0. 简介
终生学习作为近年来比较火的一种深度学习方式,导航终身学习(LLfN)旨在解决标准导航问题的一种新变体,在该问题中,智能体在有限的内存预算下,通过学习提高在线经验或跨环境的导航性能。而最近有一篇文章《A Lifelong Learning Approach to Mobile Robot Navigation》提出了一种新的终身学习导航(LLfN),它完全基于移动机器人自身的经验来改进其导航行为,同时在学习新环境后仍然保留机器人在以前的环境中导航的能力。LLfN算法可以完全在一个真实的内存和计算预算有限的机器人上实现并测试。相对于经典的静态导航方法需要特定环境的原位系统调整,例如,来自人类专家,或者可能重复他们的错误,无论他们在相同的环境中导航了多少次。基于学习的导航具有随着经验而改进的潜力,它高度依赖于对训练资源的访问,例如,足够的内存和快速的计算,并且很容易忘记之前学习的能力,特别是在面对不同的环境时。
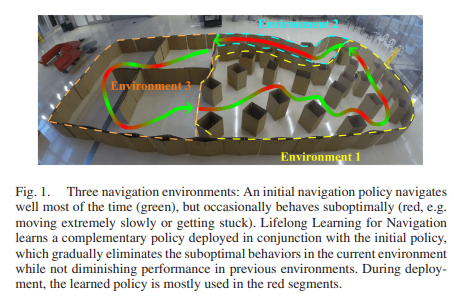
【ICRA2021】3602-移动机器人导航的终身学习方法
1. 文章贡献
本文介绍了解决上述挑战的终身学习导航(LLfN)框架:导航策略不是从头开始学习,而是通过经典导航算法初始化,其导航性能不会随着经验的增加而提高。机器人能够识别自己的次优动作并从中学习。然后,导航性能以一种自我监督的方式提高。在面对不同的导航环境时,导航策略能够学习适应新的环境,同时不会忘记如何在以前的环境中导航。本文最重要的贡献有以下三点:
- 提出了一种可以自我完善的算法,该算法可以有效补充传统的静态规划器,并通过更多的经验动态地提高导航性能,同时它可以与初始规划器一起部署,以最小化学习开销。
- 提出了一个终身学习计划,允许机器人在新的环境中导航,同时不忘记以前的环境;
- 终身学习导航框架的实现完全在物理机器人平台上,该机器人只有有限的内存和计算能力。
2. 详细内容
导航终身学习(LLfN)旨在解决标准导航问题的一种新变体,在该问题中,智能体在有限的内存预算下,通过学习提高在线经验或跨环境的导航性能。首先我们先来看一下终身导航的问题设置和我们在这项工作中使用的符号。
2.1 问题设置和符号
终身导航的高级目标可以概括为学习在 m m m个环境 { ε i } i = 1 m \{\varepsilon_i\}^m _{i=1} { εi}i=1m的序列中导航。在这些环境中,机器人的目标是从一个固定的起点导航到另一个固定的目标点。我们假设一个固定的全局规划器(例如Dijkstra的算法[33], A ∗ A^* A∗[34]或 D ∗ D^* D∗[35])生成连接起点和目标的路径,在导航时,机器人需要产生遵循该全局路径的运动命令,遵守其运动学约束并避开障碍物。每当代理前进到 ε k \varepsilon_k εk时,它不再能够访问 { ε } i = 1 k − 1 \{\varepsilon\}^{k−1}_{i=1} { ε}i=1k−1。在环境 ε k \varepsilon_k εk中,智能体在每一个时间步长 t t t处,在 a t ∈ A π θ ( s t ) a_t∈\mathcal{A} ~ π_θ(s_t) at∈A πθ(st)处计算一个运动命令,其中 s t ∈ S s_t∈S st∈S是智能体的状态, π θ π_θ πθ是由 θ θ θ参数化的策略。在执行 a t a_t at之后,代理前进到 s t + 1 s_{t+1} st+1,进程继续。在学习阶段,智能体的板载内存大小为 n n n,即在任何时刻最多可以存储 n n n对 ( s t , a t ) (s_t, a_t) (st,at)。一旦智能体看到了所有 m m m个环境,它的导航性能将在相同的 m m m个环境中进行评估。