一、基本原理
Spark Streaming是一种实时流式数据处理机制,用于实时处理实时产生的数据流,具有高吞吐量、容错等特点。Spark Streaming构架如下图:

数据源可以是本地数据、HDFS、TCP socket、Kafka和Flume等等,Spark Streaming从数据源接收数据流,根据时间片将数据流分割成多个批,分批处理,并将处理结果输出到文件系统、数据库或屏幕。
关于Spark Streaming更详细的概念,例如DStream,窗口等概念,此处不详述,后面涉及的时候用实例解释。
二、两种数据源示例
1. TCP socket作为实时数据流
读取数据流以及实时处理代码如下:命名为NetworkWordCount.py
# -*- coding: utf-8 -*-
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建 sc对象, local[2]表示“本地2个核”, NetworkWordCount为应用名称
sc = SparkContext("local[2]", "NetworkWordCount")
# 设置日志级别
sc.setLogLevel("WARN")
# 创建Spark Streaming Context对象, 此处的5表示5秒钟为一个单位接收数据流
ssc = StreamingContext(sc, 5)
# 从一个端口为9999的服务器接收TCP socket数据流
lines = ssc.socketTextStream("localhost", 9999)
# 下面是实时处理的过程,单词计数
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.map(lambda x: (x[0].encode('utf-8'), x[1])).pprint()
# 启动应用
ssc.start()
# 等待应用结束
ssc.awaitTermination()接下来,启动NetCat工具,创建一个端口号为9999的服务器,代码如下图所示:

然后,在另一个终端的命令行,提交上面写的NetworkWordCount.py代码,如下图:

然后,在NetCat工具启动的终端,输入一些字符,作为实时流,如下图:
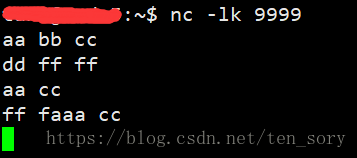
观察代码提交的终端,结果如下:

可以看到,进行了实时数据处理。
2. 本地文件系统作为实时数据流
上面这个例子中,实时数据流是TCP socket数据流,下面测试一下数据源为本地文件系统的情形。做法是:通过一个shell脚本,产生虚拟的日志文件。SparkStreaming实时处理这些日志文件。
实时处理数据流的FileWordCount.py文件代码如下
# -*- coding: utf-8 -*-
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
sc = SparkContext("local[2]", "NetworkWordCount")
sc.setLogLevel("WARN")
# 设置时间为10秒
ssc = StreamingContext(sc, 10)
# 数据源
lines = ssc.textFileStream("file:///InputFile/")
# 依然是WordCount实例
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
windowWordCounts = pairs.reduceByKey(lambda x, y: x + y)
windowWordCounts.map(lambda x: (x[0].encode('utf-8'), x[1])).pprint()
ssc.start()
ssc.awaitTermination()
在一个终端(终端1)提交代码,命令如下图:
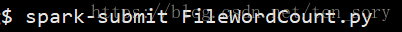
产生虚拟日志文件的shell脚本(create_fake_log.sh)代码如下:
#!/bin/bash
cd ~/InputFile
rm * -f
i=0
while(( 1 > 0 ))
do
touch input$i.log
time=$(date "+%Y-%m-%d %H:%M:%S")
echo ${time} > input$i.log;
echo "write into input$i.log"
stime=`expr $RANDOM % 10`
stime=`expr $stime % 3`
sleep $stime
i=`expr $i + 1`
done
注意,shell脚本需要赋予权限,才可以执行。chmod 777 create_fake_log.sh
这个脚本,进入InputFile目录,然后通过死循环,实时产生input*.log文件,然后写入当前的日期和时间,然后随机休眠几秒钟。下面,执行这个脚本,模拟产生实时数据流,如下:
在另一个终端(终端2),执行这个脚本,如下图:

然后观察终端1的结果,如下图:
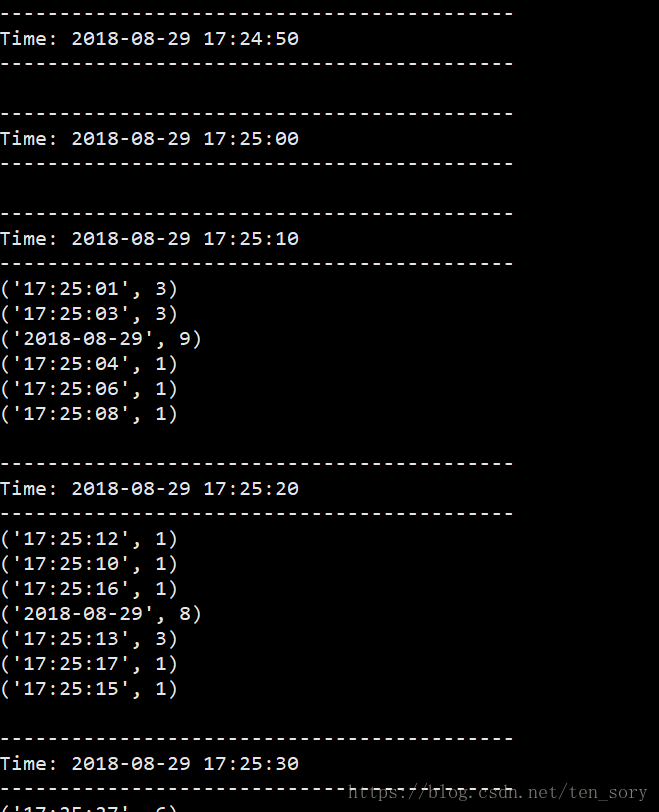
可以继续观察,日志文件是不断产生的(由于脚本的死循环),SparkStreaming对这个数据流的处理也是实时的。