LL(1)文法的理解
第一个L表明自顶向下分析是从左向右扫描输入串,
第2个L表明分析过程中将使用最左推导,
1表明只需向右看一个符号便可决定如何推导,
即选择哪个产生式(规则)进行推导
【实验原理】
1.LL(1)分析法的功能
LL(1)分析法的功能是利用 LL(1)控制程序根据显示栈栈顶内容、向前
看符号以及 LL(1)分析表,对输入符号串自上而下的分析过程。
2.LL(1)分析法的前提
改造文法:消除二义性、消除左递归、提取左因子,判断是否为 LL(1)文
法,
3.LL(1)分析法实验设计思想及算法
【代码理解】
为了便于理解,先指出该实验代码的基本思想:
强烈建议先把下面的1,2,3的情况先看懂,就能理解代码的执行顺序,再去看代码的时候理解的就会快一点
总的来说, 是根据输入串的当前输入符号(即变量a)来唯一确定选用哪个产生式来进行推导 :这里是我的运行结果
注意:输入要分析的字符串的时候,只能对由i + * ( )
以#结束的字符串
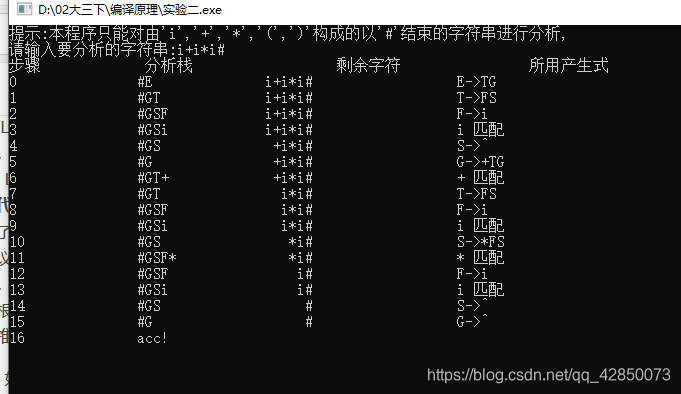
1、如果栈顶符号 X = a = # 则分析成功并停机
2、如 果 X != a,查询分析表M[X,a] , 如果 M[X,a] = {X --> UVW},则用UVW (U在栈顶) 替换栈顶符号 X。
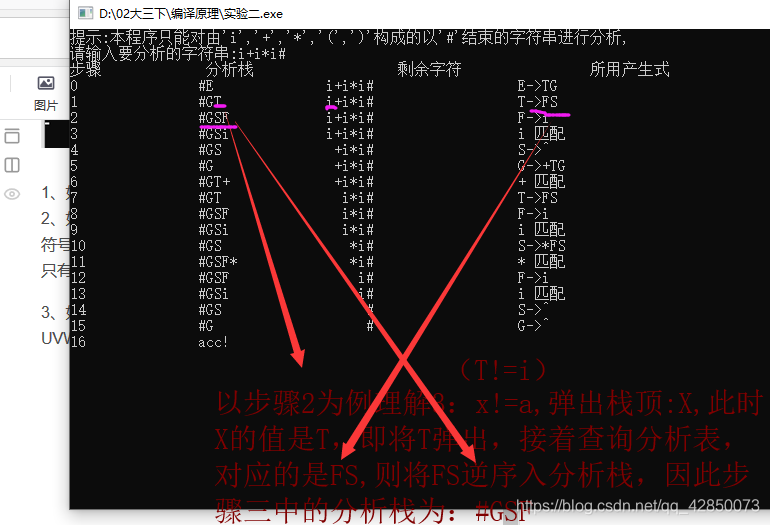 3、如果 X = a != # 则弹出栈顶符号X, 并将输入指针移到下一个符号上,只有在第2种产生式匹配条件下才将指向剩余字符串的指针移动到下一个字符!!!!
3、如果 X = a != # 则弹出栈顶符号X, 并将输入指针移到下一个符号上,只有在第2种产生式匹配条件下才将指向剩余字符串的指针移动到下一个字符!!!!
(希望我画的这图能帮助看懂执行的操作)[
](https://img-blog.csdnimg.cn/20200607121817481.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQyODUwMDcz,size_16,color_FFFFFF,t_70)
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<dos.h>
//注释尽可能的详细了,如果看不懂代码,可以看看后面注释
char A[20];/*分析栈*/
char B[20];/*剩余串 在分析过程中B 是没有变的*/
char v1[20]={
'i','+','*','(',')','#'};/*终结符 */
char v2[20]={
'E','G','T','S','F'};/*非终结符 */
int j=0,b=0,top=0,l;
/*L 为输入串长度
j:v1终结符 v2非终结符
b:记录已经匹配的字符的个数,把分析过的字符用空格代替
top:栈顶 */
typedef struct type/*产生式类型定义 */
{
char origin;/*大写字符 */
char array[5];/*产生式右边字符 */
int length;/*字符个数 */
}type;
type e,t,g,g1,s,s1,f,f1;/*结构体变量 */
type C[10][10];/*预测分析表 */
void print()/*输出分析栈 */
{
int a;/*指针*/
for(a=0;a<=top+1;a++)
printf("%c",A[a]);
printf("\t\t");
}/*print*/
void print1()/*输出剩余串*/
{
int j;
for(j=0;j<b;j++)/*输出对齐符*//*b:记录已经匹配的字符的个数,把分析过的字符用空格代替 */
printf(" ");
for(j=b;j<=l;j++)
printf("%c",B[j]);
printf("\t\t\t");
}/*print1*/
int main(){
int m,n,k=0,flag=0,finish=0;
char ch,x; //ch:输入串栈顶,x为当前栈顶字符 ,
type cha; //存放分析表中的坐标 ,记录应用的产生式
//产生式的左部以及产生式的右部分
e.origin='E';
strcpy(e.array,"TG");
e.length=2; //更改length赋值
t.origin='T';
strcpy(t.array,"FS");
t.length=2;
g.origin='G';
strcpy(g.array,"+TG");
g.length=3;
g1.origin='G';
g1.array[0]='^';
g1.length=1;
s.origin='S';
strcpy(s.array,"*FS");
s.length=3;
s1.origin='S';
s1.array[0]='^';
s1.length=1;
f.origin='F';
strcpy(f.array,"(E)");
f.length=3;
f1.origin='F';
f1.array[0]='i';
f1.length=1;
//分析法
for(m=0;m<=4;m++)/*初始化分析表*/
for(n=0;n<=5;n++)
C[m][n].origin='N';/**/
/*填充分析表*/
C[0][0]=e;
C[0][3]=e;
C[1][1]=g;
C[1][4]=g1;
C[1][5]=g1;
C[2][0]=t;
C[2][3]=t;
C[3][1]=s1;
C[3][2]=s;
C[3][4]=C[3][5]=s1;
C[4][0]=f1;
C[4][3]=f;
printf("提示:本程序只能对由'i','+','*','(',')'构成的以'#'结束的字符串进行分析,\n");
printf("请输入要分析的字符串:");
do/*读入分析串*/
{
scanf("%c",&ch);
if ((ch!='i') &&(ch!='+') &&(ch!='*')&&(ch!='(')&&(ch!=')')&&(ch!='#')){
printf("输入串中有非法字符\n");
exit(1);
}
B[j]=ch;//保存输入串
j++;//输入串长度
}
while(ch!='#');
l=j;/*分析串长度*/
ch=B[0];/*当前分析字符*/
//最开始在栈里压入 # 和 开始符号 E
A[top]='#';
A[++top]='E';/*'#','E'进栈*/
printf("步骤\t\t 分析栈 \t\t 剩余字符 \t\t 所用产生式 \n");
//推导过程如下
do{
x=A[top--];/*x 为当前栈顶字符*/
printf("%d",k++); /步骤序号 一个do while为一次k++
printf("\t\t");
for(j=0;j<=5;j++)/*判断栈顶元素是否为终结符*/
if(x==v1[j]){
flag=1;
break;
}
if(flag==1)/*如果是终结符*/
{
if(x=='#'){
finish=1;/*结束标记*/
printf("acc!\n");/*接受 */
getchar();
getchar();
exit(1);
}/*if*/
if(x==ch){
/*是否为分析串*/
print();
print1();
printf("%c 匹配\n",ch);
ch=B[++b];/*下一个输入字符*/
flag=0;/*恢复标记*/
}/*if*/
/*不匹配*/
else/*出错处理*/
{
print(); //更改 最后成功时对齐
print1();
printf("%c 出错\n",ch);/*输出出错终结符*/
exit(1);
}/*else*/
}/*if*/
else/*非终结符处理*/{
for(j=0;j<=4;j++)
if(x==v2[j]){
m=j;/*行号*/
break;
}//行号是根据栈顶元素判断出来的
for(j=0;j<=5;j++)
if(ch==v1[j]){
/*入如果分析穿等于终结符数组某列*/
n=j;/*列号*/
break;
}
cha=C[m][n]; //记录应用的产生式
if(cha.origin!='N')/*判断是否为空*/
{
print();
print1();
printf("%c->",cha.origin);/*输出产生式*/
for(j=0;j<cha.length;j++)/*便利,输出产生式的那一列*/
printf("%c",cha.array[j]);
printf("\n");
///逆序入栈
///*产生式逆序入栈*/
for(j=(cha.length-1);j>=0;j--){
A[++top]=cha.array[j];
if(A[top]=='^')/*为空则不进栈*/
top--;
}
}/*if*/
else/*出错处理*/{
print();
print1();
printf("%c 出错\n",x);/*输出出错非终结符*/
exit(1);
}/*else*/
}/*else*/
}
while(finish==0);
}/*main*/