HashMap 实现原理解析
网上有很多关于HashMap分析的文章, 但在此我会根据自己的理解, 对比JDK1.7 HashMap源码来解释HashMap原理.
首先要了解一个知识点: n(max) & m(min) 一定小于等于 m(min)

为什么这么说呢? 看上图, 两个数由高位依次对比, 相同则对比下一位, 直到某一位不同时, 该位为0 的数是 min, 为 1 的数是 max, 而0 & 1 总为 0 , 所以min & max <= min
言归正传, HashMap 存取主要是通过 put get 两个方法, 先来看下get方法的实现:
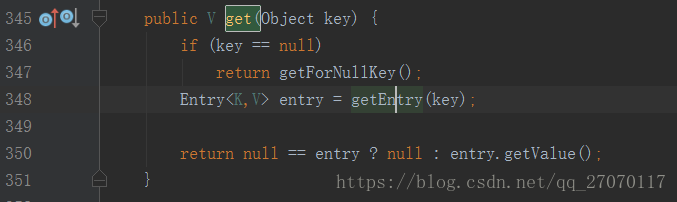
(347行 当key为 null时 调用getForNullKey() 获取value值, getForNullKey实现首先判断HashMap 的size为0则返回 null, 否则查找HashMap中是否有key 为null的元素并返回, 与HashMap原理关联不大, 不过多赘述)
第348行, getEntry()方法是根据key查找value的主要实现逻辑, 来看下该方法实现:
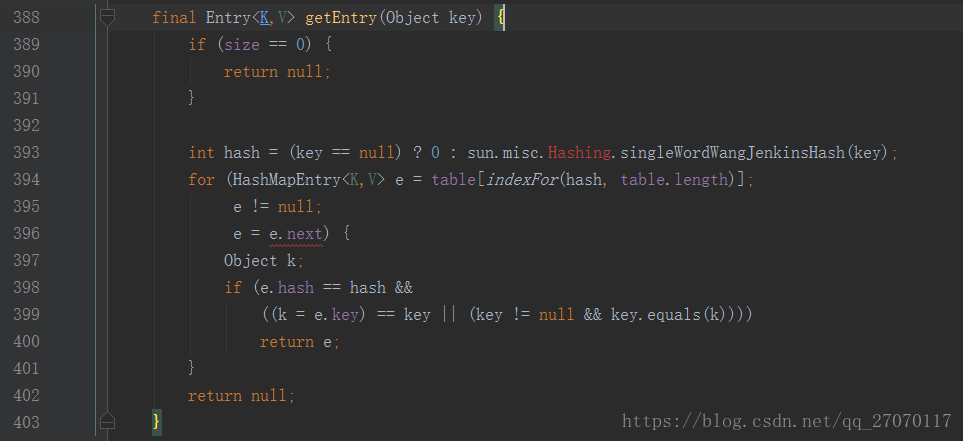
getEntry 实现逻辑中, 首先第393行获取了key的hash值, 首先了解下该hash 的特点: 同一对象获取到该值永远相同, 不同对象间hash值极难重复, 至于怎么获取的此处没有源码不再过多解释, 个人推测应该跟Object 类种的 hashCode方法类似.
然后 394行调用了indexFor()方法, 来看下该方法实现:

indexFor实现很简单, 即将 hash & (length - 1), 回顾下一开始说的 & 运算的特性, 即结果永远小于等于两数中最小值, 一般来说 hash值都是比较大的, 即indexFor计算结果永远在 0 到 length - 1之间, 并且结果具体是什么值由hash的低位决定. indexFor方法可以这么理解, 相当于取了0 到 length - 1之间的一个随机数, 但这个随机数有一个特点, 即相同hash值取出的随机数相同
这样以来HashMap的基本原理就能解释清楚了, put方法根据key的hash通过indexFor方法将键值对存到该位置, get方法根据key的hash通过indexFor方法找到该位置元素并取出来, 以此实现HashMap的存取, 但是, 现在引出了另一个问题, 即对象的hash值极难重复但有可能重复, 相同key的hash值一定相同, 但hash相同key不一定相同, 即通过indexFor计算出的角标可能是多个元素. 我们回头看下代码片段 getEntry 第394行, 注意该行是一个for循环, 起点是indexFor 角标处的元素, 而循环遍历的是e.next(该处元素next属性), 由此可见indexFor处元素及其 next属性hash值都是相同的, 而此处for循环主要是判断key是否相同, key相同则是同一元素, 由此推测put时如果不同key hash值相同则将新元素至于indexFor计算出的角标位置, 旧元素置于新元素的next属性上, 这样就解决了hash值重复问题.
由于Hash值极难重复, 所以Entry 的 next属性上串起来的元素不会太多, 而计算 hash值与 hash&length-1 耗时要比遍历数组所有元素更少, 所以HashMap查找效率非常高.
注意刚才所说的Hash值极难重复, 如下图,两个不同的key有两个及其相似的hash值, (图片中的length应该是length - 1), 整体不同但低位相同, 两个hash与 length - 1 执行 & 运算, 由于length - 1较小所以不同hash的key通过indexFor计算出的标是相同的, 即之前所说由于Hash值极难重复其实是错误的, 应该是由于Hash值低位难以重复. 而hash值重复的难易程度由 length 的二进制位数决定, 即元素越多, hash低位越难以重复, HashMap取元素的优势越明显.
这就是为什么JDK1.8更改了indexFor的逻辑, JDK1.8将hash&(length-1)更改为(hash^hash>>>16)&(length-1) , hash右移16位并^ hash保证高位参与运算, 这样再与 lenght - 1进行&运算即使不同key hash值低位相同, 得到的值也会由于高位不同而不同. 这样就大大减少了同一角标串在next属性上的元素数量.

接下来是最后一个问题, HashMap内部的 table数组总会装满, 装满了就要扩容, 一旦扩容 table.length就会改变, 那么通过indexFor计算出的角标就会不准确, 即扩容时需要遍历旧的数组中所有元素, 重新计算位置, 并将其置于新的数组中来看下扩容部分的源码:
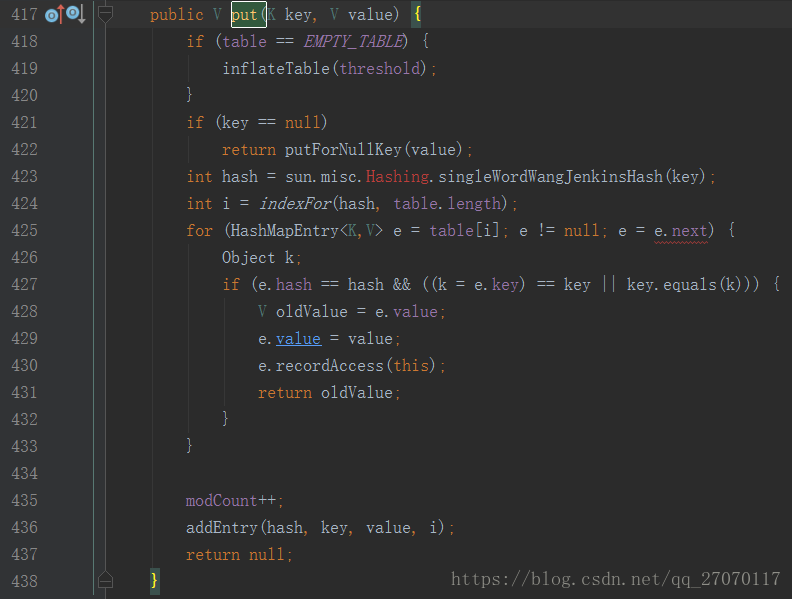
在 put方法中第437行调用addEntry添加数据.
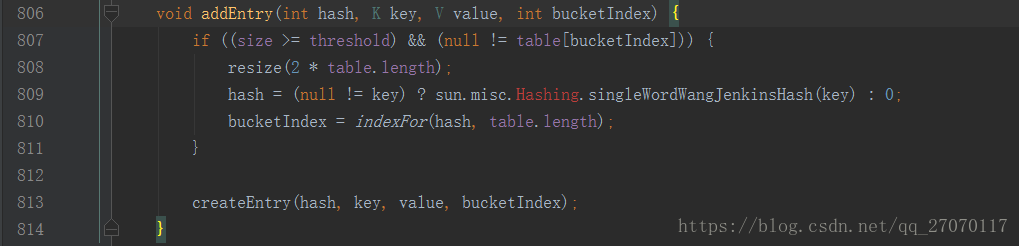
在 addEntry 807行判断元素个数到达临界值的话, 调用resize扩容为原来数组大小的两倍
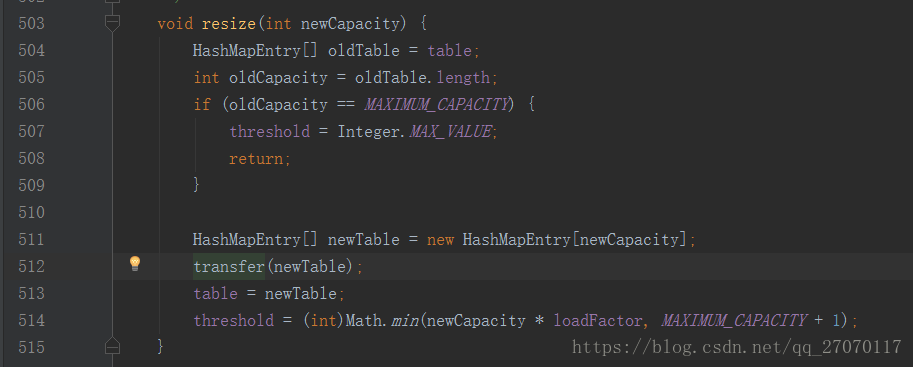
然后resize 方法中创建了新的指定容量的数组, 并调用 transfer(newTable)方法传递了新数组的引用.
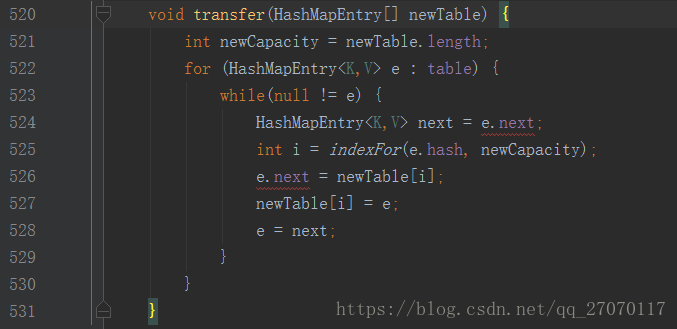
而在 transfer 方法中, for循环遍历原有 table数组, while循环遍历 table数组每一元素及其next属性上串起来的所有元素, 并重新通过indexFor计算其角标. 这就是为什么HashMap是线程不安全的, 假设A线程put元素时进行扩容, 在扩容完成前B线程使用旧的table数组通过indexFor计算出角标, 此时A线程扩容完毕, 新数组替换旧数组, B线程使用之前计算出的角标在新数组根据hash值和key值寻找目标元素, 所以得到的结果会是null(回头看下getEntry方法) .
以上就是我对HashMap的理解, 如有哪里理解得不对希望能联系我我会进行修正.