cat <<END>prometheus.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
namespace: istio-system
annotations:
{}
---
# Source: prometheus/templates/server/cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
namespace: istio-system
data:
alerting_rules.yml: |
groups:
- name: node.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "Instance {
{ $labels.instance }} 停止工作"
description: "{
{ $labels.instance }} job {
{ $labels.job }} 已经停止1分钟以上."
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} : {
{ $labels.mountpoint }} 分区使用率过高"
description: "{
{ $labels.instance }}: {
{ $labels.mountpoint }} 分区使用大于80% (当前值: {
{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} 内存使用率过高"
description: "{
{ $labels.instance }}内存使用大于80% (当前值: {
{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {
{ $labels.instance }} CPU使用率过高"
description: "{
{ $labels.instance }}CPU使用大于60% (当前值: {
{ $value }})"
- alert: Node_IO性能
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 2m
labels:
status: 严重告警
annotations:
summary: "{
{$labels.mountpoint}} 流入磁盘IO使用率过高!"
description: "{
{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{
{$value}})"
- alert: Node_网络流入
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2m
labels:
status: 严重告警
annotations:
summary: "{
{$labels.mountpoint}} 流入网络带宽过高!"
description: "{
{$labels.mountpoint }}流入网络带宽持续2分钟高于100M. RX带宽使用率:{
{$value}})"
- alert: Node_网络流出
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 2m
labels:
status: 严重告警
annotations:
summary: "{
{$labels.mountpoint}} 流出网络带宽过高!"
description: "{
{$labels.mountpoint }}流出网络带宽持续2分钟高于100M. TX带宽使用率:{
{$value}})"
- alert: Node_TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: 严重告警
annotations:
summary: "{
{$labels.mountpoint}} TCP_ESTABLISHED过高!"
description: "{
{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{
{$value}}%)"
- alert: JobDown #检测job的状态,持续5分钟metrices不能访问会发给altermanager进行报警
expr: up == 0 #0不正常,1正常
for: 5m #持续时间 , 表示持续5分钟获取不到信息,则触发报警
labels:
severity: error
cluster: k8s
annotations:
summary: "Job: {
{ $labels.job }} down"
description: "Instance:{
{ $labels.instance }}, Job {
{ $labels.job }} stop "
- alert: PodDown
expr: kube_pod_container_status_running != 1
for: 2s
labels:
severity: warning
cluster: k8s
annotations:
summary: 'Container: {
{ $labels.container }} down'
description: 'Namespace: {
{ $labels.namespace }}, Pod: {
{ $labels.pod }} is not running'
- alert: PodReady
expr: kube_pod_container_status_ready != 1
for: 5m #Ready持续5分钟,说明启动有问题
labels:
severity: warning
cluster: k8s
annotations:
summary: 'Container: {
{ $labels.container }} ready'
description: 'Namespace: {
{ $labels.namespace }}, Pod: {
{ $labels.pod }} always ready for 5 minitue'
- alert: PodRestart
expr: changes(kube_pod_container_status_restarts_total[3m])>0 #最近3分钟pod重启
for: 2s
labels:
severity: warning
cluster: k8s
annotations:
summary: 'Container: {
{ $labels.container }} restart'
description: 'namespace: {
{ $labels.namespace }}, pod: {
{ $labels.pod }} restart {
{ $value }} times'
- alert: Pod_all_cpu_usage #相当于zabbix中的监控项;也是邮件的标题
expr: (sum by(name)(rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 75 #promql查询语句查询到所有pod的CPU利用率与后面的值做对比,查询到的是浮点数,需要乘以100,转换成整数
for: 5m #每5分钟获取一次POD的CPU利用率
labels:
severity: critical
cluster: k8s
annotations: #此为当前所有容器的CPU利用率
summary: 'Container: {
{ $labels.container }} CPU 负载告警'
description: 'namespace: {
{ $labels.namespace }}, pod: {
{ $labels.pod }} CPU 资源利用率大于 75% , ( {
{ $value }})' #报警的描述信息内容
- alert: Pod_all_memory_usage
expr: sort_desc(avg by(name)(irate(container_memory_usage_bytes{name!=""} [5m]))*100) > 1024^3*2 #通过promql语句获取到所有pod中内存利用率;将后面的单位G转换成字节
for: 10m
labels:
severity: critical
cluster: k8s
annotations:
summary: 'Container: {
{ $labels.container }} Memory 负载告警'
description: 'namespace: {
{ $labels.namespace }}, pod: {
{ $labels.pod }} Memory 资源利用率大于 2G , (当前已用内存是: {
{ $value }})'
- alert: Pod_all_network_receive_usage
expr: sum by (name)(irate(container_network_receive_bytes_total{container_name="POD"}[1m])) > 1024*1024*50
for: 10m #获取的所有pod网络利用率是字节,所以把后面对比的Mb转换成字节
labels:
severity: critical
cluster: k8s
annotations:
description: 'namespace: {
{ $labels.namespace }}, pod: {
{ $labels.pod }} 资源利用率大于 50M , (current value is {
{ $value }})' #这些promql语句都是通过grafana,找到相应的监控项,点击edit找到相应的promql语句即可
# alerts: |
# alertmanagers:
# - static_configs:
# - targets: ['alertmanager:9093']
prometheus.yml: |
global:
evaluation_interval: 1m
scrape_interval: 15s
scrape_timeout: 10s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
- /etc/config/rules
- /etc/config/alerts
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
#- 192.168.8.88:9182
consul_sd_configs:
- server: "consul:8500"
tags:
- "prometheus"
refresh_interval: 10s
- job_name: nodes
consul_sd_configs:
- server: "consul:8500"
tags:
- "nodes"
refresh_interval: 10s
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-nodes
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$1/proxy/metrics
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$1/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: kubernetes_node
- job_name: kubernetes-service-endpoints-slow
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: kubernetes_node
scrape_interval: 5m
scrape_timeout: 30s
- honor_labels: true
job_name: prometheus-pushgateway
kubernetes_sd_configs:
- role: service
relabel_configs:
- action: keep
regex: pushgateway
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- action: drop
regex: Pending|Succeeded|Failed
source_labels:
- __meta_kubernetes_pod_phase
- job_name: kubernetes-pods-slow
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape_slow
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- action: drop
regex: Pending|Succeeded|Failed
source_labels:
- __meta_kubernetes_pod_phase
scrape_interval: 5m
scrape_timeout: 30s
recording_rules.yml: |
{}
rules: |
{}
---
# Source: prometheus/templates/server/clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- nodes/metrics
- services
- endpoints
- pods
- ingresses
- configmaps
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
- "networking.k8s.io"
resources:
- ingresses/status
- ingresses
verbs:
- get
- list
- watch
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
# Source: prometheus/templates/server/clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: istio-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
---
# Source: prometheus/templates/server/service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
namespace: istio-system
spec:
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
nodePort: 19090
selector:
component: "server"
app: prometheus
release: prometheus
sessionAffinity: None
type: "NodePort"
---
# Source: prometheus/templates/server/deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
name: prometheus
namespace: istio-system
spec:
selector:
matchLabels:
component: "server"
app: prometheus
release: prometheus
replicas: 1
template:
metadata:
annotations:
sidecar.istio.io/inject: "false"
labels:
component: "server"
app: prometheus
release: prometheus
chart: prometheus-11.16.2
heritage: Helm
spec:
serviceAccountName: prometheus
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.4.0"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://127.0.0.1:9090/-/reload
resources:
{}
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
- name: prometheus-server
image: "prom/prometheus:v2.21.0"
imagePullPolicy: "IfNotPresent"
args:
- --storage.tsdb.retention.time=15d
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 0
periodSeconds: 5
timeoutSeconds: 30
failureThreshold: 3
successThreshold: 1
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
periodSeconds: 15
timeoutSeconds: 30
failureThreshold: 3
successThreshold: 1
resources:
{}
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: /data
subPath: ""
securityContext:
fsGroup: 65534
runAsGroup: 65534
runAsNonRoot: true
runAsUser: 65534
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus
- name: storage-volume
emptyDir:
{}
END
告警规则
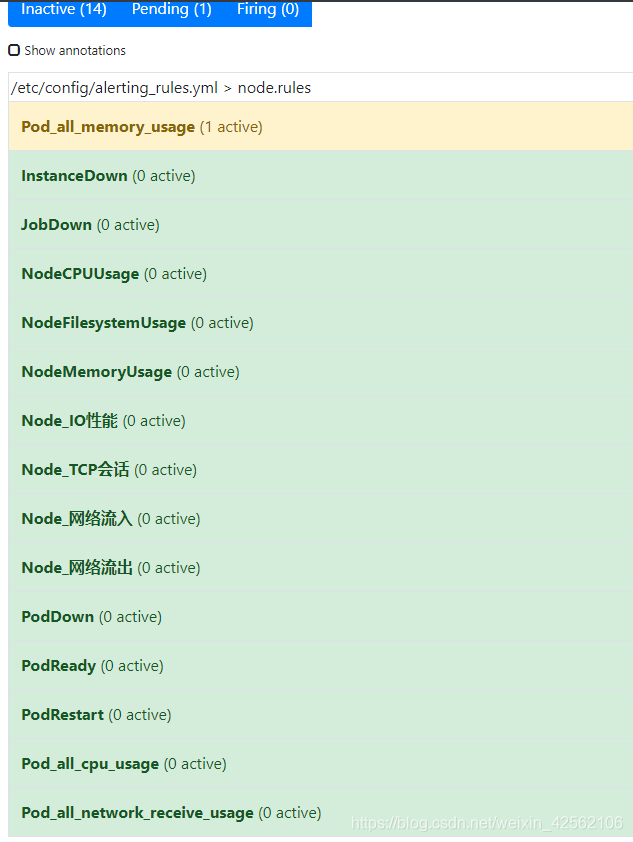
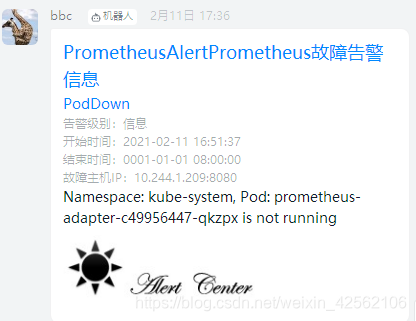
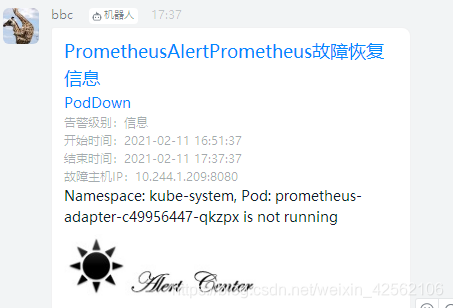
告警部署地址
https://gitee.com/jbjb123/prometheus/tree/master/new-demon