Spark Streaming之所以成为现在主流的流处理开发计算框架,不仅仅是因为它具有流处理和批处理的能力及支持离线和实时计算双重特点,更重要的是Spark具有良好的生态,它不仅可以整合Hadoop生态的Hive,使用Hive on Spark进行离线分析,整合Yarn模式,使用Spark on Yarn进行资源调度,更有自身的Spark SQL及GraphX和machine learning进行更高层次的研究分析。
今天给大家分享下Spark Streaming整合SparkSQL处理流式计算
代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SparkStreamingAndSparkSQL {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("SocketWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream("node1",6666)
val words = lines.flatMap(_.split(" "))
words.foreachRDD(rdd=>{
val spark = SparkSessionSingleton.getInstance(sparkConf)
import spark.implicits._
val RDDToDF = rdd.map(t=>Record(t)).toDF
RDDToDF.createOrReplaceTempView("wordtest")
val wordcountDF = spark.sql("select word,count(1) as total from wordtest group by word")
wordcountDF.show()
})
ssc.start()
ssc.awaitTermination()
}
}
case class Record(word:String)
object SparkSessionSingleton {
private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}
在启动程序之前,先开启socket输入端口
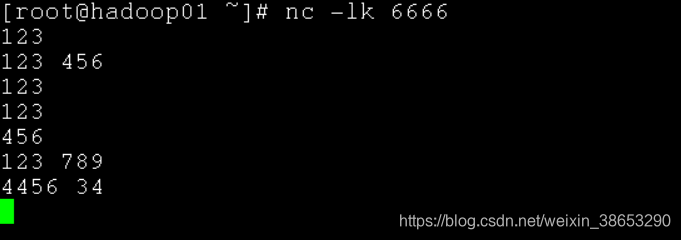
下面是打印在控制台的计数输出

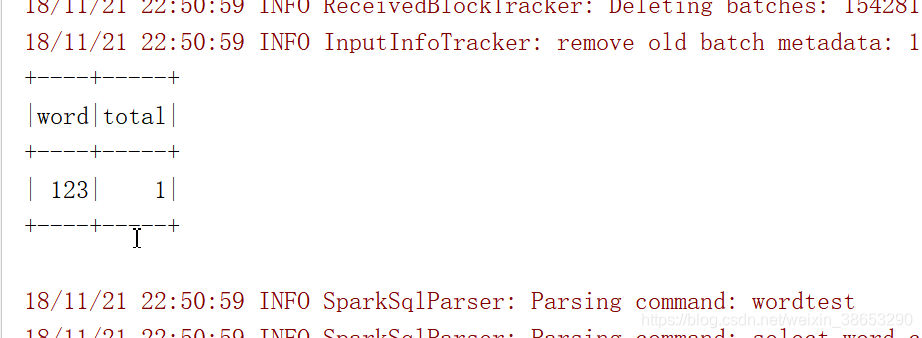
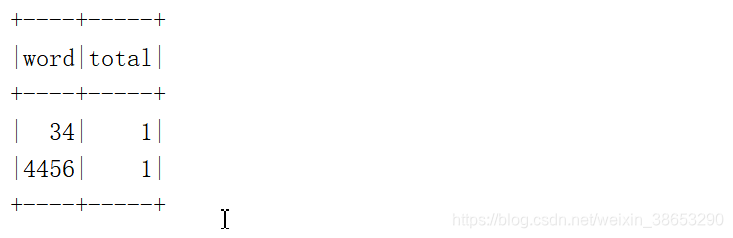
通过以上的输出可以看到,这个程序是分批次计数的,而不是将所有的单词计数,那么我们怎样实现所有批次单词的计数呢? 今天先分享到这里,回头再补充