import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
from keras.utils import to_categorical
import numpy as np
path="F:\mnist.npz"
f = np.load(path)
train_X, train_y = f['x_train'], f['y_train']
test_X, test_y = f['x_test'], f['y_test']
f.close()
train_X = train_X.reshape(-1, 28, 28, 1)
train_X = train_X.astype('float32')
train_X /= 255
train_y = to_categorical(train_y, 10)
# 创建网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1=nn.Conv2d(1,32,5,stride=1,padding=0)
self.relu1=nn.ReLU()
self.pool1=nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
self.conv2=nn.Conv2d(32,16,3,stride=1,padding=0)
self.relu2=nn.ReLU()
self.pool2=nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
self.fc1 = nn.Linear(400, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x=self.conv1(x)
x=self.relu1(x)
x=self.pool1(x)
x=self.conv2(x)
x=self.relu2(x)
x=self.pool2(x)
x=x.view(-1,400)
x=self.fc1(x)
x=F.relu(x)
x=self.fc2(x)
x=F.relu(x)
x=self.fc3(x)
return x
net = Net()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_loss = []
precision=0
for epoch in range(4):
for i in range(600):
x=train_X[i*100:i*100+100]
y=train_y[i*100:i*100+100]
x = x.reshape(-1,1,28,28)
x = torch.from_numpy(x) #(batch_size,input_feature_shape)
y = torch.from_numpy(y) #(batch_size,label_onehot_shape)
out = net(x)
loss = F.mse_loss(out, y) # 计算两者的误差
optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
optimizer.step() # 将参数更新值施加到 net 的 parameters 上
train_loss.append(loss.item())
if i % 10 == 0:
print(epoch, i, np.mean(train_loss))
train_loss=[]
total_correct = 0
for i in range(10000):
x = train_X[i]
y = train_y[i]
x = torch.from_numpy(x)
y = torch.from_numpy(y)
x=x.view(1,1,28,28)
y=y.view(1,10)
out = net(x)
pred = out.argmax(dim=1) # 返回值最大的索引
label = y.argmax(dim=1)
correct = pred.eq(label).sum().float().item() # 这个batch中正确的数量
total_correct += correct
acc = total_correct / 10000.0
print('test acc:', acc)
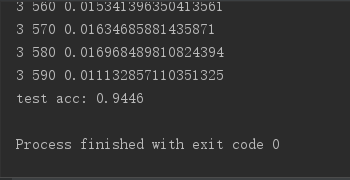
训练4轮,结果如下