框架:Pytorch
数据集:Fashion MNIST(手写数字识别的进阶)
网络:卷积神经网络(CNN)又名滑积神经网络
目的:熟悉Pytorch框架, 搭建简易滑积神经网络
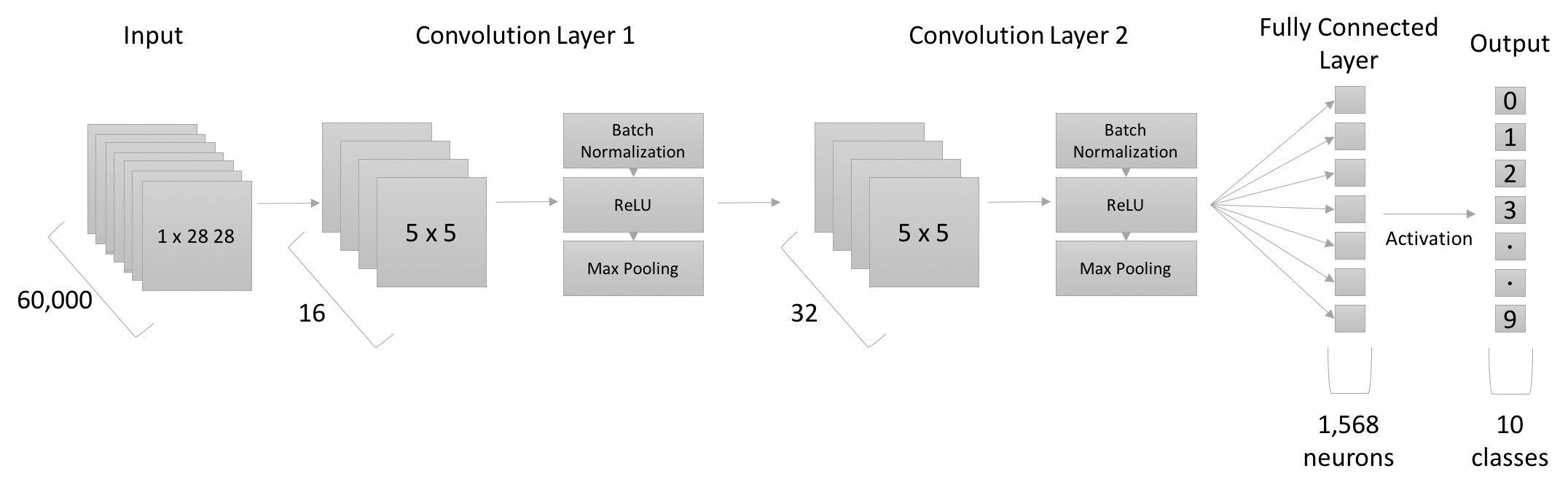
结构:
代码:
引用
import torch
import torch.nn as nn
import torchvision.datasets as dsets
from skimage import transform
import torchvision.transforms as transforms
from torch.autograd import Variable
import pandas as pd;
import numpy as np;
from torch.utils.data import Dataset, DataLoader
from vis_utils import *
import random;
import math;超参数
num_epochs = 5;
batch_size = 100;
learning_rate = 0.001;这块黑色的我不知道怎么去掉~哎呀呀,小黑屏幕,哎呀呀,你也去不掉呀,你是咋出来的呢,我也不知道呀!小白菜呀,地里黄呀,小黑屏呀,去不掉呀。嘿嘿!嘿嘿!嘿嘿嘿!
定义数据集
Pytorch中自带数据集Dataset不包括Fashion MNIST,因此需要自定义Fashion MNIST数据集。自定义数据集需继承父类Dataset,并重载父类成员中的两个私有成员函数,
其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据索引的函数。
def getitem(self, index):
def len(self):class FashionMNISTDataset(Dataset):
'''Fashion MNIST Dataset'''
def __init__(self, csv_file, transform=None): #初始化函数,主要用于数据的加载,pandas读取数据为dataframe,转成numpy数组来进行索引 。
"""
Args:
csv_file (string): csv file地址
transform (callable): Optional transform to apply to sample
"""
'''iloc:分割矩阵,data:表格数据。X:样本,Y:标签且在0列。
取样本:行全取、列从第1到结束。取标签:行全取,列取0。'''
data = pd.read_csv(csv_file); #从csv文件加载数据,使用Pandas读入
self.X = np.array(data.iloc[:, 1:]).reshape(-1, 1, 28, 28).astype(float);
self.Y = np.array(data.iloc[:, 0]); #数据转换为numpy数组从而索引
del data; # 结束data对数据的引用,节省空间
self.transform = transform; #transform默认值为None
def __len__(self): #样本长度,即数据集总数,dataloader需使用。
return len(self.X);
def __getitem__(self, idx): #返回单张图片。输入索引,返回该样本及其标签。如果定义transform,转换样本并返回。
item = self.X[idx];
label = self.Y[idx];
if self.transform:
item = self.transform(item);
return (item, label); #样本和标签划分样本集和测试集
train_dataset = FashionMNISTDataset(csv_file='fashionmnist/fashion-mnist_train.csv');
test_dataset = FashionMNISTDataset(csv_file='fashionmnist/fashion-mnist_test.csv')加载数据
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True);
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True);构建滑积网络
网络继承nn.Module,编写__init__及forward函数。使用nn模块定义网络层:(卷积-归一化-激活-池化)-(卷积-归一化-激活-池化)-全连接层(10类别输出)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=5, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(2))
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=5, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2))
self.fc = nn.Linear(7*7*32, 10)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out网络实例化
cnn = CNN();定义损失函数
criterion = nn.CrossEntropyLoss();选取优化器
多分类因为使用Softmax回归,将神经网络前向传播得到的结果变成概率分布,所以使用交叉熵损失。 Pytorch将 nn.LogSoftmax() 和 nn.NLLLoss()整合成NN.CrossEntropyLoss()即为交叉熵。
optimizer = torch.optim.Adam(cnn.parameters(), lr=learning_rate);模型训练
注意:loss.data[0]是pytorch0.3.1版本代码,0.5以上版本会报错,应替换成loss.data.item()。下面代码已替换完成。
下图中一个重中之重的概念是Variable。
losses = []; #记录损失函数
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images.float())
labels = Variable(labels)
# Forward + Backward + Optimize
#清零
optimizer.zero_grad()
#前向
outputs = cnn(images)
#损失函数
loss = criterion(outputs, labels)
#后向传播
loss.backward()
#优化器迭代
optimizer.step()
#损失函数矩阵
#losses.append(loss.data.item());
losses.append(loss.data.item());
#打印
if (i+1) % 100 == 0:
print ('Epoch : %d/%d, Iter : %d/%d, Loss: %.4f'
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data.item()))