机器学习——基础算法(八)
一、聚类的定义
聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大
而类别间的数据相似度较小。
无监督
二、相似度/距离计算方法总结

三、聚类的基本思想
口给定一个有N个对象的数据集,构造数据的k个簇,kSn。 满足下列条件:
■每一个簇 至少包含一个对象
■每一个对象属于 且仅属于一个簇
■ 将满足上述条件的k个簇称作一个合理划分
口基本思想:对于给定的类别数目k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之
后的划分方案都较前一次好。
四、k-Means算法(一种广泛使用的聚类算法)

k-Means过程
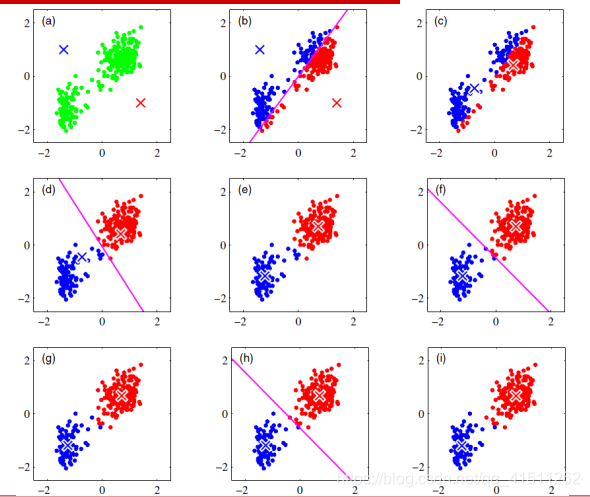
五、k-Means聚类方法总结
口优点:
■是解决聚类问题的一种经典算法,简单、快速
■对处理大数据集,该算法保持可伸缩性和高效率
■当簇近似为高斯分布时,它的效果较好
口缺点
■在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
■必须事先给出k(要生成的簇的数目),而且对初值敏感,
对于不同的初始值,可能会导致不同结果。
■不适合于发现非凸形状的簇或者大小差别很大的簇
■对躁声和孤立点数据敏感
口可作为其他聚类方法的基础算法,如谱聚类