作者:中南大学可视化实验室可解释性机器学习项目组 18届 本科生研究员 WXY
日期:2020-7-16
标签: 梯度下降 误差反向传播
一、梯度下降算法
基本思想:从某些初始解出发,迭代寻找最优参数值,每次迭代中在当前点计算梯度,根据函数值下降最快的方向确定搜索方向,梯度为0则达到局部极小。


J是代价函数,w是权重,b是一个常数类似于阈值,当我们从一个初始点出发,向梯度最大的方向一步一步前进,最终会到达最小值

全局最小与局部极小
这张图是一个凸函数,但是如果在非凸最优化,类似于这张图

直接采取梯度下降或许就不能到达全局最小
跳出局部极小的策略
以多组不同参数值初始化多个神经网络,取其中误差最小的解作为最终参数。
模拟退火simulated annealing:每一步都以一定的概率接受比当前解更差的结果。
随机梯度下降:在计算梯度是加入了随机因素,即使到达极小点,它的梯度可能仍不为 0,会继续计算。
技巧:
1、学习率learning rate:

理想情况下代价函数关于迭代次数的曲线是这样的:

可以用来判断是否已经汇聚,比如一次迭代的下降在10^-3 范围内。但是如果曲线如下图:


表示学习率过大,也就是说每一步的步长过大,虽然向着下降的方向前进,但是不能到达更小的值。

如果学习率过小,显然收敛速度是很慢的。
2、保证输入特征的值在一个相似的范围内

假设一个特征在0-2000,另一个在1-5,那么把损失函数基于这两个特征的轮廓图画出来,就会变成这种细长的形状,那么在梯度下降的过程中轨迹将很复杂

但是当把两个缩放后,轨迹就变得简单,可以更快到达最优值。
3、均值归一化
使用xi-ui代替xi,使特征更加接近0

思考:在我们的应用中是否也可以进行这样的操作呢
比如这张图像由三层像素值组成,当将每个值x用(x-均值)/255 代替或许也可以减少运行时间。

二、逆误差传播算法 BP算法

输入层有d个属性描述,q个隐层神经元,l个输出神经元,三层直接有权重,隐层和输出层神经元上有阈值。
BP算法基于梯度下降算法,广义上每个参数的更新式都是这样的
,比如对权重whj,
。这之中的每一个权重或阈值都可以由数学方法得到其基于特定输入的梯度。
BP算法的基本思想:将输入数据提供给输入神经元,然后逐层将信号前传,直到产生输出层的结果,然后从输出层计算误差,再逆向地将误差传播到隐层,调整连接权和阈值,对此过程循环迭代,直到达到某些条件,例如最小化累积误差 。
。
这里可能产生一个问题:为什么要先向前传播再向后传播,为什么不直接一次向前传播就计算出所有的东西?
这是由计算方式决定的,用一个计算图Computer Graph来解释
J(a, b, c) = 3(a+bc)

我们在向前传播的过程中可以得到其中所有的输出值
但是当计算梯度时必须从后向前,比如v增加1,J增加3得到v与J的梯度,然后才能计算a与J的梯度,理论就是微积分里的链式法则。
注:如何设置神经元的个数是个未决问题,应用中通常靠试错法来调整。
技巧:
BP有强大的表示能力,但是经常过拟合(训练误差降低,测试误差上升),有两种策略缓解过拟合:
早停:将数据分为训练集和验证集,训练集用于计算梯度、更新连接权和阈值,当训练集的误差降低但是验证集的误差上升,就提前停止训练。
正则化:在误差目标函数中增加一个用于描述网络复杂度的部分,比如连接权与阈值的平方和,将误差目标函数改变为:
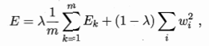
对经验误差与网络复杂度这两项进行折中。
我的理解是当过拟合发生网络的复杂度一定很高,那么控制复杂度可以帮助控制过拟合。