1 什么是模型攻防
1.1 攻防定义
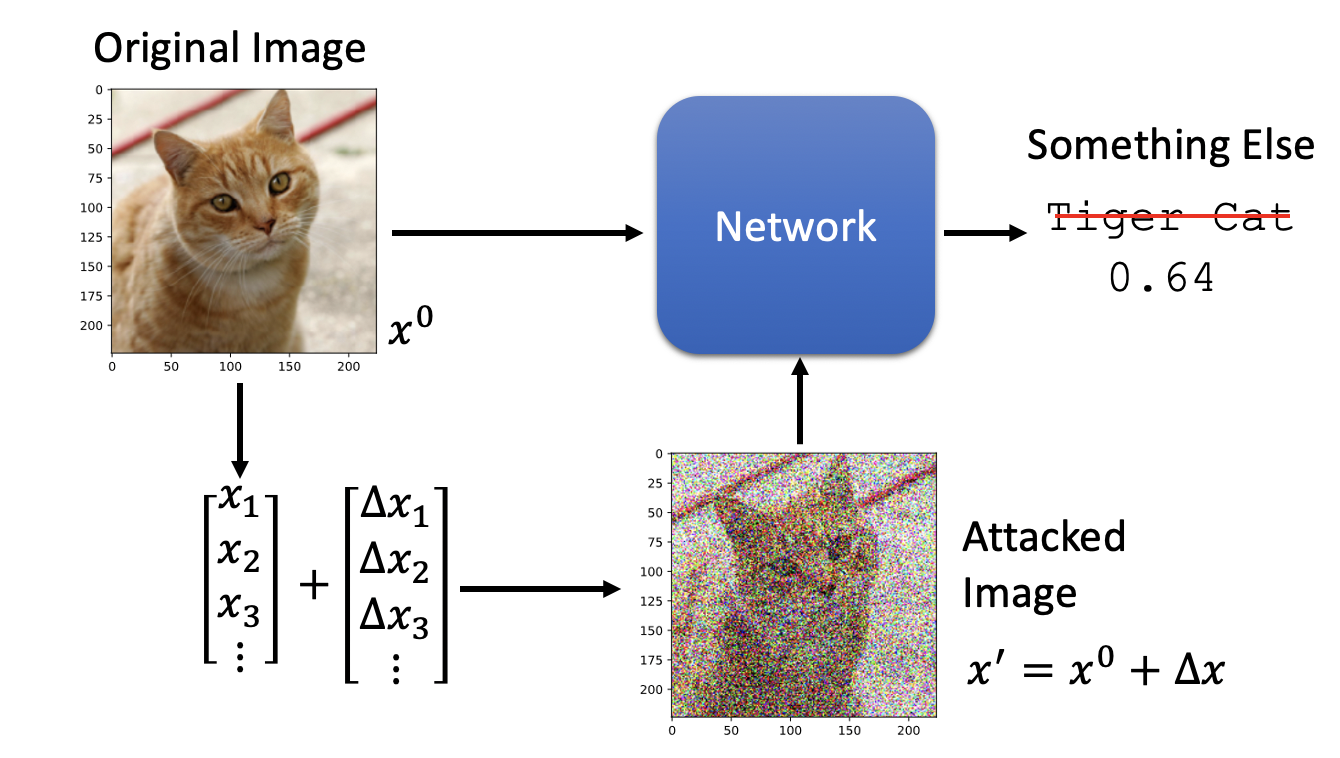
我们在平常的深度学习模型开发中,一般关注的重点在模型指标上,比如ACC、F1、Bleu等。但其实还有另一方面需要注意,那就是模型攻防,特别是在人脸识别等安全领域。什么是模型攻击(model attack)呢?以图片分类为例,如下图。原始图片经过分类模型,可以正确识别是tiger cat。我们在图片上加入某些一定分布的噪声后,模型可能就会把它错误识别为其他类别,比如keyboard。
1.2 攻击条件
模型攻击必须满足两个条件
- 在原始图片上加入一定噪音,通过模型后,predict和真实label尽量远,和目标假label尽量近。loss如下
-
- 加入的噪音必须在一定范围内,使得人类分辨不出来,这个称为限制constrain。数学表达如下
![]()
1.3 攻击限制constrain
对于噪音距离定义,有两种方式
1. L2距离,也就是假样本和真样本的均方差。
![]()
2. 最大距离,假样本和真样本,差别最大的点
![]()
实际应用中,一般取最大距离。相比L2平均距离和最大距离,最大距离差别过大,容易被人类分辨出来。
1.4 模型攻击场景
除了视觉领域外,NLP、语音识别均可以做模型攻击。实际场景中,比如人脸识别,有人做了一副特殊的眼镜,带上它后,就会识别为其他人。如下图

模型攻击会对业务的安全性造成很严重的影响,因此模型防御(model defense)十分关键。模型攻击分为白盒攻击、黑盒攻击。了解如何做模型攻击,有利于掌握模型防御。
2 模型攻击 model attack
模型攻击分为白盒攻击、黑盒攻击。
2.1 白盒攻击
白盒攻击指的是,在知道模型结构和参数的情况下,设计方法进行攻击。常用的方法仍然是梯度下降。此时我们的神经网络参数是固定的,我们要调整的是样本输入x,通过梯度下降来找到最合适的样本x。同时假样本必须满足最大距离限制。模型攻击的loss可以定义为
![]()
则目标函数为
![]()
常用的方法如下
- FGSM (https://arxiv.org/abs/1412.6572)
- Basic iterative method (https://arxiv.org/abs/1607.02533)
- L-BFGS (https://arxiv.org/abs/1312.6199)
- Deepfool (https://arxiv.org/abs/1511.04599)
- JSMA (https://arxiv.org/abs/1511.07528)
- C&W (https://arxiv.org/abs/1608.04644)
- Elastic net attack (https://arxiv.org/abs/1709.04114)
- Spatially Transformed (https://arxiv.org/abs/1801.02612)
- One Pixel Attack (https://arxiv.org/abs/1710.08864)
以Fast Gradient Sign Method (FGSM)为例,它通过梯度下降的方法,调整样本x,来优化目标函数,使得上面定义的loss最小。其假样本的构造方法为,在真实样本每个点x上,要么加上ε,要么减去ε。如下
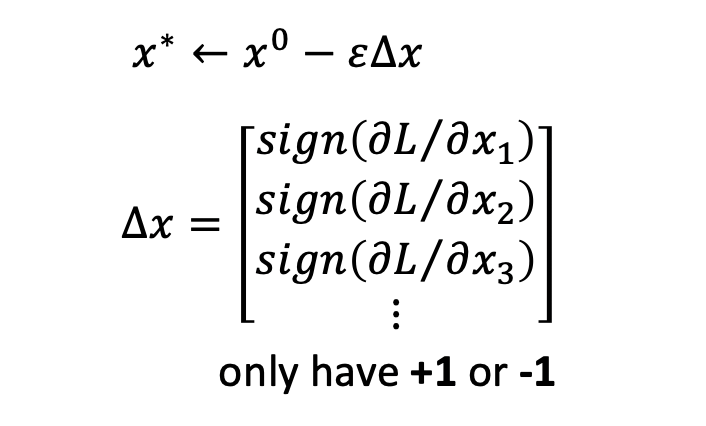
2.2 黑盒攻击
白盒攻击方法我们懂了,那我们是不是不公布模型参数,就可以防御了呢。显然不是,我们还可以进行黑盒攻击。怎么进行黑盒攻击呢。我们可以利用数据,自己训练一个模型,称为proxy model。然后对这个proxy model进行白盒攻击。利用得到的样本来攻击真实模型,一般效果也不错。
这儿关键问题有两个
- 怎么得到训练proxy model的数据。一方面可以利用与此模型任务类似的数据,比如图像分类问题,可以使用ImageNet数据。另一方面,可以利用要攻击的模型,来构造数据,predict标签。
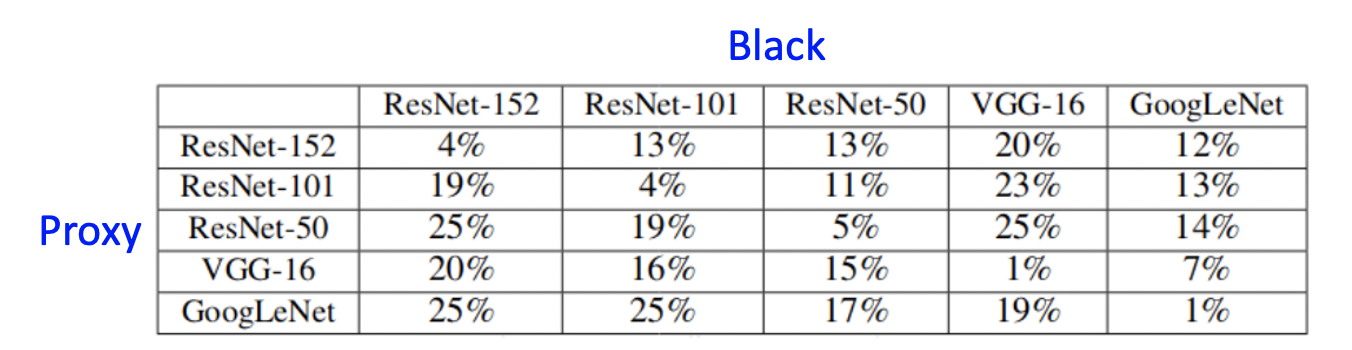
- 怎么知道proxy model的结构。一般来说,同一类任务,即使proxy model和真实model结构不同,效果也OK的。当然proxy model和真实model结构相同,效果会更好。下面是不同分类模型,proxy model构造的假样本,在真实model上的正确率。有图可见,两者模型越接近,模型攻击效果越好。
3 模型防御
模型防御分为被动防御和主动防御
3.1 被动防御
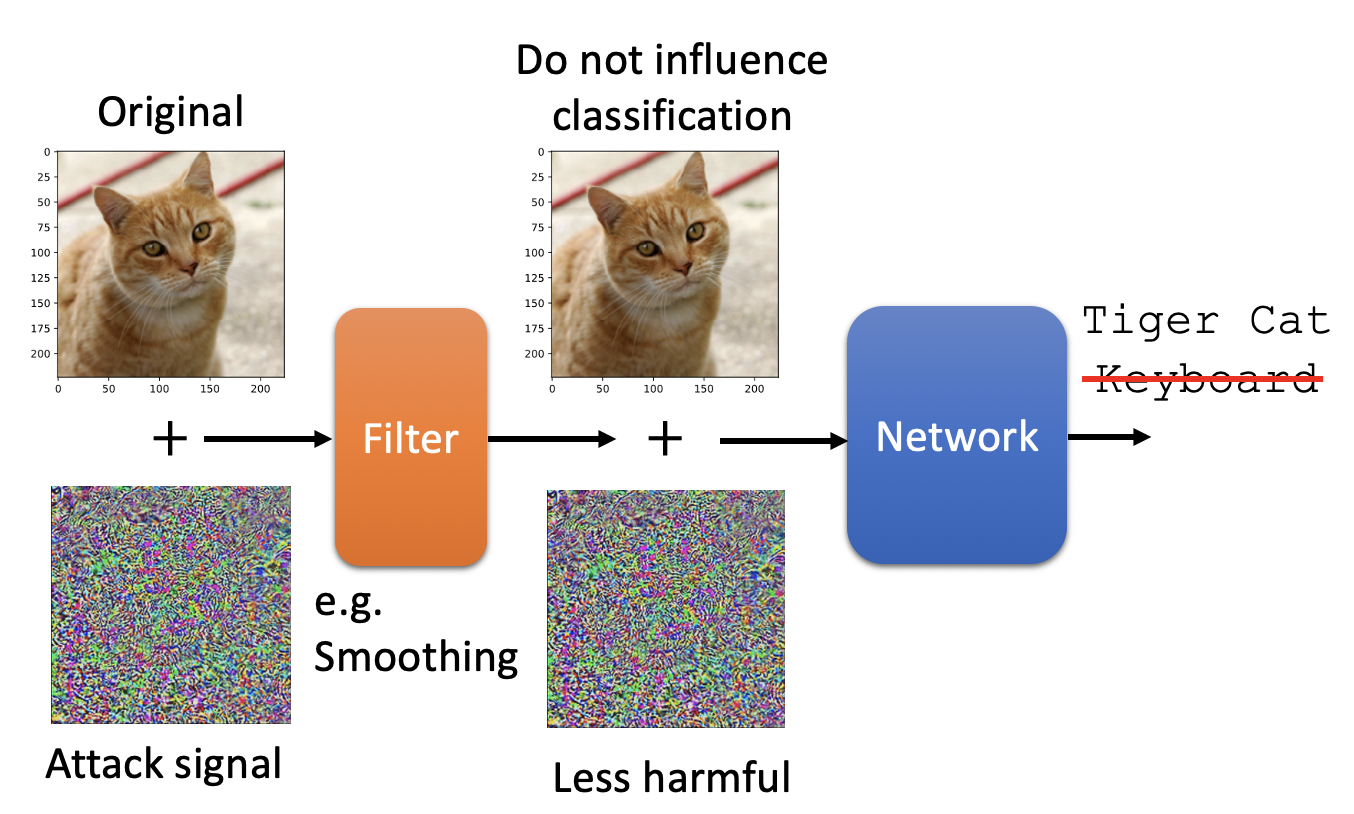
被动防御通过不修改原始模型,来进行防御。主要方法有模型前加入filter,输入样本进行padding、伸缩变化等。
在真实模型前加一个filter,filter可以是一些平滑化处理等。通过这个filter,输入样本会进行一些变化,从而使得攻击样本在模型上失效。
对输入样本,进行适当的padding,伸缩变化等,也可以在不影响真实模型predict的情况下,使得攻击样本失效。
3.2 主动防御
主动防御思想为,先主动进行模型攻击,找到可以攻击的假样本。然后把他们加入到训练数据中,重新训练模型。从而使得模型在这些假样本上,也能正确predict。这个方法有点像data augment。