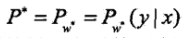1 逻辑斯蒂回归模型
(1)逻辑斯蒂分布
对于连续的随机变量X,X服从逻辑斯蒂分布是指:X具有下列分布函数和密度函数:
分布函数:


密度函数:


式中:u为位置參数,r >0为形状參数。
f(x)推导过程:

(2)二项逻辑斯蒂回归模型
二项逻辑斯蒂回归模型是一种分类模型,使用P(Y|X)表示,形式为參数化的逻辑斯蒂分布。
随机变量X取值为实数,随机变量Y取值为1或0。

于是二项逻辑斯蒂回归模型就是对输入实例X,求P(Y=1|X) 和P(Y=0|X) ,然后比较其大小,将实例分为概率较大的那一类。
事件的几率(odds): 事件的几率 = 事件发生的概率/事件不发生的概率
odds的对数几率即其logit函数就是: logit(p) = log(p / (1 - p))
于是对于逻辑斯蒂回归而言:

上式说明了:在逻辑斯蒂回归模型中,输出Y=1的对数几率是输入X的线性函数。
换句话说即:输出Y=1(输出指定类别)的对数几率是由输入X的线性函数表示的模型。
即:逻辑斯蒂回归模型就是输出Y=1(输出指定类别)的对数几率是由输入X的线性函数表示的模型。


w·x的值越接近 +∞,P(Y=1|X) 越接近1 w·x的值越接近 -∞,P(Y=1|X) 越接近0
这样的模型就是逻辑斯蒂回归模型
模型参数估计:

(3)多项逻辑斯蒂回归

2 最大熵模型
(1)最大熵原理
最大熵原理认为:在所有可能的概率模型中,熵最大的模型为最好的概率模型
对于某一个随机变量X,它的概率分布为P(X),它的熵定义为 :

熵的取值范围:

式中,|X|是X的取值个数,当且仅当X的分布是均匀分布时右边的等号成立,这就是说当X服从均匀分布时,熵最大。


(2)最大熵模型的定义
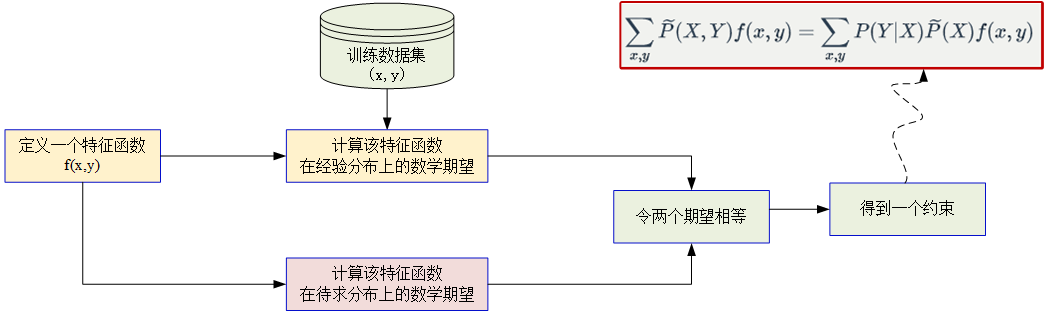
我们的目的:利用最大熵原理,选择一个最好的分类模型;从而,对于任何给定的样本x∈X,都可以以概率P(y|x)输出y∈Y。
例如两分类问题:得到的分类器P(Y|X),可以使得对于任何给定的样本x∈X,都可以计算得到P(y=1|x)和P(y=0|x)
具体构造思路为:


6.13的公式推导: 条件熵H(X|Y) = H(X,Y) - H(Y)

3 最大熵模型的学习
最大熵模型的学习过程就是求解最大熵模型的过程,最大熵模型的学习等价于约束最优化问题:
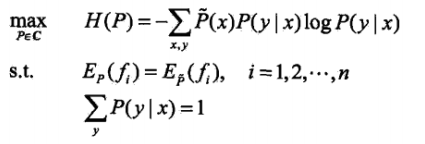
这个优化问题可以转换为最小化问题:
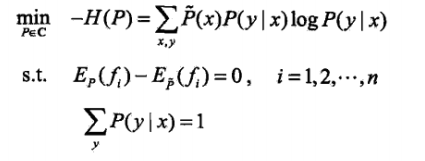
求解约束最优化问题:
构建拉格朗日函数:
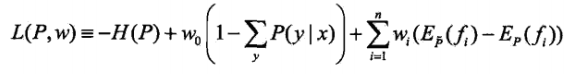
即:
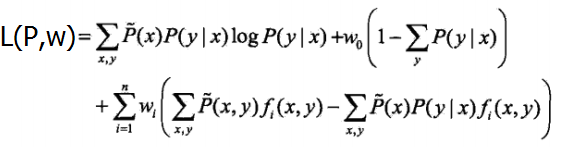
从而,得到原始问题的等价形式 :
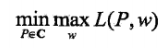
继而,得到原始问题的对偶问题 :
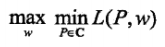
由于这里的Lagrange函数是凸函数,所以原问题和对偶问题的最优解相同,接下来只需要求解对偶问题的最优解就可以:
先求内部的最小化问题 :

目标函数对p(y|x)求梯度 :
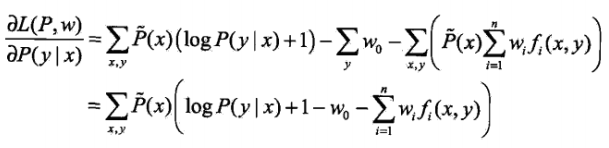
并令梯度为0,可以求得最优的p(y|x)。它是w的函数

将该最优解代回到对偶问题,再求最外的关于ww的最大化问题 :
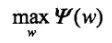
求解得到最优的w∗:
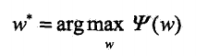
最后,Pw∗可求,也就是最优的: