center loss
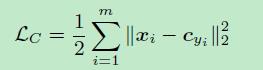
import torch as t
import torch.nn as nn
import torch.nn.functional as F
class CenterLoss(nn.Module):
def __init__(self,cls_num,featur_num):
super().__init__()
self.cls_num = cls_num
self.featur_num=featur_num
self.center = nn.Parameter(t.rand(cls_num,featur_num))
def forward(self, xs,ys): #xs=feature,ys=target
# xs= F.normalize(xs)
self.center_exp = self.center.index_select(dim=0,index=ys.long())
count = t.histc(ys,bins=self.cls_num,min=0,max=self.cls_num-1)
self.count_dis = count.index_select(dim=0,index=ys.long())+1
loss = t.sum(t.sum((xs-self.center_exp)**2,dim=1)/2.0/self.count_dis.float())
return lossNet
import torch as t
import torchvision as tv
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as data
import matplotlib.pyplot as plt
from tensorboardX import SummaryWriter
import torch.optim.lr_scheduler as lr_scheduler
import os
Batch_Size = 128
train_data = tv.datasets.MNIST(
root="MNIST_data",
train=True,
download=False,
transform=tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.1307,), (0.3081,))]))
test_data = tv.datasets.MNIST(
root="MNIST_data",
train=False,
download=False,
transform=tv.transforms.Compose([tv.transforms.ToTensor(),
tv.transforms.Normalize((0.1307,), (0.3081,))]))
train_loader = data.DataLoader(train_data, batch_size=Batch_Size, shuffle=True, drop_last=True,num_workers=8)
test_loader = data.DataLoader(test_data, Batch_Size, True, drop_last=True,num_workers=8)
class TrainNet(nn.Module):
def __init__(self):
super().__init__()
self.hidden_layer = nn.Sequential(
nn.Conv2d(1, 32, 3, 2, 1),
nn.PReLU(),
# nn.BatchNorm2d(32),
nn.Conv2d(32, 128, 3, 2, 1),
nn.PReLU(),
# nn.BatchNorm2d(128),
nn.Conv2d(128, 128, 3, 1, 1),
nn.PReLU(),
# nn.BatchNorm2d(128),
nn.Conv2d(128, 16,3, 2, 1),
nn.PReLU())
self.linear_layer = nn.Linear(16*4*4,2)
self.output_layer = nn.Linear(2,10)
def forward(self, xs):
feat = self.hidden_layer(xs)
# print(feature.shape)
fc = feat.reshape(-1,16*4*4)
# print(fc.data.size())
feature = self.linear_layer(fc)
output = self.output_layer(feature)
return feature, F.log_softmax(output,dim=1)
def decet(feature,targets,epoch,save_path):
color = ["red", "black", "yellow", "green", "pink", "gray", "lightgreen", "orange", "blue", "teal"]
cls = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
plt.ion()
plt.clf()
for j in cls:
mask = [targets == j]
feature_ = feature[mask].numpy()
x = feature_[:, 1]
y = feature_[:, 0]
label = cls
plt.plot(x, y, ".", color=color[j])
plt.legend(label, loc="upper right") #如果写在plot上面,则标签内容不能显示完整
plt.title("epoch={}".format(str(epoch)))
plt.savefig('{}/{}.jpg'.format(save_path,epoch+1))
plt.draw()
plt.pause(0.001)
Train
from Net import *
from centerloss import CenterLoss
save_path = r"{}\train{}.pt"
if __name__ == '__main__':
net = TrainNet()
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
centerloss = CenterLoss(10, 2).to(device)
# crossloss = nn.CrossEntropyLoss().to(device)
nllloss = nn.NLLLoss().to(device)
# optmizer = t.optim.Adam(net.parameters())
optmizer = t.optim.SGD(net.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
scheduler = lr_scheduler.StepLR(optmizer, 20, gamma=0.8)
optmizercenter = t.optim.SGD(centerloss.parameters(), lr=0.5)
# if os.path.exists(save_path):
# net.load_state_dict(t.load(save_path))
net = net.to(device)
# write = SummaryWriter("log")
count = 0
for epoch in range(1000):
scheduler.step()
feat = []
target = []
for i, (x, y) in enumerate(train_loader):
x,y = x.to(device),y.to(device)
xs,ys = net(x)
value = t.argmax(ys, dim=1)
center_loss = centerloss(xs,y)
nll_loss = nllloss(ys,y)
# cross_loss = crossloss(ys,y)
# loss = center_loss+cross_loss
loss = nll_loss+center_loss
optmizer.zero_grad()
optmizercenter.zero_grad()
loss.backward()
optmizer.step()
optmizercenter.step()
count+=1
feat.append(xs)
target.append(y)
if i % 100 == 0:
print(epoch, i, loss.item())
print(value[0].item(), "========>", y[0].item())
# if i %500==0:
# t.save(net.state_dict(),save_path.format(r"D:\PycharmProjects\center_loss\data",str(count)))
features = t.cat(feat,0)
targets = t.cat(target,0)
decet(features.data.cpu(),targets.data.cpu(), epoch,)
# write.add_histogram("loss",loss.item(),count)
# write.close()
Effect Show
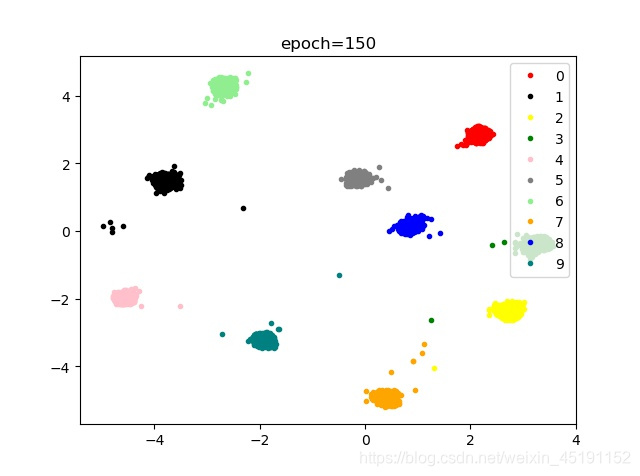

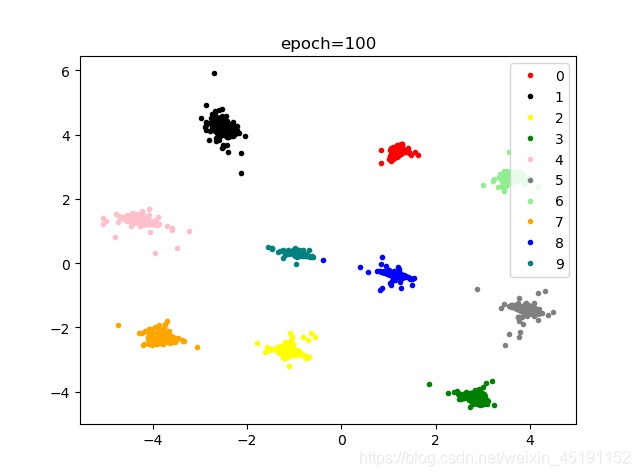

优化过程总结:
- 选择NLLloss效果比CrossEntropyLoss效果好,nllloss=log()+nllloss()
- center loss 和网络分开优化,效果会更好,速度也更快(center loss learning rate=0.5)
- 使用SGD优化时,如果没有添加动量,则会在三十轮左右开始出现无法(难以)收敛的情况,如果仅仅增加动量,而没有人为更新学习率,则收敛速度超慢;
- 使用Adam优化时,速度比SGD更快,但效果欠佳;
- 最终搭配:NLLLOSS+SGD optmizer(momentum+lr updata)
- 关于网络,卷积比全连接效果略好,网络设计大一点效果会更好。
- 在画点过程中,如果没有提前加载数据,则会在画点的时候花费大量时间;如果没有清除数据,则会越画越慢;点太多有可能导致效果不明显(代码中feat=[],target=[]放错位置)