本文出自论文 Channel Pruning for Accelerating Very Deep Neural Networks,主要介绍了一种新的通道剪枝方法,用来加速非常深的卷积神经网络。
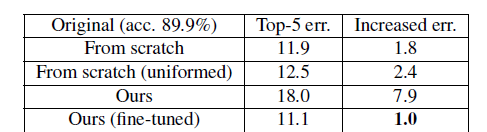
在本文中,我们介绍了一种新的通道剪枝方法,用来加速非常深的卷积神经网络。给定一个训练过的CNN模型,我们提出来一种迭代式的两步骤算法,通过基于通道选择的LASSO回归和最小二乘法重建来有效地修剪每一层。我们进一步将这个算法扩展到多层、多分支的情况。该方法减少了积累误差,提高了与各种体系架构的兼容性。所修剪过的VGG-16获得了5倍的加速效果且只有0.3%的误差增加,该方法还可以加速现代网络例如ResNet、Xception,并且在2倍加速的情况下只有1.4%、1.0%的精度损失。
一、简介
- 结构简化主要涉及到三个方面:张量分解、稀疏连接和通道剪枝。张量分解将一个卷积层分解成几个有效的部分,然而feature map宽度(通道数)不能被减少,使得现代网络中常用的卷积层很难被分解,这种方法也引入了额外的计算开销。稀疏连接使神经元或通道之间的连接失效,尽管它可以实现较高的理论加速比,但稀疏卷积层有一个不规则的shape,不能很好地去实现。作为对比,通道剪枝直接地减少feature map宽度,将一个网络进行缩减。

- 通道剪枝是简单但具有挑战性的,因为移除一个层的通道可能会显著地改变下一层的输入。基于训练的通道剪枝工作集中于在训练期间对权重施加稀疏约束,可以自适应地确定超参数,然而从头开始训练具有一定的代价。推理时间关注于单个权重重要性的分析,所说明的加速比是非常受限的。
- 本文中,我们提出来一个新的针对通道剪枝的推理时间方案,它利用了冗余的内部通道。受到张量分解通过feature maps重建而提高的激励,而不是分析filter权重,我们充分利用了冗余内部feature maps。特别地,给定一个训练过的CNN模型,对每一层的修剪可以通过最小化它的输出feature maps重建误差来获得。我们通过两个可选择步骤来解决这个最小化问题:通道选择和feature map重建。在第一步中,我们选择最有代表性的通道,然后基于LASSO回归剪去冗余的通道。第二步中,我们利用最小二乘法重构了剩余通道的输出。进一步来说,我们逐层逼近这个网络,并考虑了积累误差。
二、相关工作
CNN加速有三种策略:优化实现、量化和结构简化。基于优化实现的方法通过特殊的卷积算法(像FFT)来加速卷积。量化方法减少了浮点数计算复杂度。结构简化则是我们上面提到的几种方法。
三、方案
- 下图展示了一个简单卷积层的通道剪枝算法,我们旨在减少feature map B的通道数,同时保持feature map C的输出。一旦通道被修剪掉,我们可以移除这些通道作为输入的过滤器的相应通道。另外,生成这些通道的滤波器也会被移除。所以通道剪枝涉及两个关键点,第一个是通道选择,因为我们需要选择合适的通道结合来保持尽量多的信息,第二个是重构,我们需要使用所选择的通道重构接下来的feature maps。

- 为了修剪一个通道数为c的feature map,我们考虑从这个feature map采样得到的输入体X( )应用卷积滤波器W( ),这里N是样本数量,n是输出通道数量, 是核大小。为了将输入通道从c修剪到c`,同时最小化重构误差,我们定义我们的问题如下: 。 是从输入体X的第i个通道切去的矩阵 , 是从W的第i个通道切去的过滤器 权重, 是通道选择的系数向量。
- 我们从两方面来解决优化问题,首先我们固定W值,求解
来进行通道选择,然后我们固定
值,求解W来重构误差。
(1) 子问题:在这种情况下,我们固定W值,这个问题可以通过LASSO回归来解决掉,被广泛应用于模型选择。
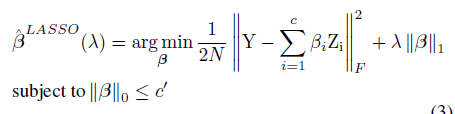
(2)W子问题:在这种情况下,我们固定 值,利用选择好的通道来最小化重构误差。最初,W从训练过的模型中进行初始化, 表示没有惩罚, 。然后我们逐渐增加 ,对于 的改变,我们迭代上面两个优化步骤直到 稳定下来。由于两个步骤的迭代消耗一定的时间,所以步骤一需要进行多次直到满足 ,然后只应用步骤二一次从而获得最终的结果。
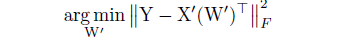
- 整个模型剪枝:对于每一层,我们从当前输入的feature map中获得输入体,然后从未剪枝模型的输出feature map中获得输出体,这可以被定义为: 。其中累积误差可以在序列剪枝期间被计算得到。
- 多分支网络剪枝:对于ResNet来说,第一层大量的输入feature map宽度不能被轻易地剪去,因为它与shortcut共享。最后一层来自shortcut的累积误差很难被恢复,因为它在shortcut中没有参数。为了解决这些问题,我们提出了两种方案:(1)残差分支的最后一层:一个残差分支的输出层由两个输入组成,分别为来自shortcut的feature map
,和来自残差分支的feature map
,我们旨在从block中恢复
。由于shortcut分支参数自由,
不可能被直接复原。为了补偿这个错误,最后一层的优化目标从
变为
,其中
是先前层剪枝后的当前feature map。(2)残差分支的第一层:为了节省计算量,我们可以在第一次卷积之前进行feature map采样。我们在共享的feature maps上采样所选择的通道,为后面的卷积层构造一个新的输入。在引入feature map采样后,卷积仍然是规则的。过滤式剪枝也是针对残差分支第一个卷积层上的另一种选择。因为参数自由的shortcut分支的输入通道不能被修剪,每个过滤器可以自主选择它们各自的输入通道。

四、实验
- VGG-16实验:我们将我们的算法和两个原始的通道选择策略进行比较,first k选择前k个通道,max response根据有着高绝对权重和的相应滤波器来选择通道。实验性能是通过在不进行微调的情况下对某一层进行修剪后增加的误差来衡量的。当加速比增加时误差也会增加,在不同的加速比下我们的方法在不同的卷积层上都优于其他方法。另外从较浅的层到较深的层,通道剪枝逐渐变得困难,我们可以在整个模型加速的较浅的层中积极地修剪。

- 通道剪枝要比张量分解更具有挑战性,因为在一个层上移除通道可能会急剧改变下一个层的输入。然而,通道剪枝保持了原始模型的架构,并没有引入额外的层,在GPU上的绝对加速比要更高。我们逐层有序地应用空间分解、通道分解和我们的通道剪枝方法,并对加速过的模型微调20周期。对不同加速技术的结合方法要比任何一个单一方法更好,这意味着一个模型在每个基数上都是冗余的。
- 在与从零开始训练的模型比较时,我们的方法成功地选择了最有信息价值的通道并构建了高紧缩模型,相同的模型很难从零开始得到的。这意味着如果在较浅的层中有更多的通道,该模型可能更容易训练,即通道剪枝有利于较浅的层。我们发现相同复杂度的正常设置网络并不能达到相同的精度,这说明网络在训练中有着较大的冗余。然而冗余可以在推理时间过程中选择退出,这可能是推理时间加速方法胜于基于训练的方法的优势之处。
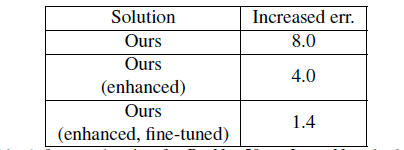
- 我们使用我们的方法来对多分支的变体性能进行评估。实验中我们使用多分支增强方法提高了4.0%,这是因为我们计算了来自shortcut连接的累积误差,它可以传播到它之后的每一层。通过feature map采样,大大减小了每个残差块入口处的输入feature map宽度。
五、结论
综上所述,目前的深度CNNs是准确的且伴随着高推理成本。本文我们提出来一个针对非常深的网络的推理时间通道剪枝方法,被减少的CNNs仍然是推理有效的网络同时保持着高精度,仅需要一些现成的库。在ImageNet,CIFAR-10和PASCAL VOC数据集上,在VGG Net和ResNet网络上都证明了令人信服的加速和准确性。
