope': 'no lenses'}}, 'pre': 'soft', 'young': 'soft'}}}}}}这样看起来很不直观,我们将它画出图:

这样当我们再获取了一条新的数据时,就可以按照树中节点层层筛选,最后判定属于哪一类了
