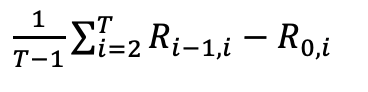1 什么是lifelong learning
Lifelong learning终生学习,又名continuous learning,increment learning,never ending learning。通常机器学习中,单个模型只解决单个或少数几个任务。对于新的任务,我们一般重新训练新的模型。而LifeLong learning,则先在task1上使用一个模型,然后在task2上仍然使用这个模型,一直到task n。Lifelong learning探讨的问题是,一个模型能否在很多个task上表现都很好。如此下去,模型能力就会越来越强。这和人类不停学习新的知识,从而掌握很多不同知识,是异曲同工的。
LifeLong learning需要解决三个问题
- Knowledge Retention 知识记忆。我们不希望学完task1的模型,在学习task2后,在task1上表现糟糕。也就是希望模型有一定的记忆能力,能够在学习新知识时,不要忘记老知识。但同时模型不能因为记忆老知识,而拒绝学习新知识。总之在新老task上都要表现比较好。
- Knowledge Transfer 知识迁移。我们希望学完task1的模型,能够触类旁通,即使不学习task2的情况下,也能够在task2上表现不错。也就是模型要有一定的迁移能力。这个和transfer learning有些类似。
- Model Expansion 模型扩张。一般来说,由于需要学习越来越多的任务,模型参数需要一定的扩张。但我们希望模型参数扩张是有效率的,而不是来一个任务就扩张很多参数。这会导致计算和存储问题。
2 Knowledge Retention 知识记忆
出现知识遗忘其实很容易理解。试想一下,训练完task1后,我们得到了一个模型。再利用这个模型在task2上进行训练时,会对模型参数进行一定调整。如果参数调整方向和task1的gradient方向相反,则会导致模型在task1上表现变差。那怎么让task1的知识能够得到保留呢?显然我们需要对模型参数更新做一些限制,让它不要偏离task1太远。
2.1 EWC
EWC(Elastic Weight Consolidation)就是用来解决这个问题的。它在Loss函数上加入了一个正则,使得模型参数更新必须满足一定条件,如下
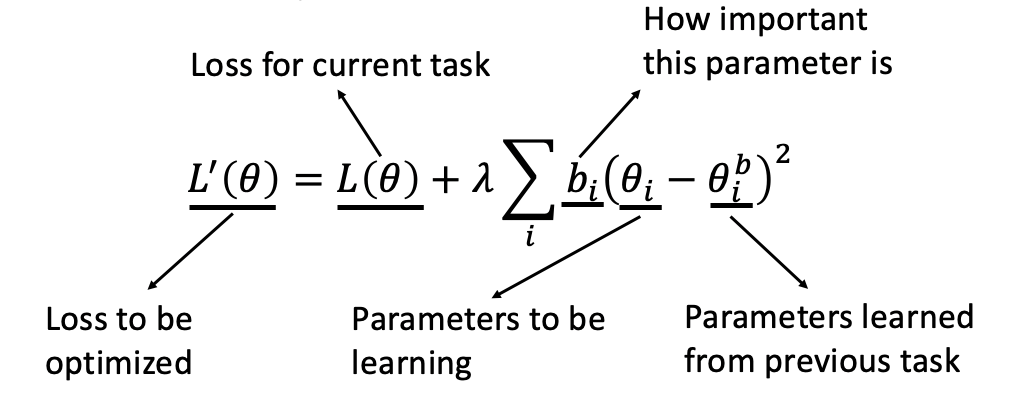
- L(θ)为原始的loss function,后面一项为正则项。
- bi为参数更新权重,表示参数θi有多重要,能不能变化太多
- θi为需要更新的参数,θib为该参数在之前任务上学到的数值。
bi为参数更新权重,表示参数θi能不能变化太多,试想一下
- 如果bi很大,则表明θi不能和θib差距过大,也就是尽量不要动θi
- 如果bi很小,则表明θi的变化,不会对最终loss带来很大的影响。
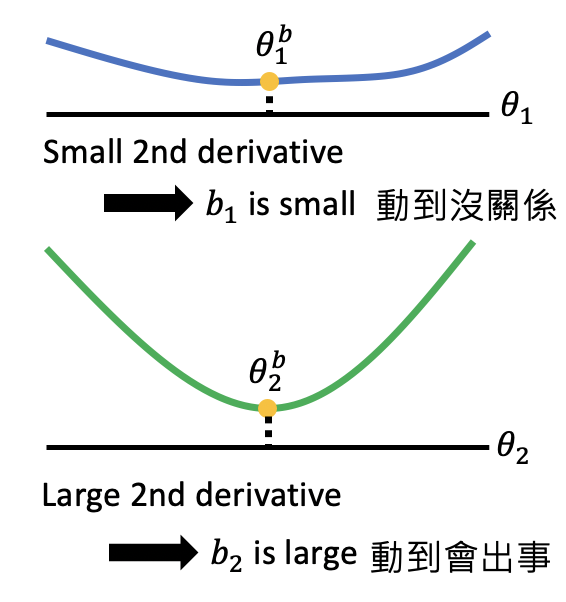
有了正则项和bi后,我们就能指导模型合理的更新参数,从而避免忘记之前的task。那问题来了,bi怎么得到呢?EWC给出了它的解决方案。它利用二阶导数来确定bi。如果二阶导数比较小,位于一个平坦的盆地中,则表明参数变化对task影响小,此时bi小。如果二阶导数比较大,位于一个狭小的山谷中,则表明参数变化对task影响大,此时bi大。
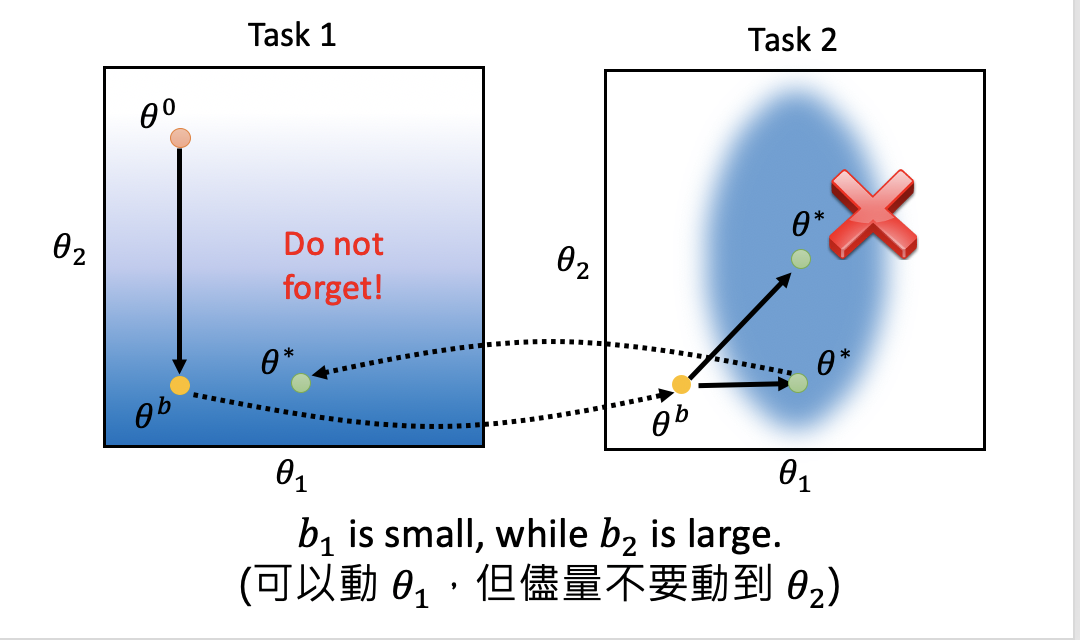
利用EWC后的效果如下图所示。蓝色越深代表模型效果越好。假如模型有两个参数θ1和θ2,在task1上训练后,参数更新为θb。在task2上更新参数时,有很多个不同的参数组合,都可以在task2上表现很好(蓝色区域)。如果我们沿斜上方更新参数,虽然task2效果好,但在task1上效果却很差,也就是出现了遗忘问题。如果我们沿水平方向更新参数,也就是θ1的方向,则task1上模型效果依然OK。这表明,通过EWC是可以做到让模型记住以前学到的知识的。
2.2 生成样本
还有一种思路,在学习task2时,我们可以利用生成模型,生成task1的样本。然后利用task1和task2的样本,进行多任务学习,使得模型在两个task上均表现很好。这里的难点在于,生成样本,特别是复杂的样本,目前难度是很大的。可以作为一个idea参考,但个人认为可行性不高。
3 Knowledge Transfer 知识迁移
终生学习也对模型提出了另一个要求,那就是迁移能力。通过学习task1、task2等多个task,在不学习task n的情况下,模型是否能举一反三,表现仍然不错呢。
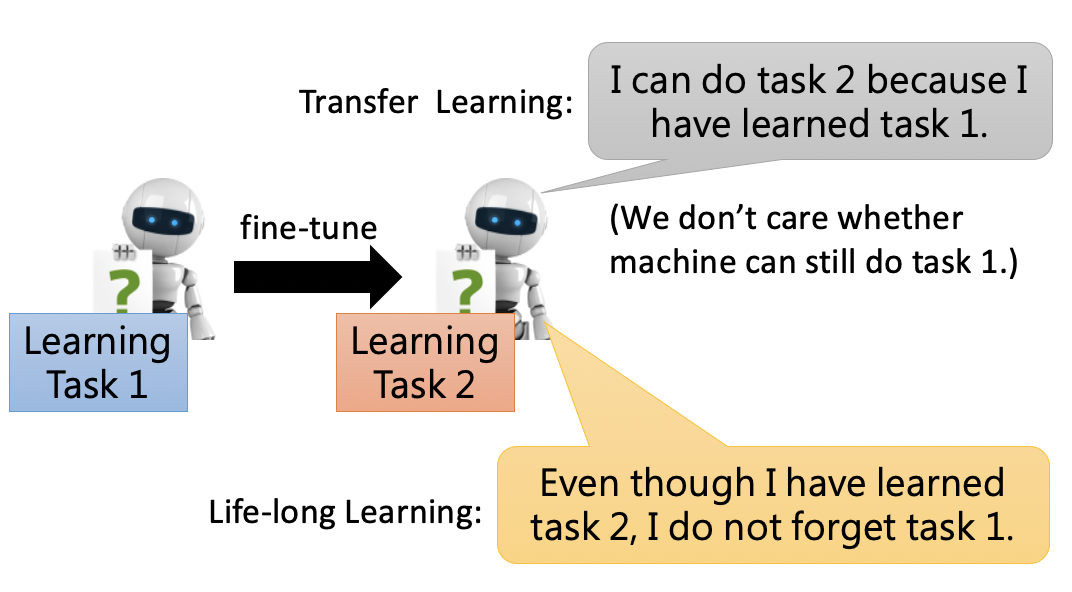
终生学习和迁移学习有一些类似的地方。区别在于迁移学习只关注迁移后模型在target task上要表现好,至于source task则不关心。而终生学习则需要模型在两个task上都表现好,不能出现遗忘。可以将终生学习理解为更严格的迁移学习。
4 Model Expansion 模型扩张
一般来说,由于需要学习越来越多的任务,模型参数需要一定的扩张。但我们希望模型参数扩张是有效率的,而不是来一个任务就扩张很多参数。这会导致计算和存储问题。所以怎么对模型参数进行有效率的扩张,就显得十分关键了。
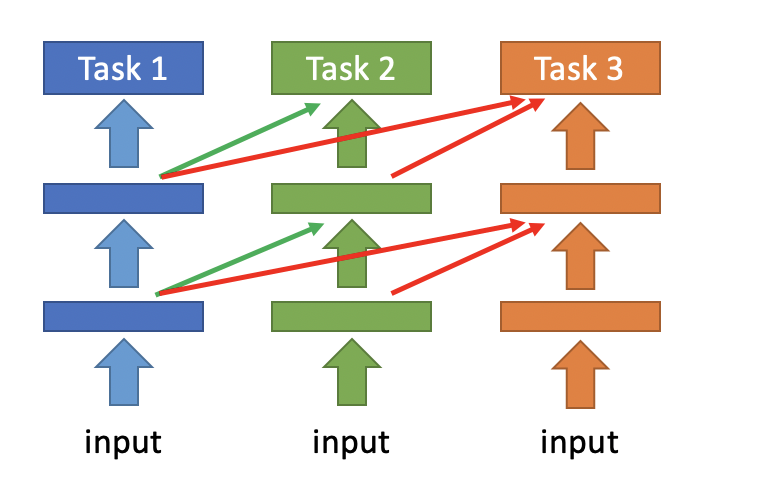
一种方法是progressive neural network。它将task1每层输出的feature,作为task2对应层的输入,从而让模型在学习后面task的时候,能够记住之前task的一些信息。如下图
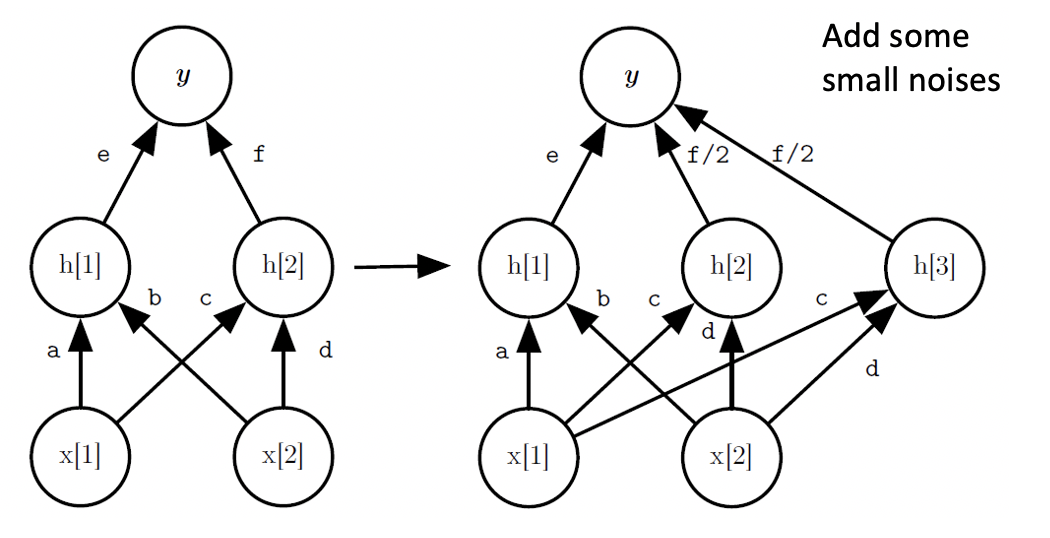
另一种方法是Net2Net。它对网络进行加宽。如下图所示,由神经元h2分裂得到一个神经元h3。初始时和h2一样,h2和h3权重均为之前h2权重的一半。为了防止h2和h3训练过程中始终保持一致,故在h3上添加一些小噪声,使二者能够独立更新。
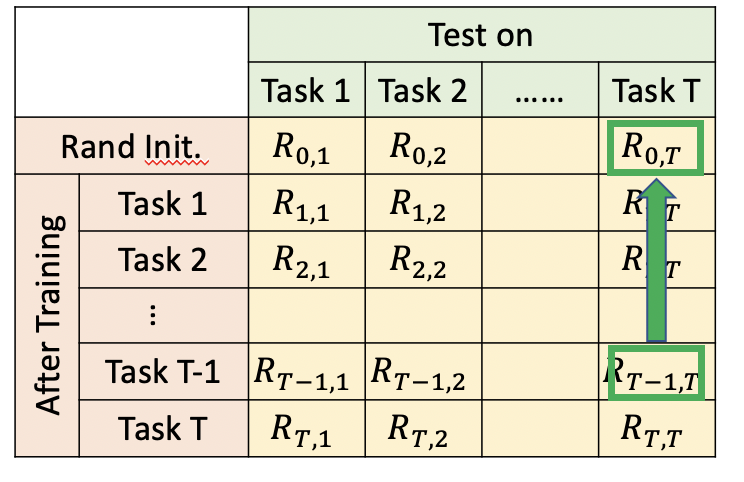
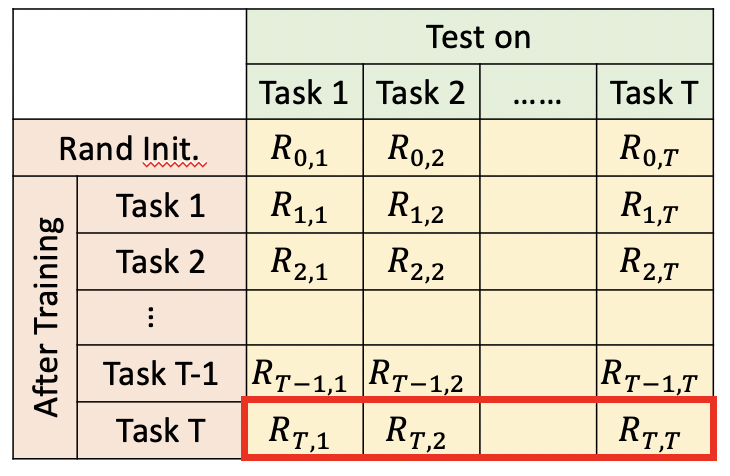
5 评价方法
终生学习模型的评价,也很重要。如下图我们构建一个table。横轴表示学习完某个task后,在其他task上的表现。纵轴表示某个task,在其他task学习完后的表现。综合下来
- 当i>j时,表示学习完task i后,task j有没有被忘记。代表模型记忆能力
- 当i<j时,表示学习完task i后,模型在还没有学习的任务task j,上的表现。代表模型迁移能力。
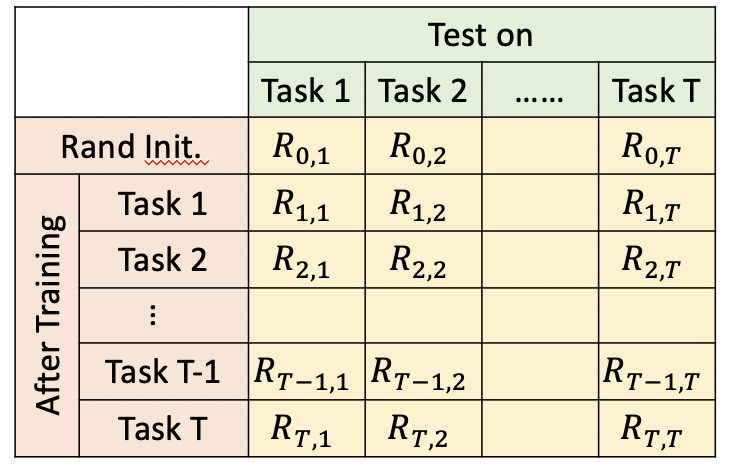
评估主要包括三个指标
- ACC
- 记忆能力
- 迁移能力
5.1 ACC
模型准确率ACC为,学习完最后一个任务task T后,模型在task1、task2、task T-1上的平均准确率。
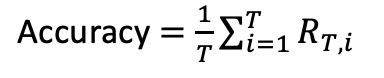
5.2 记忆能力
记忆能力衡量了模型学习完最后一个任务task T后,在之前task上的表现。一般来说,模型会忘记之前task,所以这个指标一般为负数
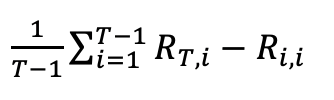
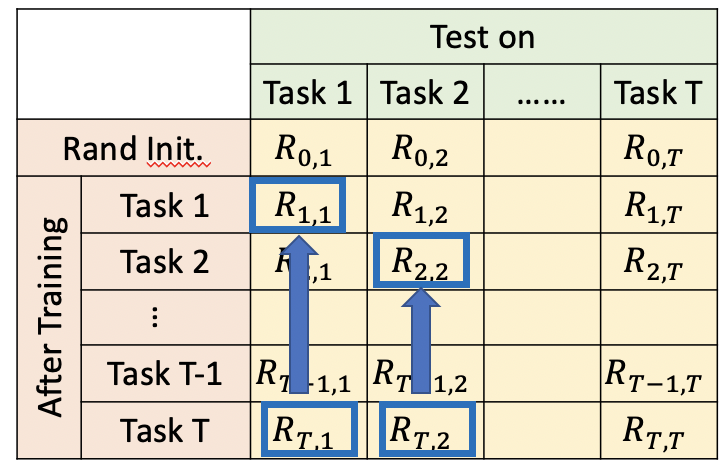
5.3 迁移能力
迁移能力衡量了模型在学习完一个任务后,在未学习的task上的表现。一般和随机初始化的模型进行对比。