数组
基本了解
- Java 语言中提供的数组是用来存储固定大小的同类型元素
- 数组(array)是多个相同类型的数据按照一定顺序排列的集合,并使用一个名字命名,并通过编号的方式对这些数据进行同一的管理
- 数组是引用数据类型,但是数组中的元素可以是任意的数据类型
- 创建数组对象会在内存中开辟一整块连续的空间,而数组名中引用的时这块内存空间中的首地址
- 数组的长度一旦确定就不可更改
基本使用
- 声明:
dataType[] arrayRefVar;(推荐的方式) - 声明2:
dataType arrayRefVar[];
**Tip:建议使用 dataType[] arrayRefVar 的声明风格声明数组变量。 dataType arrayRefVar[] 风格是来自 C/C++ 语言 **
- 创建数组:
arrayRefVar = new dataType[arraySize];- 使用 dataType[arraySize] 创建了一个数组。
- 把新创建的数组的引用赋值给变量 arrayRefVar
- 示例:
int[] array1 = new int[]{1, 2, 3};(静态初始化)int[] array1 = {1, 2, 3};(类型推断)String[] array2 = new String[3];(动态初始化,数组的初始化和数组元素的的赋值操作分开进行)array[number]可以使用下标的方式对数组内部数据进行赋值和读取操作
- 数组中的length属性保存着该数组的长度
- 数组中元素的默认值同相应变量的默认值
foreach遍历
- 代码示例
package study1;
public class a {
public static void main(String[] args) {
int[] a = {1, 2, 3, 4, 5};
for(int i : a){
System.out.println(i);
}
}
}JVM内存结构
-
java虚拟机对内存区域的划分
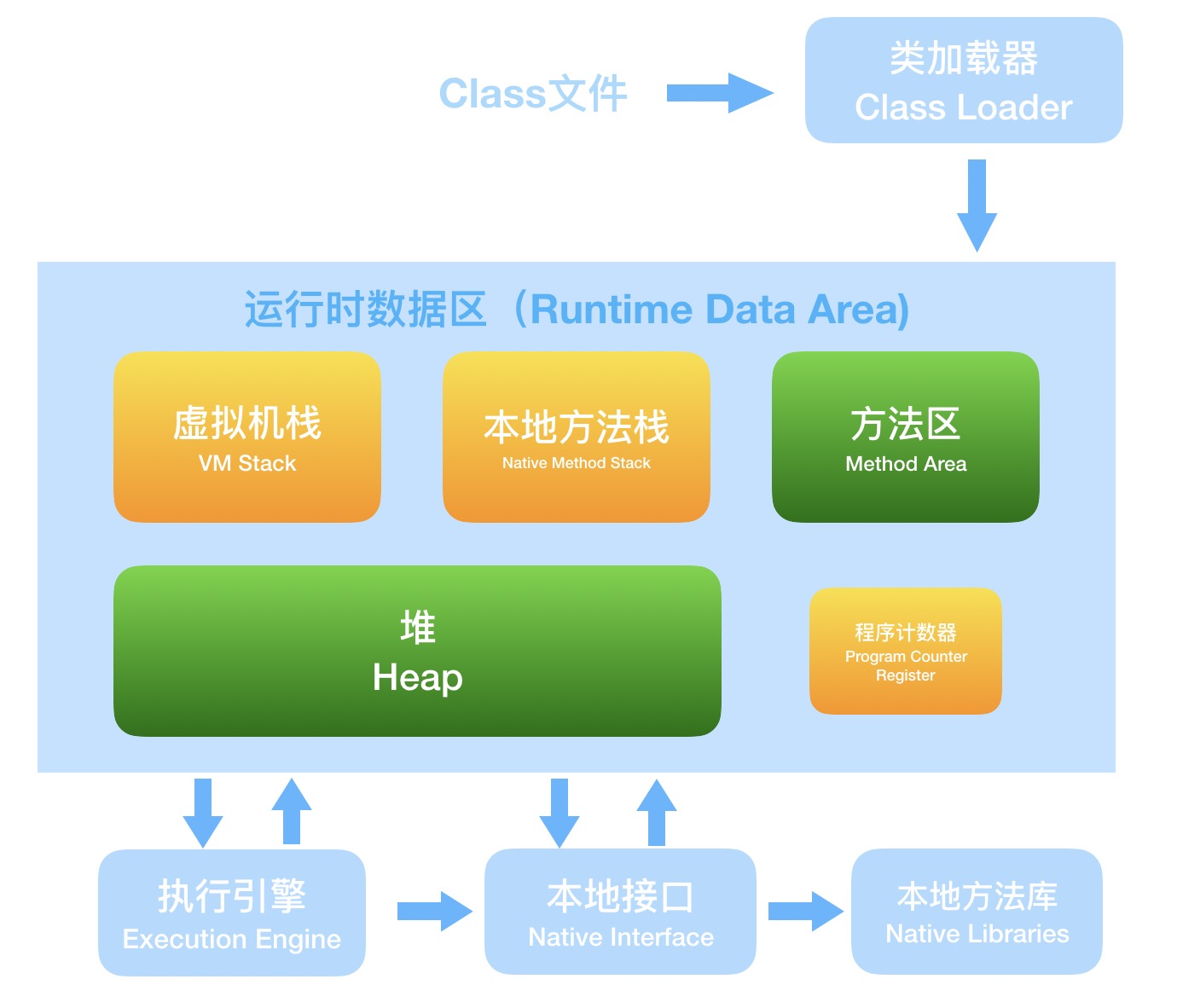
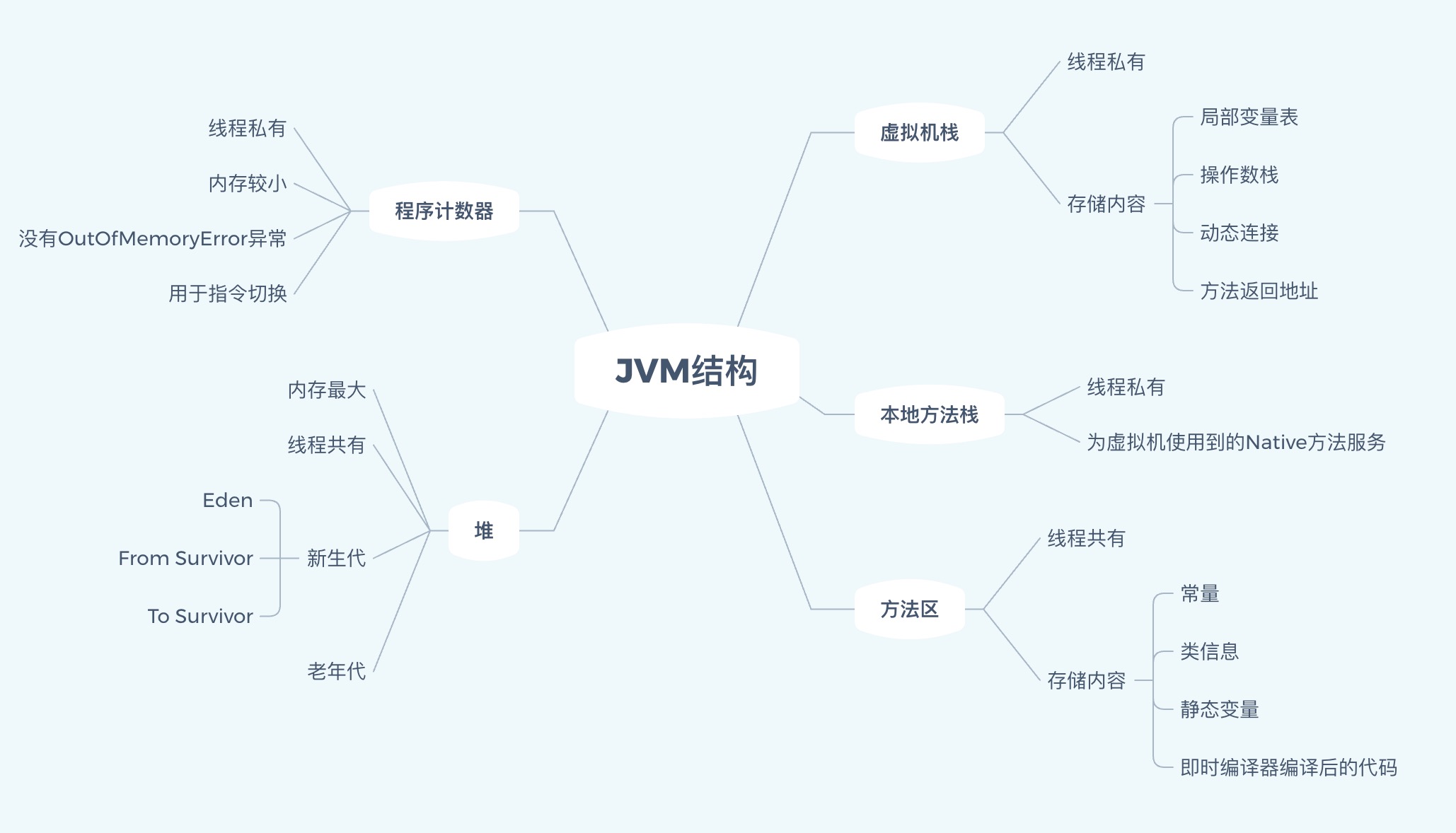
- 第一,JVM分为五个区域:虚拟机栈、本地方法栈、方法区、堆、程序计数器。
- 第二,JVM五个区中虚拟机栈、本地方法栈、程序计数器为线程私有,方法区和堆为线程共享区。图中已经用颜色区分,绿色表示“通行”,橘黄色表示停一停(需等待)。
- 第三,JVM不同区域的占用内存大小不同,一般情况下堆最大,程序计数器较小。那么最大的区域会放什么?当然就是Java中最多的“对象”了。
-
堆(Heap)
- 上面已经得出结论,堆内存最大,堆是被线程共享,堆的目的就是存放对象。几乎所有的对象实例都在此分配。当然,随着优化技术的更新,某些数据也会被放在栈上等。
- 枪打出头鸟,树大招风。因为堆占用内存空间最大,堆也是Java垃圾回收的主要区域(重点对象),因此也称作“GC堆”(Garbage Collected Heap)。
- 关于GC的操作,后面章节会详细讲,但正因为GC的存在,而现代收集器基本都采用分代收集算法,堆又被细化了。
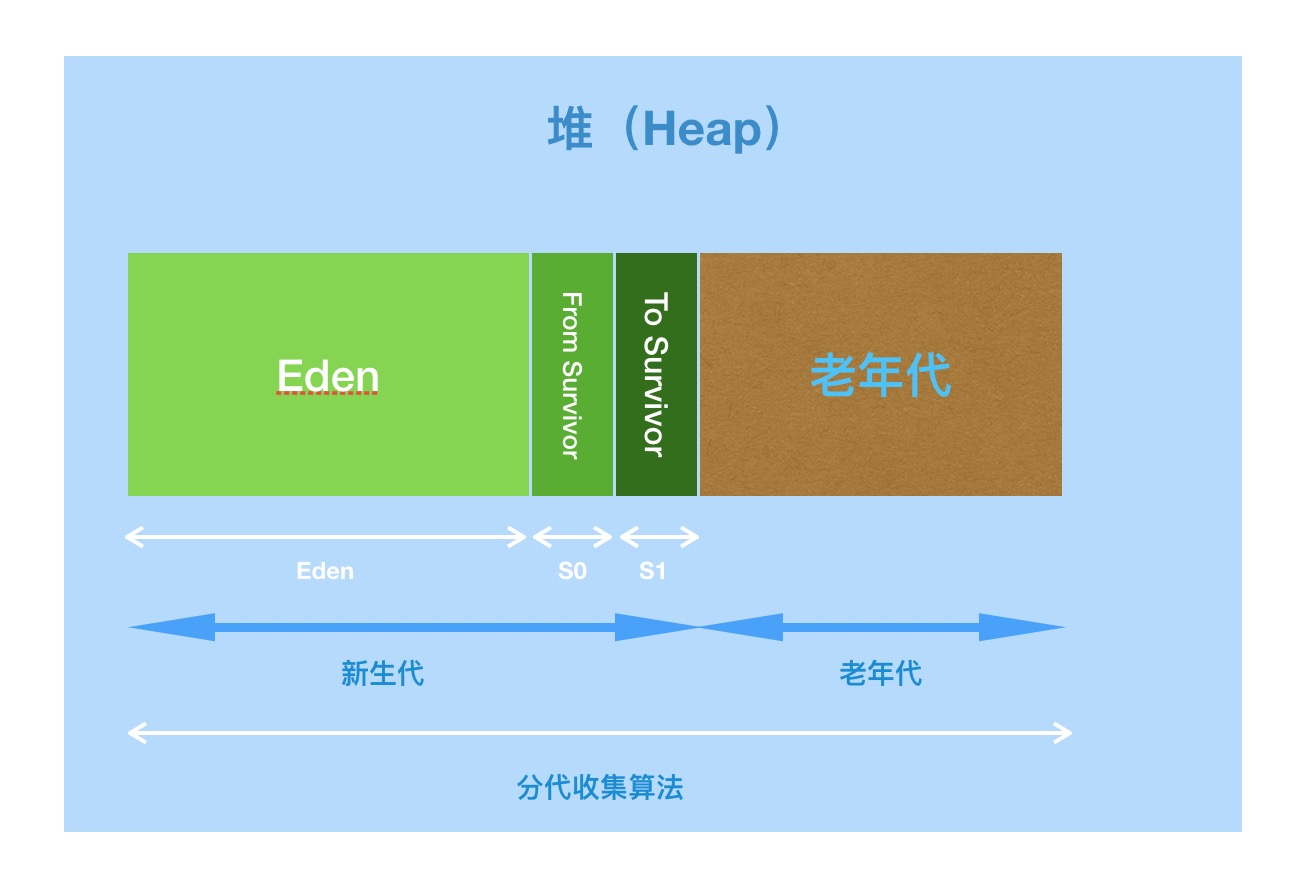
- 对于图示的分析:
- 第一,堆的GC操作采用分代收集算法。
- 第二,堆区分了新生代和老年代;
- 第三,新生代又分为:Eden空间、From Survivor(S0)空间、To Survivor(S1)空间。
- Java虚拟机规范规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可。也就是说堆的内存是一块块拼凑起来的。要增加堆空间时,往上“拼凑”(可扩展性)即可,但当堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
-
方法区(Method Area)
- 方法区与堆有很多共性:线程共享、内存不连续、可扩展、可垃圾回收,同样当无法再扩展时会抛出OutOfMemoryError异常。
- 正因为如此相像,Java虚拟机规范把方法区描述为堆的一个逻辑部分,但目前实际上是与Java堆分开的(Non-Heap)。
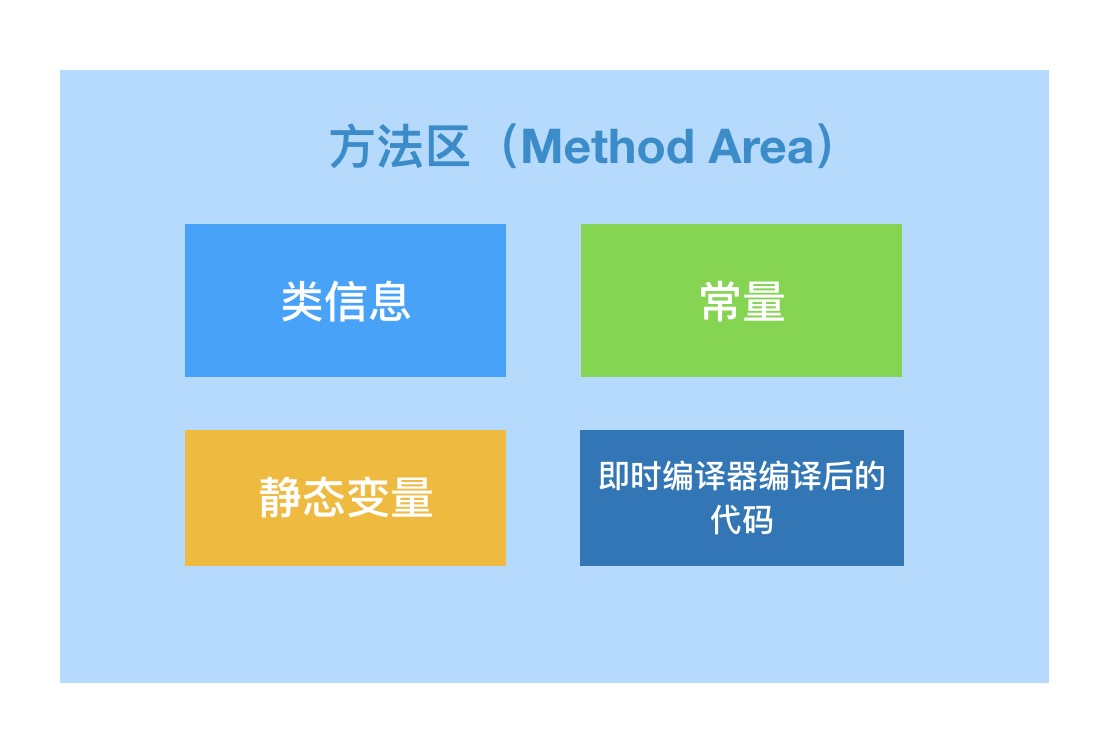
- 方法区个性化的是,它存储的是已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
- 方法区的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是回收确实是有必要的。
-
程序计数器(Program Counter Register)
- 关于程序计数器我们已经得知:占用内存较小,现成私有。它是唯一没有OutOfMemoryError异常的区域。
- 程序计数器的作用可以看做是当前线程所执行的字节码的行号指示器,字节码解释器工作时就是通过改变计数器的值来选取下一条字节码指令。其中,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖计数器来完成。
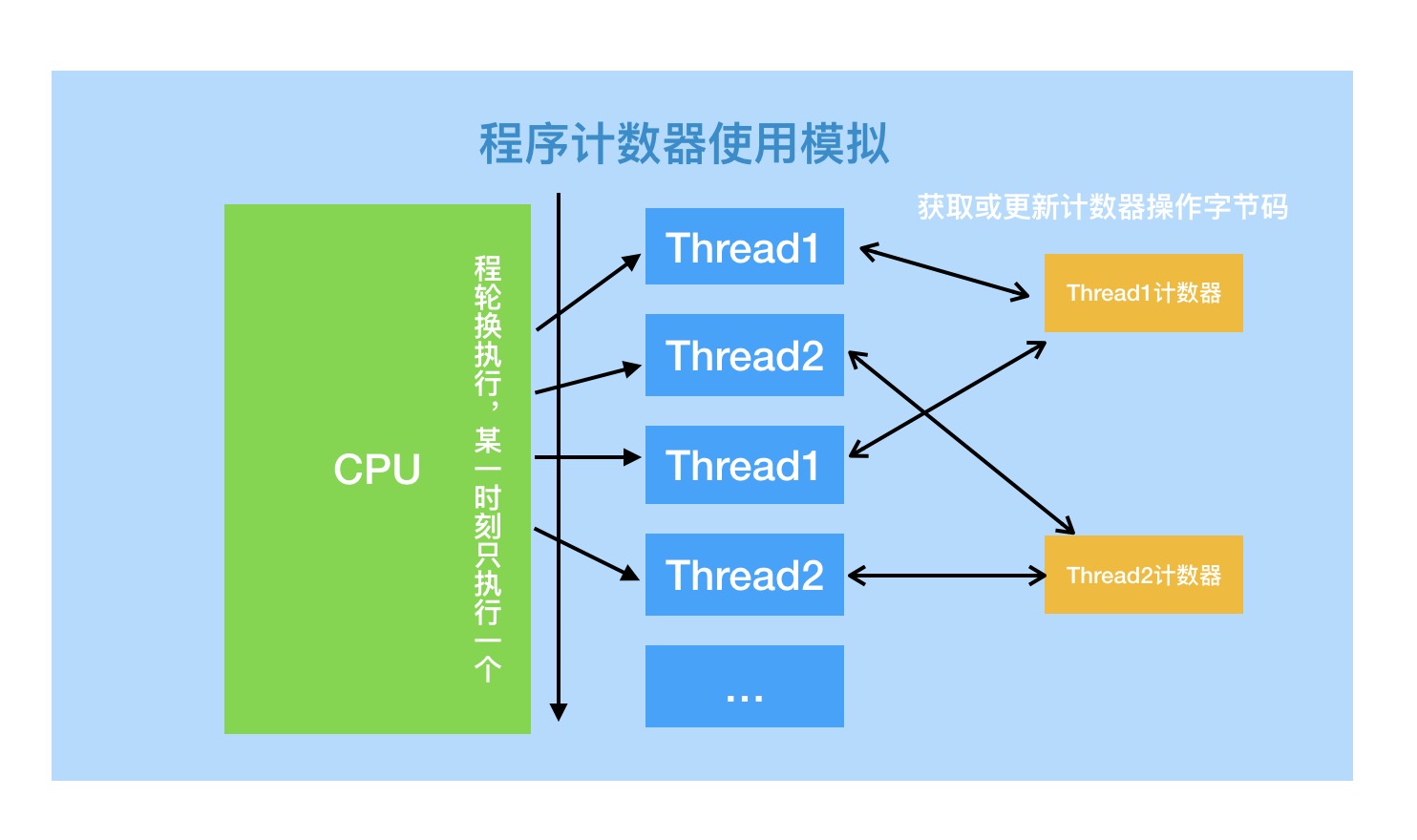
- Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。
- 因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
- 如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie方法,这个计数器值则为空(Undefined)。
-
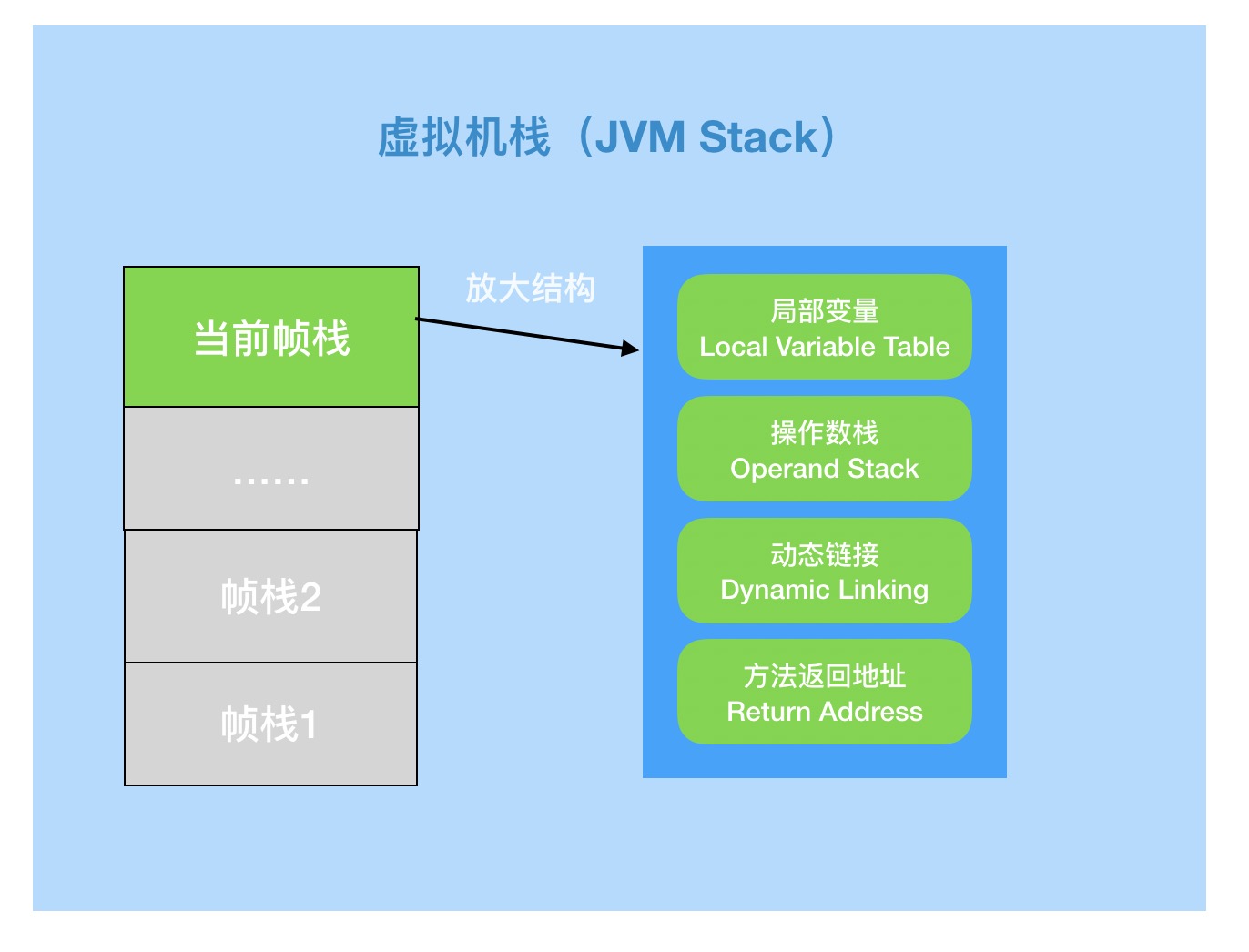
虚拟机栈(JVM Stacks)
-
虚拟机栈线程私有,生命周期与线程相同。
-
栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。每一个方法从调用至执行完成的过程,都对应着一个栈帧在虚拟机栈里从入栈到出栈的过程。
-
图示解析
-
局部变量表(Local Variable Table)是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。包括8种基本数据类型、对象引用(reference类型)和returnAddress类型(指向一条字节码指令的地址)。
其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。
-
如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈动态扩展时无法申请到足够的内存时会抛出OutOfMemoryError异常。
-
操作数栈(Operand Stack)也称作操作栈,是一个后入先出栈(LIFO)。随着方法执行和字节码指令的执行,会从局部变量表或对象实例的字段中复制常量或变量写入到操作数栈,再随着计算的进行将栈中元素出栈到局部变量表或者返回给方法调用者,也就是出栈/入栈操作。
-
动态链接:Java虚拟机栈中,每个栈帧都包含一个指向运行时常量池中该栈所属方法的符号引用,持有这个引用的目的是为了支持方法调用过程中的动态链接(Dynamic Linking)。
-
方法返回:无论方法是否正常完成,都需要返回到方法被调用的位置,程序才能继续进行。
-
-
-
本地方法栈(Native Method Stacks)
- 本地方法栈(Native Method Stacks)与虚拟机栈作用相似,也会抛出StackOverflowError和OutOfMemoryError异常。
- 区别在于虚拟机栈为虚拟机执行Java方法(字节码)服务,而本地方法栈是为虚拟机使用到的Native方法服务。
-
总结
经典算法
-
排序算法的优劣
- 时间复杂度:分析关键字的比较次数和记录的移动次数
- 空间复杂度:分析排序算法中需要多少的辅助内存
- 稳定性:若两个记录A和B的关键字值相等,但排序后A、B的先后次序抱持不变,则称这种排序算法是稳定的
-
排序算法的分类
- 内部排序:整个排序的过程中,不需要借助外部的存储器,所有的排序操作都在内存中完成
- 外部排序:参与排序的数据非常多,数据量非常大,计算机无法把整个排序过程放在内存中完成,必须借助外部存储器。
-
冒泡排序
-
图示
-
示例代码
-

package study1;
import java.util.Scanner;
public class a {
public static void main(String[] args) {
int[] array1 = new int[10];
System.out.println("请输入需要排列的十个整数:");
Scanner getNumber = new Scanner(System.in);
for(int i=0; i<10; i++){
array1[i] = getNumber.nextInt();
}
//冒泡排序
for(int i=0; i<10; i++){
for(int j=0; j<array1.length-1-i; j++){
if(array1[j] > array1[j+1]){
int temp = array1[j];
array1[j] = array1[j+1];
array1[j+1] = temp;
}
}
}
System.out.println("排序完成!");
for(int i=0; i<10; i++){
System.out.println(array1[i]);
}
}
}-
-
理解:
- 思路:对相邻的元素进行两两比较,顺序相反则交换,这样,每趟会将最小(或最大)的元素浮到数组最后面,最终达到整体有序。
- 总结:N个数字要排序完成,总共进行N-1次排序,每i次的排序比较的次数为(N-i)次,所以可以用双重循环语句,外层控制循环多少次,内层控制每一次的比较次数
- 每次循环都会将本次参与循环的数字中的最大的一个放置在最后,因而在之后的每次排序中所参与的数字会一次减少。
-
-
选择排序
-
图示
-
- 示例代码
package study1;
public class a {
public static void main(String[] args) {
int[] array = {11, 21, 4, 65, 32, 7};
for(int i=0; i<array.length; i++){
int minIndex = i;
for(int j=i; j<array.length; j++){
if(array[j] < array[minIndex]){
minIndex = j;
}
}
int temp = array[minIndex];
array[minIndex] = array[i];
array[i] = temp;
}
for(int k=0; k<array.length; k++){
System.out.println(array[k]);
}
}
}- 理解:
- 思路:每次遍历数组,将所遍历的最小值放置在最前,每次完成一次遍历后,调整遍历的起始位置(同时也是将剩余数值筛选出所放置的位置),依次类推。
-
插入排序
-
图示
-
代码示例
package study1;
public class a {
public static void main(String[] args) {
int[] array = {11, 21, 4, 65, 32, 7};
int current;
for (int i = 0; i < array.length - 1; i++) {
current = array[i + 1]; // 当前排序到的元素
int preIndex = i; // 已经排序完成的最后一个元素的下标
// 将当前排序的元素与每个已完成排序的元素比较
while (preIndex >= 0 && current < array[preIndex]) {
array[preIndex + 1] = array[preIndex];
preIndex--;
}
array[preIndex + 1] = current;
}
for(int j=0; j<array.length; j++){
System.out.println(array[j]);
}
}
}-
-
理解:
- 思路:将第一个元素视为已经排序完成的元素,从第二个开始与排序好的元素比较,若待排序元素小于当前比较的排序好的元素,那么将该比较大的排序好的元素向后移动,再次将待排序的元素与前一个已经完成排序的元素比较,重复此过程,直到待排序元素匹配到某个已完成排序的元素时添加到其后面。
-
二维数组
-
静态初始化:
int[][] arr = new int[][]{ {1, 2, 3}, {"a", "b", "c"}}; -
动态初始化:
String[][] arr2 = new String[2][3];(第二个数组可以暂时不去指定元素个数) -
注意:二维数组中的外层元素保存的是地址值(内层数组,数组为引用数据类型),也就是说,若不给二维数组初始化将保存的值为null(引用数据类型的默认值)
-
杨辉三角
package study1;
public class a {
public static void main(String[] args) {
int[][] array = new int[10][];
for(int i=0; i<array.length; i++){
array[i] = new int[i + 1];
array[i][0] = array[i][i] = 1;
if(i>1){
for(int j=1; j<array[i].length -1; j++){
array[i][j] = array[i-1][j-1] + array[i-1][j];
}
}
}
for(int i=0; i<array.length; i++){
for(int j=0; j<array[i].length; j++){
System.out.print(array[i][j] + "\t");
}
System.out.println();
}
}
}数组的工具类
java.util.Arrays:操作数组的工具类- 常用方法示例
Arrays.equals(a, b)比较两个数组是否相同Arrays.toString(a)以字符串的形式输出数组Arrays.fill(a, value)将数组中所有的元素替换为指定的值Arrays.sort(b)将数组排序(快速排序)Arrays.binarySearch(b, 1)使用二分法查找有序数组(返回值为复数则未找到指定元素)
2|0面向对象
对象和类
- 对象:对象是类的一个实例(对象不是找个女朋友),有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等。
- 匿名对象 :为被赋予名的对象,示例:
new Phone().function··· - 类:类是一个模板,它描述一类对象的行为和状态。
类的定义
-
示例
public class Dog{
String breed;
int age;
String color;
void barking(){
}
void hungry(){
}
void sleeping(){
}
}-
一个类可以包含以下类型变量:
- 局部变量:在方法、构造方法或者语句块中定义的变量被称为局部变量。变量声明和初始化都是在方法中,方法结束后,变量就会自动销毁。
- 成员变量:成员变量是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。
- 类变量:类变量也声明在类中,方法体之外,但必须声明为 static 类型。
构造方法
-
每个类都有构造方法。如果没有显式地为类定义构造方法,Java 编译器将会为该类提供一个默认构造方法。
-
在创建一个对象的时候,至少要调用一个构造方法。构造方法的名称必须与类同名,一个类可以有多个构造方法。
-
示例
public class Puppy{
public Puppy(){ // 没有返回值
}
public Puppy(String name){
// 这个构造器仅有一个参数:name
}
}创建对象
-
对象是根据类创建的。在Java中,使用关键字 new 来创建一个新的对象。创建对象需要以下三步:
- 声明:声明一个对象,包括对象名称和对象类型。
- 实例化:使用关键字 new 来创建一个对象。
- 初始化:使用 new 创建对象时,会调用构造方法初始化对象。
-
示例
public class Puppy{
public Puppy(String name){
//这个构造器仅有一个参数:name
System.out.println("小狗的名字是 : " + name );
}
public static void main(String[] args){
// 下面的语句将创建一个Puppy对象
Puppy myPuppy = new Puppy( "tommy" );
}
}源文件声明规则
- 一个源文件中只能有一个 public 类
- 一个源文件可以有多个非 public 类
- 源文件的名称应该和 public 类的类名保持一致。例如:源文件中 public 类的类名是 Employee,那么源文件应该命名为Employee.java。
- 如果一个类定义在某个包中,那么 package 语句应该在源文件的首行。
- 如果源文件包含 import 语句,那么应该放在 package 语句和类定义之间。如果没有 package 语句,那么 import 语句应该在源文件中最前面。
- import 语句和 package 语句对源文件中定义的所有类都有效。在同一源文件中,不能给不同的类不同的包声明。
Java包
- 包主要用来对类和接口进行分类。当开发 Java 程序时,可能编写成百上千的类,因此很有必要对类和接口进行分类。
import语句
- 在 Java 中,如果给出一个完整的限定名,包括包名、类名,那么 Java 编译器就可以很容易地定位到源代码或者类。import 语句就是用来提供一个合理的路径,使得编译器可以找到某个类。
- 示例:
import java.util.*; - package 的作用就是 c++ 的 namespace 的作用,防止名字相同的类产生冲突。Java 编译器在编译时,直接根据 package 指定的信息直接将生成的 class 文件生成到对应目录下。如 package aaa.bbb.ccc 编译器就将该 .java 文件下的各个类生成到 ./aaa/bbb/ccc/ 这个目录。
成员变量和类变量
-
由static修饰的变量称为静态变量,其实质上就是一个全局变量。如果某个内容是被所有对象所共享,那么该内容就应该用静态修饰;没有被静态修饰的内容,其实是属于对象的特殊描述。
-
不同的对象的实例变量将被分配不同的内存空间, 如果类中的成员变量有类变量,那么所有对象的这个类变量都分配给相同的一处内存,改变其中一个对象的这个类变量会影响其他对象的这个类变量,也就是说对象共享类变量。
-
成员变量和类变量的区别:
- 两个变量的生命周期不同
-
成员变量随着对象的创建而存在,随着对象的回收而释放。
-
静态变量随着类的加载而存在,随着类的消失而消失。
- 调用方式不同
-
成员变量只能被对象调用。
-
静态变量可以被对象调用,还可以被类名调用。
- 别名不同
-
成员变量也称为实例变量。
-
静态变量也称为类变量。
- 数据存储位置不同
-
成员变量存储在堆内存的对象中,所以也叫对象的特有数据。
-
静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据
-
static关键字
-
static 关键字,是一个修饰符,用于修饰成员(成员变量和成员函数)。
1、想要实现对象中的共性数据的对象共享。可以将这个数据进行静态修饰。
2、被静态修饰的成员,可以直接被类名所调用。也就是说,静态的成员多了一种调用方式。类名.静态方式。
3、静态随着类的加载而加载。而且优先于对象存在。
-
注意
1、有些数据是对象特有的数据,是不可以被静态修饰的。因为那样的话,特有数据会变成对象的共享数据。这样对事物的描述就出了问题。所以,在定义静态时,必须要明确,这个数据是否是被对象所共享的。
2、静态方法只能访问静态成员,不可以访问非静态成员。因为静态方法加载时,优先于对象存在,所以没有办法访问对象中的成员。
3、静态方法中不能使用this,super关键字。因为this代表对象,而静态在时,有可能没有对象,所以this无法使用
-
是否真的需要静态成员
1、成员变量。(数据共享时静态化)
该成员变量的数据是否是所有对象都一样:
如果是,那么该变量需要被静态修饰,因为是共享的数据。
如果不是,那么就说这是对象的特有数据,要存储到对象中。
2、成员函数。(方法中没有调用特有数据时就定义成静态)
如果判断成员函数是否需要被静态修饰呢?
只要参考,该函数内是否访问了对象中的特有数据:
如果有访问特有数据,那方法不能被静态修饰。
如果没有访问过特有数据,那么这个方法需要被静态修饰。
-
成员变量和静态变量的区别:
1、成员变量所属于对象。所以也称为实例变量。
静态变量所属于类。所以也称为类变量。
2、成员变量存在于堆内存中。
静态变量存在于方法区中。
3、成员变量随着对象创建而存在。随着对象被回收而消失。
静态变量随着类的加载而存在。随着类的消失而消失。
4、成员变量只能被对象所调用 。
静态变量可以被对象调用,也可以被类名调用。
所以,成员变量可以称为对象的特有数据,静态变量称为对象的共享数据。
-
类的构造方法
- 说明:
- 当一个对象被创建时候,构造方法用来初始化该对象。构造方法和它所在类的名字相同,但构造方法没有返回值。
- 通常会使用构造方法给一个类的实例变量赋初值,或者执行其它必要的步骤来创建一个完整的对象。
- 不管你是否自定义构造方法,所有的类都有构造方法,因为Java自动提供了一个默认构造方法,默认构造方法的访问修改符和类的访问修改符相同(类为 public,构造函数也为 public;类改为 protected,构造函数也改为 protected)。
- 一旦你定义了自己的构造方法,默认构造方法就会失效。
1、构造方法的名字和类名相同,并且没有返回值。
2、构造方法主要用于为类的对象定义初始化状态。
3、我们不能直接调用构造方法,必须通过new关键字来自动调用,从而创建类的实例。
4、Java的类都要求有构造方法,如果没有定义构造方法,Java编译器会为我们提供一个缺省的构造方法,也就是不带参数的构造方法。
-
new关键字的作用
1、为对象分配内存空间。
2、引起对象构造方法的调用。
3、为对象返回一个引用。
方法
-
命名规则
- 方法的名字的第一个单词应以小写字母作为开头,后面的单词则用大写字母开头写,不使用连接符。例如:addPerson。
- 下划线可能出现在 JUnit 测试方法名称中用以分隔名称的逻辑组件。一个典型的模式是:test< MethodUnderTest>_< state>,例如 testPop_emptyStack。
-
语法示例
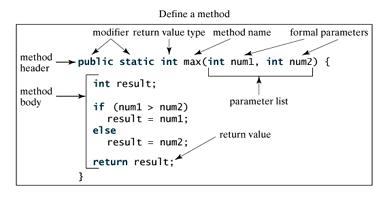
修饰符 返回值类型 方法名(参数类型 参数名){ ... 方法体 ... return 返回值; }
-
修饰符:修饰符,这是可选的,告诉编译器如何调用该方法。定义了该方法的访问类型。
-
返回值类型 :方法可能会返回值。returnValueType 是方法返回值的数据类型。有些方法执行所需的操作,但没有返回值。在这种情况下,returnValueType 是关键字void。
-
方法名:是方法的实际名称。方法名和参数表共同构成方法签名。
-
参数类型:参数像是一个占位符。当方法被调用时,传递值给参数。这个值被称为实参或变量。参数列表是指方法的参数类型、顺序和参数的个数。参数是可选的,方法可以不包含任何参数。
-
方法体:方法体包含具体的语句,定义该方法的功能。
-
-
可变参数
-
可变参数的声明:
typeName... parameterName- 在方法声明中,在指定参数类型后加一个省略号(...)
- 一个方法中只能指定一个可变参数,它必须是方法的最后一个参数。任何普通的参数必须在它之前声明。
- 该参数等同于一个相同类型数组(且与其不会构成重载)
-
注意!区分值传递和引用传递
-
示例
-
package study1;
public class a {
public static void main(String[] args) {
fun(1, 22, 31, 2, 44, 21, 98);
fun(new int[]{1, 22, 31, 2, 44, 21, 98});
}
public static void fun(int... numbers){
if (numbers.length == 0) {
System.out.println("No argument passed");
return;
}
int result = numbers[0];
for (int i = 1; i < numbers.length; i++){
if (numbers[i] > result) {
result = numbers[i];
}
}
System.out.println("The max value is " + result);
}
}-
finalize方法-
Java 允许定义这样的方法,它在对象被垃圾收集器析构(回收)之前调用,这个方法叫做 finalize( ),它用来清除回收对象。
-
在 finalize() 方法里,你必须指定在对象销毁时候要执行的操作。
-
当然,Java 的内存回收可以由 JVM 来自动完成。如果你手动使用,则可以使用上面的方法。
-
该函数的一般格式
protected void finalize() // 关键字 protected 是一个限定符,它确保 finalize() 方法不会被该类以外的代码调用。 { // 在这里终结代码 }
-
方法调用
- Java 支持两种调用方法的方式,根据方法是否返回值来选择。
- 当程序调用一个方法时,程序的控制权交给了被调用的方法。当被调用方法的返回语句执行或者到达方法体闭括号时候交还控制权给程序。
- 当方法返回一个值的时候,方法调用通常被当做一个值。
int larger = max(30, 40);
- 如果方法返回值是void,方法调用一定是一条语句
System.out.println("Hello Java");
Tip:注意!在一些其它语言中方法指过程和函数。一个返回非void类型返回值的方法称为函数;一个返回void类型返回值的方法叫做过程。
方法重载
- 一个类的两个方法拥有相同的名字,但是有不同的参数列表。
- Java编译器根据方法签名(方法名和参数列表)判断哪个方法应该被调用。
- 方法重载可以让程序更清晰易读。执行密切相关任务的方法应该使用相同的名字。
- 重载的方法必须拥有不同的参数列表。你不能仅仅依据修饰符或者返回类型的不同来重载方法。
- 规则:
- 方法名称必须相同。
- 参数列表必须不同。
- 方法的返回类型可以相同也可以不相同。
- 仅仅返回类型不同不足以称为方法的重载。
- 方法重载可能会因为没有所满足的参数类型而出现自动的类型提升以便于调用适用的方法
递归
-
一个方法在内部调用自身称为递归调用
-
方法的递归包含了一种隐式的循环,他会重复指定某段代码,但是这种循环执行无需循环的控制
-
递归一定要已知方向递归(临界条件),否则将会称为无穷递归(类似与死循环)
-
简单示例
// 递归求和 public static int fun(int x){ if(x == 1){ return 1; }else{ return x + fun(x - 1); } }
变量的作用域
-
变量的范围是程序中该变量可以被引用的部分。
-
方法内定义的变量被称为局部变量。
-
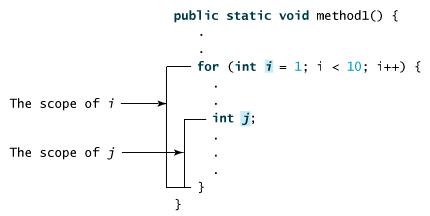
局部变量的作用范围从声明开始,直到包含它的块结束。
-
局部变量必须声明才可以使用。
-
方法的参数范围涵盖整个方法。参数实际上是一个局部变量。
-
for循环的初始化部分声明的变量,其作用范围在整个循环。
-
但循环体内声明的变量其适用范围是从它声明到循环体结束。它包含如下所示的变量声明:
-
你可以在一个方法里,不同的非嵌套块中多次声明一个具有相同的名称局部变量,但你不能在嵌套块内两次声明局部变量。
Tip:命令行参数是在执行程序时候紧跟在程序名字后面的信息。