写这篇文章,我主要是想要介绍一种流行的深度学习框架---Pytorch,并且完成一个简单的CNN网络例子来加深对它的认识,我们还使用到了Fashion Mnist数据集,完成这个DL领域的“Hello World”。
相比于TF,Pytorch有很多优点。这些可以自行Google来了解。总之,Pytorch更加符合python的特性,也更加好理解。
数据集
在这个项目中,我将使用Fashion Mnist数据集,可以在kaggle下载csv文件。
网络模型
为了训练图片,我们使用CNN网络来提取图片的各项特征。例如:
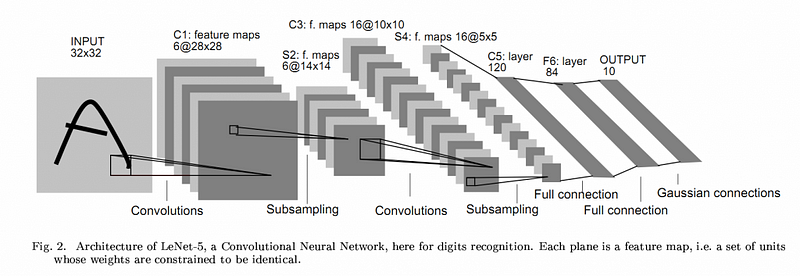
在这个网络中,一共有五个卷积层。我们将输入值通过filters来更新数值,这些kernel values通过前向传播来
计算损失函数,然后通过反向传播来再次更新损失函数。在这个项目中,我们使用的网络结构如下图所示:
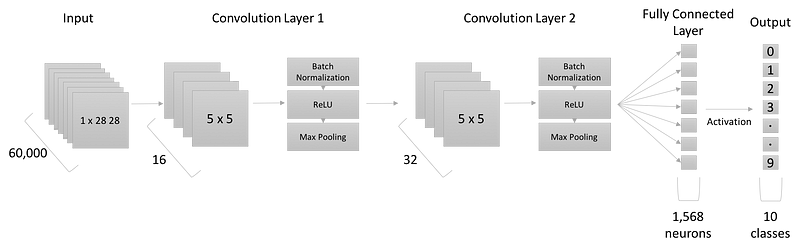
我们使用了两个卷积层,kenel的大小为5*5,后面是一个全连接层,最后输出一个激活值给最后的输出层。下面,我们来逐个分析代码。
Imports
import torch
import torch.nn as nn
import torchvision.datasets as dsets
from skimage import transform
import torchvision.transforms as transforms
from torch.autograd import Variable
import pandas as pd;
import numpy as np;
from torch.utils.data import Dataset, DataLoader
from vis_utils import * #可视化工具,可以省略
import random;
import math;声明必要的全局变量:
num_epochs = 5;
batch_size = 100;
learning_rate = 0.001;加载数据
在pytorch中,为了加载数据,我们需要编写一个类来继承Dataset类型,然后定义数据读取函数和数据获取函数,来看看我们是怎么完成对Fashion MNIST的加载:
class FashionMNISTDataset(Dataset):
'''Fashion MNIST Dataset'''
def __init__(self, csv_file, transform=None):
"""
Args:
csv_file (string): Path to the csv file
transform (callable): Optional transform to apply to sample
"""
'''iloc也就是分割矩阵,把data想成一个表格,X代表的是每个样本,Y代表的是样本对应的标签,
那么取样本的话,取全部的行和第一列到最后一列。取标签的话,取全部的行和第0列。'''
data = pd.read_csv(csv_file);
self.X = np.array(data.iloc[:, 1:]).reshape(-1, 1, 28, 28).astype(float);
self.Y = np.array(data.iloc[:, 0]);
del data; #结束data对数据的引用
self.transform = transform;
def __len__(self):
return len(self.X);
def __getitem__(self, idx):
item = self.X[idx];
label = self.Y[idx];
if self.transform:
item = self.transform(item);
return (item, label);在__init__中,我们从csv文件中加载了数据, 我使用了pandas将数据读取为dataframe,然后将其转成numpy数组来进行索引,后面紧跟着transform函数。(还未具体理解transform函数)
__getitem__会返回单张图片,它包含一个index,返回值为样本及其标签。
我们定义如下的数据读取方式:
train_dataset = FashionMNISTDataset(csv_file='fashionmnist/fashion-mnist_train.csv');
test_dataset = FashionMNISTDataset(csv_file='fashionmnist/fashion-mnist_test.csv')通过以上代码,可以自己创建文件夹目录。
我们接着使用dataloader模块来使用这些数据:
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True);
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True);构建网络
神经网络继承了nn.Module,我们需要完成两个函数,__init__ 和forward:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7*7*32, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out以上代码看起来很简单。在函数里边,我们使用nn提供的模块来定义各个层,在两个卷积层和激活值后我们使用了全连接层来输出10个类别。view函数用来改变输出值矩阵的形状来匹配最后一层的维度。
训练模型
下面我们来定义损失函数啦进行优化,然后训练模型。
#instance of the Conv Net
cnn = CNN();
#loss function and optimizer
criterion = nn.CrossEntropyLoss();
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate);训练模型:
losses = [];
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images.float())
labels = Variable(labels)
# Forward + Backward + Optimize
optimizer.zero_grad()
outputs = cnn(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
losses.append(loss.data[0]);
if (i+1) % 100 == 0:
print ('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f'
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data[0]))对于每一批训练集我们都做了如下操作:
a.将优化器中的梯度全部归零,因为backward()函数会累积梯度值,我们不能将每个batch(mini batch)的梯度值都混合起来。
b.将数据输入到卷积网络,即输入到forward()函数,然后获得输出。
c.通过输出值和正确的标签来计算损失函数。
d.反向传播梯度值。
e.基于反向传播的数值来更新参数。
代码运行情况如下:
Epoch : 1/20, Iter : 100/600, Loss: 0.4417
Epoch : 1/20, Iter : 200/600, Loss: 0.7577
Epoch : 1/20, Iter : 300/600, Loss: 0.3303
Epoch : 1/20, Iter : 400/600, Loss: 0.2696
Epoch : 1/20, Iter : 500/600, Loss: 0.3722
Epoch : 1/20, Iter : 600/600, Loss: 0.4107
Epoch : 2/20, Iter : 100/600, Loss: 0.2769
Epoch : 2/20, Iter : 200/600, Loss: 0.2467上边的结果没有完全跑完。
评估模型
代码如下:
cnn.eval()
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.float())
outputs = cnn(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Test Accuracy of the model on the 10000 test images: %.4f %%' % (100 * correct / total))步骤解释如下:
1.将网络的模式改为eval。
2.将图片输入到网络中得到输出。
3.通过取出one-hot输出的最大值来得到输出的 标签。
4.统计正确的预测值。
可视化损失函数的变化过程
代码如下:
losses_in_epochs = losses[0::600]
plt.xkcd();
plt.xlabel('Epoch #');
plt.ylabel('Loss');
plt.plot(losses_in_epochs);
plt.show();