初入语法分析.
语法分析是编译原理的核心部分,这一点从语法分析在编译原理教科书中所占的篇幅可见一斑,不论是陈火旺老师的《编译原理》还是Ullman等人的“龙书”。语法分析的任务是在词法分析识别出单词符号串的基础上分析并判定程序的语法结构是否符合语法规则。例如词法分析识别出a是一个合法的变量名,那么语法分析目的就是判定a=a+5这样的句子是否合法。
语言的语法结构是用CFL上下文无关语言描述的,所以语法分析器的本质就是根据文法的产生式来识别输入的符号串是否为一个句子。这里的输入串是一个由单词符号(文法的终结符V
)组成的有限序列。也就是判断,从给定文法的开始符号出发,能否利用产生式规则推导出这个输入串。
语法分析按照语法分析树的建立方法可以分为自上而下分析与自下而上分析两种。自上而下分析顾名思义也就是从文法的开始符号出发,向下推导,推出句子。它的主旨是,想尽一切办法,从开始符号出发,为输入串建立一棵语法树,或者专业地说,找到一个最左推导过程。这样的分析过程是一种试探的过程,是反复使用不同产生式来谋求匹配的过程。显然,如果我们能够构造出一种分析方法,它排除了试探、排除了匹配错误的回溯,对于扫描的输入符号,它能够很准确地选择一个产生式来进行推导,那么这样的语法分析器将会是极为高效的(后面我们看到,高效是有代价的).
而LL(1)分析法就是一种自上而下无回溯的分析方法,它能够分析给定的LL(1)文法。这里的LL(1)文法中第一个L代表的是从左到右扫描输入串,第二个L代表的是最左推导,1代表分析时每一步只需要向前看一个输入符号。在详细介绍LL(1)文法之前,我们先看看自上而下分析中,什么样的情况下会出现回溯的需要。
最后三个条件.
- 首先,自上而下分析的文法中,不能含有左递归。试想一下,如果含有左递归的一个文法,它在使用到这个左递归产生式的时候,就会永远地陷入递归之中,永远无法推出一个终结符。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

- 我们要想构造一个没有回溯的自上而下分析程序,那么同一个非终结符A的不同候选式中,不能出现第一个字符相同的情况。例如:
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

对于非终结符N而言,如果现在扫描到了输入字符w,我是使用4号产生式还是5号产生式来匹配它呢,这里就出现了回溯的可能性。可能在某一次匹配中,恰巧选择对了产生式进行匹配,但你不能认定回溯不可能出现。只要存在回溯的可能性,就是分析性能的“反向俯冲”。
对于这一条我们引入一个概念叫做首符集First,它包含的是那些能够作为非终结符A推出的句子中第一个出现的终结符,稍后随着随符集Follow的具体描述一起给出。那么第二条规则可以描述为:对于拥有多条候选产生式的非终结符A而言,各个候选式的First集合没有交集,这一条保证A在面临输入时能够唯一地选择一个产生式 - 对于那些能够产生空并且不仅仅产生空的非终结符而言,它的首符集First和它的随符集Follow不能有交集。我们记A推出的一个句子为sentence,那么非终结符A的Follow集包含的是那些第一个出现sentence后面的终结符。试想,如果不满足这一条,那么A可能在面临一个输入符号时,就无法判定自己是应该推出空,还是应该推出一个非空候选式。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

至此我们提出了构造无回溯自上而下分析程序的三个条件,而实际上,这三个条件并不是独立的,其中一个可以用另外两个推出。
First与Follow.
First和Follow可以说是无回溯自上而下分析的精髓所在。前面我们提到过A的首符集First,包含的是那些能够作为非终结符A推出的句子中第一个出现的终结符;非终结符A的Follow集包含的是那些第一个出现sentence后面的终结符(sentence是A推出的一个句子).下面我们给出这两个集合的具体构造法。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】
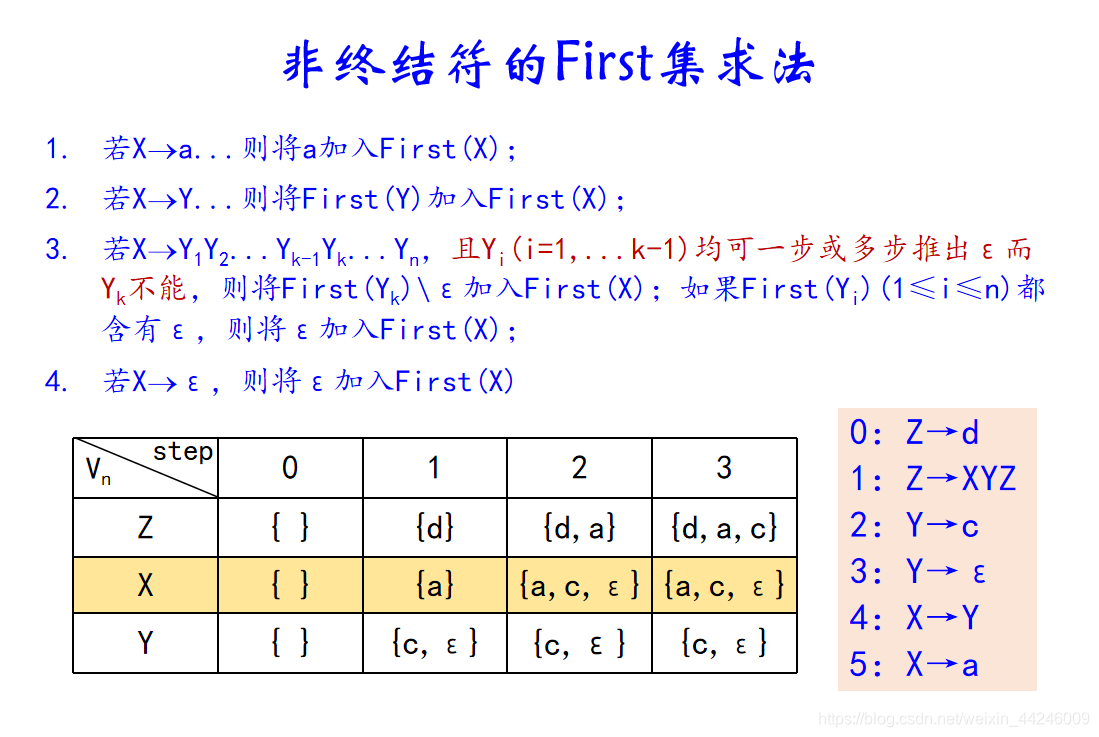

注意有的时候我们可能需要对一个串求它的首符集First,其实这类似于求非终结符的首符集。可以认为求解非终结符的首符集是求解串首符集的特殊情况(串只有一个符号)。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

条件独立性证明.
前面我们提到过,无回溯自上而下分析需要满足三个条件,而满足这三个条件的文法就叫做LL(1)文法,所以我们最开始说LL(1)分析方法是一种无回溯的自上而下分析方法。而LL(1)文法所要求的三个条件我们也说了并不是互相独立的,有一个条件可以由另外两个推导出。下面我们给出证明:

文法改写.
有一些文法,它们的形式中明显地存在左递归形式,或者同一个非终结符的候选式之间有着左公因子。这些文法我们通过文法改写的方法,是有可能将他们变为符合条件的LL(1)文法的,但也存在一部分文法,它们内在性质决定了它们不可能是LL(1)文法,即使改写了。
1. 消除左递归.
对于存在左递归形式的文法,我们有下述公式来消除它的直接左递归。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】 这一转变的思想是将递归拓展的部分从左边转移到右边,和我们之前提到过的右线性RL、左线性RL之间的转换类似。通过一个具体的消除左递归例子来看:
这一转变的思想是将递归拓展的部分从左边转移到右边,和我们之前提到过的右线性RL、左线性RL之间的转换类似。通过一个具体的消除左递归例子来看:
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】
递归拓展的部分是"+T",所以我们用E’来代替+T。但文法还是需要拥有递归推导的那一部分,我们将这一部分放在E’的产生式中,从而避免了出现在非终结符E的左递归。最后由于整个文法需要停止推导,所以E’的产生式中加入空。
关于消除左递归更加详细和复杂的例子,可以看【编译原理】文法左递归的消除。
2.提取左公因子.
提取左公因子的过程类似数学算术运算中提取公因式的概念,例如a*b+a*c可以改写为a*(b+c),严格的数学公式是这样描述的:
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】
LL(1)分析的完整过程.
介绍完了LL(1)分析的要求、细节过程的实现之后,我们以一个文法为例,详细地展示一下整个LL(1)分析流程。我们给定文法如下:
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

1.消除左递归.
利用上面给出的公式,我们给出消除左递归之后的文法:
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

2.提取左公因子.
这里并没有左公因子给我们提取,所以这一步没有发生任何修改。
3.构造预测分析表.
预测分析表是我们得以进行LL(1)语法分析的关键,这张分析表实际上是一台下推自动机(PDA)。关于PDA,我们可以简单的认为它就是一台DFA加上一个堆栈。关于PDA的具体描述如下:
下推自动机(PDA)是自动机理论中定义的一种抽象的计算模型。下推自动机比有限状态自动机复杂:除了有限状态组成部分外,还包括一个长度不受限制的栈;下推自动机的状态迁移不但要参考有限状态部分,也要参照栈当前的状态;状态迁移不但包括有限状态的变迁,还包括一个栈的出栈或入栈过程。
下推自动机在数学上是一个七元组,感兴趣的可以参考蒋宗礼老师的《形式语言与自动机》。
预测分析表的构造是根据LL(1)文法来的,正是LL(1)文法的内在性质,确保了这张预测分析表只有在分析过程中不会出现匹配的冲突。
【下图引用自中南大学徐德智老师的编译原理2020年授课PPT】

建议在执行构造过程之前,求出First和Follow表,该文法的表示如下:
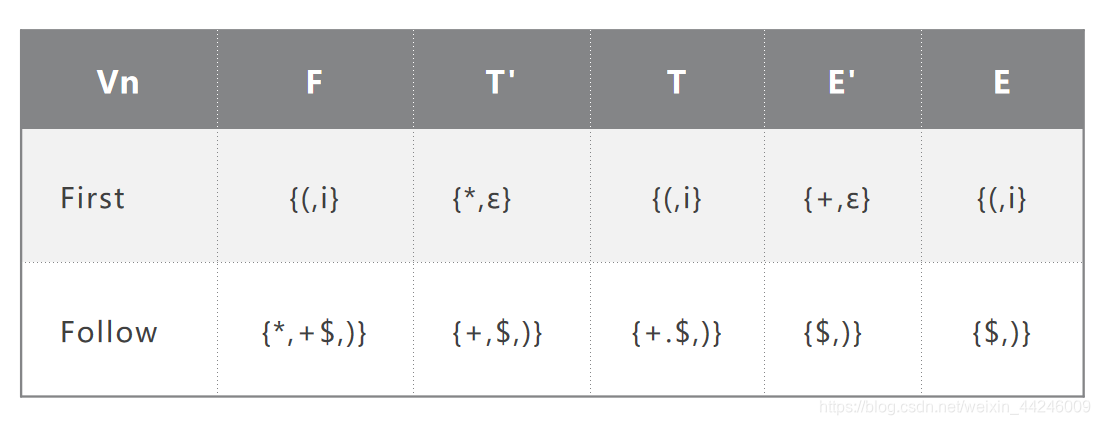
然后我们开始构造预测分析表:
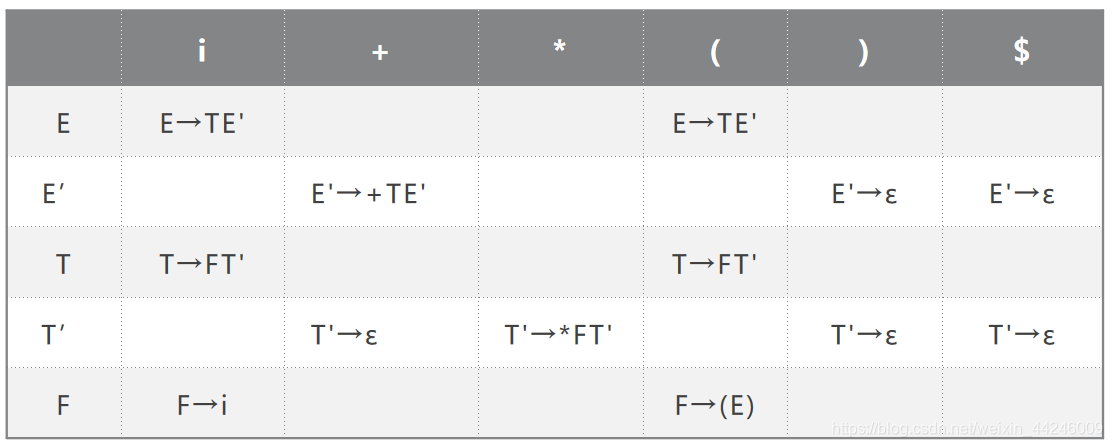
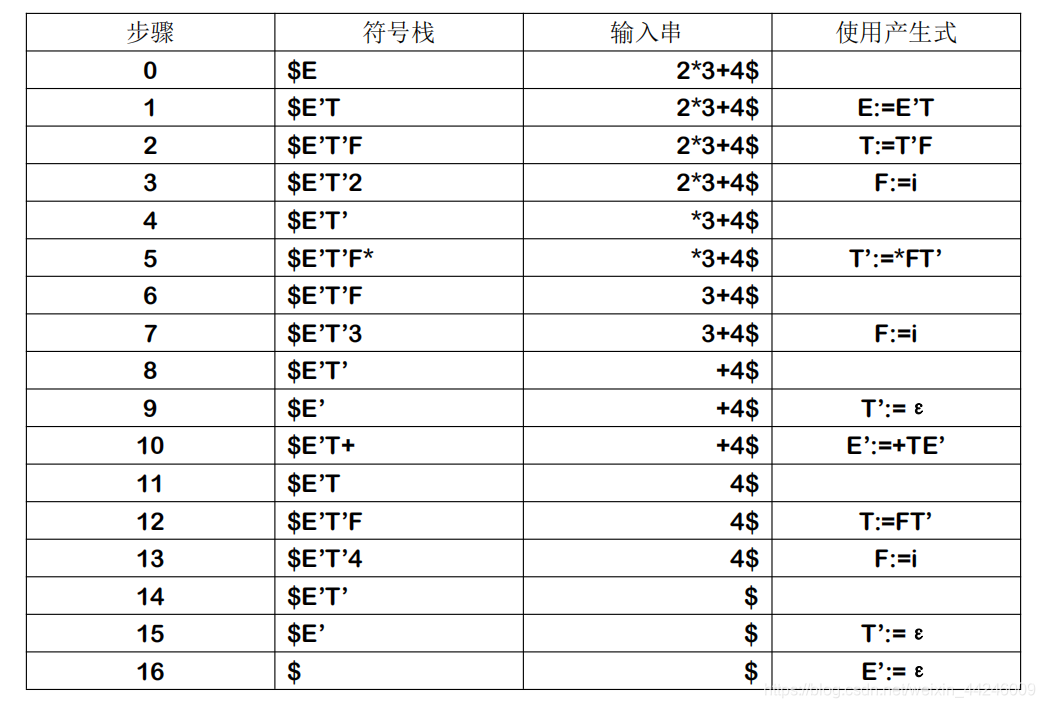
至此实际分析所需要的预测分析表已经完成,最后一步我们使用一个该文法的输入串实例来说明识别的过程。
4.识别过程.
我们考虑输入串2*3+4,其中数字对应于文法中的i.