版权声明:本文为博主siucaan原创文章,转载请注明出处。 https://blog.csdn.net/qq_23869697/article/details/81989017
这里是3.x版本的Python,对代码做了一些修改。
其中画图的函数直接使用的是原代码中的函数,也做了一些修改。
书本配套的数据和2.7版本的源码可以在这里获取 :https://www.manning.com/books/machine-learning-in-action
from math import log
from ch3.treePlotter import createPlot
def calShannonEntropy(dataset):
"""
计算香浓熵
:param dataset: 输入数据集
:return: 熵
"""
num = len(dataset)
label_liat = {}
for x in dataset:
label = x[-1] # the last column is label
if label not in label_liat.keys():
label_liat[label]=0
label_liat[label] += 1
shannonEnt = 0.0
for key in label_liat:
prob = float(label_liat[key]/num)
shannonEnt -= prob * log(prob,2)
# print("数据集的香浓熵为%f" % shannonEnt)
return shannonEnt
def splitDate(dataset, axis, value):
"""
根据某个特征划分数据集,
:param dataset: 输入数据集
:param axis: 数据集的每一列表示一个特征,axis取不同的值表示取不同的特征
:param value: 根据这个特征划分的类别标记,在二叉树中常为2个,是或者否
:return: 返回去掉了某个特征并且值是value的数据
"""
newdataset = []
for x in dataset:
if x[axis] == value:
reduceFeat = x[:axis]
reduceFeat.extend(x[axis+1:])
newdataset.append(reduceFeat)
return newdataset
def keyFeatureSelect(dataset):
"""
通过信息增益判断哪个特征是关键特征并返回这个特征
:param dataset: 输入数据集
:return: 特征
"""
num_feature = len(dataset[0])-1
base_entropy = calShannonEntropy(dataset)
bestInfogain = 0
bestfeature = -1
for i in range(num_feature):
featlist = [example[i] for example in dataset]
feat_value = set(featlist)
feat_entropy = 0
for value in feat_value:
subset = splitDate(dataset,i,value)
prob = len(subset)/float(len(dataset))
feat_entropy += prob * calShannonEntropy(subset)
infoGain = base_entropy - feat_entropy
# print("第%d个特征的信息增益%0.3f" %(i,infoGain))
if (infoGain > bestInfogain):
bestInfogain = infoGain
bestfeature = i
# print("第%d个特征最关键" % i)
return bestfeature
def voteClass(classlist):
"""
通过投票的方式决定类别
:param classlist: 输入类别的集合
:return: 大多数类别的标签
"""
import operator
classcount = {}
for x in classlist:
if x not in classcount.keys():classcount[x]=0
classcount += 1
sortclass = sorted(classcount.iteritems(),key = operator.itemgetter(1),reverse=True)
return sortclass[0][0]
def createTree(dataset,labels):
"""
递归构建树
:param dataset: dataset
:param labels: labels of feature
:return:树
"""
labelsCopy = labels[:] # 原代码没有这个,结果第一次运行之后第一个特征被删除了,所以做了修改
classList = [example[-1] for example in dataset]
if classList.count(classList[0]) == len(classList): #判断所有类标签是否相同
return classList[0]
if len(dataset[0]) == 1: # 是否历遍了所有特征(是否剩下一个特征)
return voteClass(classList)
bestFeat = keyFeatureSelect(dataset)
bestFeatLabel = labelsCopy[bestFeat]
tree = {bestFeatLabel:{}} # 使用字典实现树
del labelsCopy[bestFeat]
featValues = [example[bestFeat] for example in dataset]
uniqueValue = set(featValues)
for value in uniqueValue:
subLabels = labelsCopy[:] #复制类标签到新的列表中,保证每次递归调用不改变原始列表
tree[bestFeatLabel][value] = createTree(splitDate(dataset,bestFeat,value),subLabels)
return tree
def decTreeClassify(inputTree, featLables, testVec):
"""
使用决策树模型进行分类
:param inputTree:
:param featLables:
:param testVec:
:return:
"""
firstStr = list(inputTree.keys())[0] # 根节点
secondDict = inputTree[firstStr] # 节点下的值
featIndex = featLables.index(firstStr) # 获得第一个特征的label对应数据的位置
for key in secondDict.keys(): # secondDict.keys()表示一个特征的取值
if testVec[featIndex] == key: # 比较测试向量中的值和树的节点值
if type(secondDict[key]).__name__ == 'dict':
classLabel = decTreeClassify(secondDict[key], featLables, testVec)
else:
classLabel = secondDict[key]
return classLabel
def storeTree(inputTree, filename):
"""
store the trained Tree.
:param inputTree: the the trained Tree
:param filename: save tree as file name
:return: None
"""
import pickle
fw = open(filename,'wb')
pickle.dump(inputTree,fw)
fw.close()
print("tree save as", filename)
def grabTree(filename):
"""
read stored tree from disk
:param filename: the goal file
:return: Tree
"""
print("load tree from disk...")
import pickle
fr = open(filename,"rb")
return pickle.load(fr)
if __name__== '__main__':
fr = open('lenses.txt')
lense = [inst.strip().split('\t') for inst in fr.readlines()]
train_set = lense[1:]
test_set = lense[0]
lenseLabels = ['age', 'prescript', 'astigmatic', 'tearRate']
lenseTree = createTree(train_set, lenseLabels)
createPlot(lenseTree)
storeTree(lenseTree, 'lenseTree.txt')
restoreTree = grabTree('lenseTree.txt')
print(restoreTree)
predict = decTreeClassify(restoreTree,lenseLabels,test_set)
print(predict)
画出来的图:
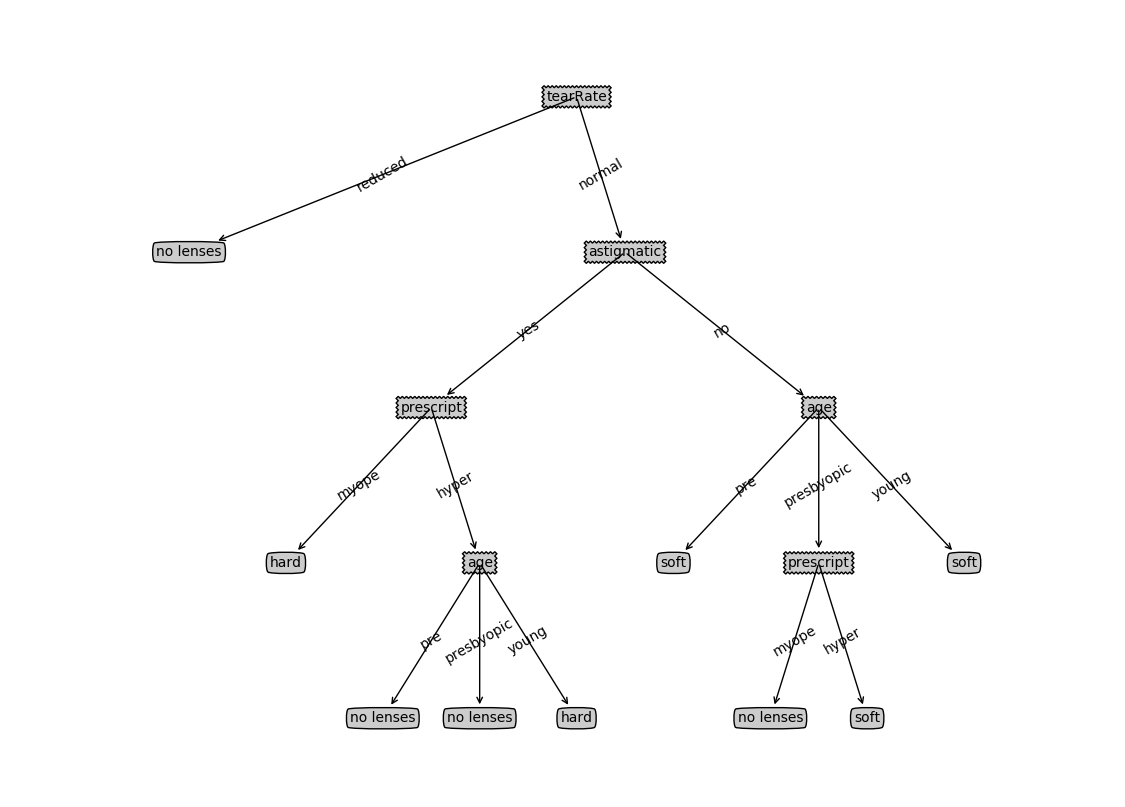
运行结果:
{'tearRate': {'reduced': 'no lenses', 'normal': {'astigmatic': {'yes': {'prescript': {'myope': 'hard', 'hyper': {'age': {'pre': 'no lenses', 'presbyopic': 'no lenses', 'young': 'hard'}}}}, 'no': {'age': {'pre': 'soft', 'presbyopic': {'prescript': {'myope': 'no lenses', 'hyper': 'soft'}}, 'young': 'soft'}}}}}}预测结果:
no lenses参考《机器学习实战》