1. Gradient descent
Gradient descent is a way to minimize an objective function
2. Gradient descent 3 variants
1. Batch gradient descent
Batch gradient descent computes
- Batch gradient descent can be very slow and intractable for large datasets that don’t fit in memory.
- It also doesn’t allow us to update our model online.
- It is guaranteed to converge to the global minimum for convex error surfaces and to a local minimum for non-convex surfaces.
2. Stochastic gradient descent
Stochastic gradient descent (SGD) in contrast computes
- Batch gradient descent performs redundant computations for large datasets, as it recomputes gradients for similar examples before each parameter update. SGD does away with this redundancy by performing one update at a time. It is therefore usually much faster.
- It can also be used to learn online.
- It performs frequent updates with a high variance that cause the objective function to fluctuate heavily. This fluctuation, on the one hand, enables it to jump to new and potentially better local minima. On the other hand, this ultimately complicates convergence to the exact minimum, as It will keep overshooting. However, when we slowly decrease the learning rate (annealing learning rate), It shows the same convergence behaviour as batch gradient descent.
- tricks: shuffle the training data at every epoch.
3. Mini-batch gradient descent
Mini-batch gradient descent finally takes the best of both worlds, i.e. it performs an update for every mini-batch of
- It reduces the variance of the parameter updates, which can lead to more stable convergence.
- It can make use of highly optimized matrix optimizations common to state-of-the-art deep learning libraries that make computing the gradient w.r.t. a mini-batch very efficient.
- tricks: Common mini-batch sizes range between 50 and 256.
4. Challenges
- Choosing a proper learning rate can be difficult. A learning rate that is too small leads to painfully slow convergence, while a learning rate that is too large can hinder convergence and cause the loss function to fluctuate around the minimum or even to diverge.
- Learning rate schedules try to adjust the learning rate during training by e.g. annealing, i.e. reducing the learning rate according to a pre-defined schedule or when the change in objective between epochs falls below a threshold. These schedules and thresholds, however, have to be defined in advance and are thus unable to adapt to a dataset’s characteristics.
- The same learning rate applies to all parameter updates. If our data is sparse and our features have very different frequencies, we might not want to update all of them to the same extent, but perform a larger update for rarely occurring features.
- Avoiding getting trapped in numerous suboptimal local minima. The difficulty arises in fact not from local minima but from saddle points, i.e. points where one dimension slopes up and another slopes down. These saddle points are usually surrounded by a plateau of the same error, which makes it notoriously hard for SGD to escape, as the gradient is close to zero in all dimensions.
3. Gradient descent optimization algorithms
We will outline some algorithms that are widely used by the deep learning community to deal with the aforementioned challenges, but not discuss algorithms that are infeasible to compute in practice for high-dimensional data sets, e.g. second-order methods such as Newton’s method.
1. Momentum
SGD has trouble navigating ravines, i.e. areas where the surface curves much more steeply in one dimension than in another, which are common around local optima. In these scenarios, SGD oscillates across the slopes of the ravine while only making hesitant progress along the bottom towards the local optimum (left).


Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations (right). It does this by adding a fraction
Theano code:
for p, g in zip(params, grads):
v = shared(p.get_value() * 0., borrow=True)
updates.append([p, p + v])
updates.append([v, momentum * v - lr * g])The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
Another way to use momentum: dampen both velocity and gradient.
Theano code:
for p, g in zip(params, grads):
v = shared(p.get_value() * 0., borrow=True)
updates.append([v, momentum * v + (1. - momentum) * g])
updates.append([p, p - lr * v])2. Nesterov accelerated gradient
Nesterov accelerated gradient (NAG) is a way to give our momentum term more prescience. We know that we will use our momentum term
with
Theano code:
for p, g in zip(params, grads):
v = shared(p.get_value() * 0., borrow=True)
updates.append([v, momentum * v - lr * g])
updates.append([p, p + momentum * v - lr * g])- Momentum first computes the current gradient (small blue vector) and then takes a big jump in the direction of the updated accumulated gradient (big blue vector).
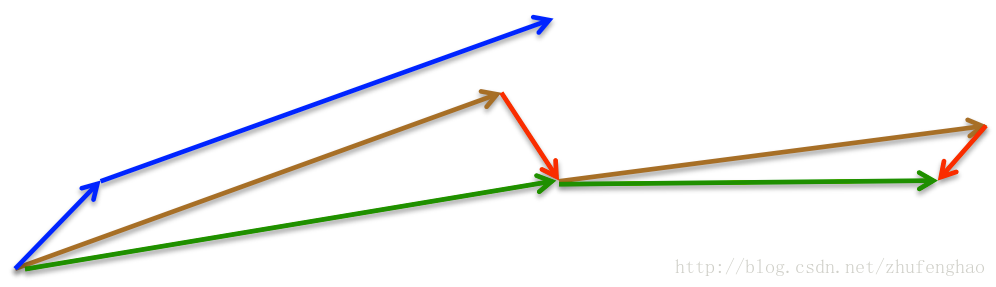
- NAG first makes a big jump (brown vector) in the direction of the previous accumulated gradient, measures the gradient and then makes a correction (red vector) and get the updated accumulated gradient (green vector). This anticipatory update prevents us from going too fast and results in increased responsiveness, which has significantly increased the performance of RNNs on a number of tasks.
3. Adagrad
Adagrad is an algorithm for gradient-based optimization that just adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters. For this reason, it is well-suited for dealing with sparse data. Adagrad uses a different learning rate for every parameter
1e−8). Interestingly, without the square root operation, the algorithm performs much worse.
Theano code:
for p, g in zip(params, grads):
acc = shared(p.get_value() * 0., borrow=True)
accNew = acc + T.square(g)
g = g / T.sqrt(accNew + epsilon)
updates.append((acc, accNew))
updates.append((p, p - lr * g))- benefits: eliminate the need to manually tune the learning rate. Just use a default value of 0.01 and leave it at that.
- weakness: accumulation of the squared gradients in the denominator keeps growing during training, which causes the learning rate to shrink and eventually become infinitesimally small, at which point the algorithm is no longer able to acquire additional knowledge.
4. Adadelta
Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size
To make the units in this update have the same hypothetical units as the parameter, we define another exponentially decaying average, not of squared gradients but of squared parameter updates:
Since
Theano code:
for p, g in zip(params, grads):
acc = shared(p.get_value() * 0., borrow=True)
accDelta = shared(p.get_value() * 0., borrow=True)
accNew = rho * acc + (1 - rho) * T.square(g)
delta = g * T.sqrt(accDelta + epsilon) / T.sqrt(accNew + epsilon)
accDeltaNew = rho * accDelta + (1 - rho) * T.square(delta)
updates.append((acc, accNew))
updates.append((p, p - lr * delta))
updates.append((accDelta, accDeltaNew))Note that we do not even need to set a default learning rate, as it has been eliminated from the update rule.
5. RMSprop
RMSprop, like Adadelta, is developed to resolve Adagrad’s radically diminishing learning rates. RMSprop in fact is identical to the first update vector of Adadelta:
RMSprop as well divides the learning rate by an exponentially decaying average of squared gradients. Hinton suggests
Theano code:
for p, g in zip(params, grads):
acc= shared(p.get_value() * 0., borrow=True) # 加权累加器
accNew = rho * acc + (1 - rho) * T.square(g)
g = g / T.sqrt(accNew + epsilon)
updates.append((acc, accNew))
updates.append((p, p - lr * g))6. Adam
Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. It stores not only an exponentially decaying average of past squared gradients
They then use these to update the parameters (like Adadelta and RMSprop), which yields the Adam update rule:
The authors propose default values of 0.9 for
Theano code:
for p, g in zip(params, grads):
mt = shared(p.get_value() * 0., borrow=True)
vt = shared(p.get_value() * 0., borrow=True)
mtNew = (beta1 * mt) + (1\. - beta1) * g
vtNew = (beta2 * vt) + (1\. - beta2) * T.square(g)
pNew = p - lr * mtNew / (T.sqrt(vtNew) + epsilon)
updates.append((mt, mtNew))
updates.append((vt, vtNew))
updates.append((p, pNew))4. Chosing optimizer
- If input data is sparse, using one of the adaptive learning-rate methods
- RMSprop
≈ Adadelta≤ Adam
5. strategies for optimizing gradient descent
1. Parallelizing and distributing SGD to speed up
SGD by itself is inherently sequential: Step-by-step, we progress further towards the minimum. Running SGD can be slow particularly on large datasets. In contrast, running it asynchronously is faster, but suboptimal communication between workers can lead to poor convergence. Additionally, we can also parallelize SGD on one machine without the need for a large computing cluster. Some algorithms and architectures have been proposed to optimize parallelized and distributed SGD.
2. Shuffling and Curriculum Learning
Generally, we want to avoid providing the training examples in a meaningful order to our model as this may bias the optimization algorithm. Consequently, it is often a good idea to shuffle the training data after every epoch.
On the other hand, for some cases where we aim to solve progressively harder problems, supplying the training examples in a meaningful order may actually lead to improved performance and better convergence. The method for establishing this meaningful order is called Curriculum Learning.
3. Batch normalization
We typically normalize the initial values of our parameters by initializing them with zero mean and unit variance. As training progresses and we update parameters to different extents, we lose this normalization, which slows down training and amplifies changes as the network becomes deeper.
Batch normalization reestablishes these normalizations for every mini-batch and changes are back-propagated through the operation as well. By making normalization part of the model architecture, we are able to use higher learning rates and pay less attention to the initialization parameters. Batch normalization additionally acts as a regularizer, reducing (and sometimes even eliminating) the need for Dropout.
4. Early stopping
We should always monitor error on a validation set during training and stop (with some patience) if your validation error does not improve enough.
5. Gradient noise
Neelakantan et al. add noise that follows a Gaussian distribution
They show that adding this noise makes networks more robust to poor initialization and helps training particularly deep and complex networks. They suspect that the added noise gives the model more chances to escape and find new local minima, which are more frequent for deeper models.