一、HashMap数据结构
JDK1.7的时候使用的是数组+ 单链表的数据结构。
JDK1.8及之后,使用的是数组+链表+红黑树的数据结构(当链表的深度达到8且table.length >=64 就会自动扩容把链表转成红黑树的数据结构,把时间复杂度从O(n)变成O(logN)提高了效率)
- 当链表长度为8 和数组大小大于64的时候 会将链表转化为红黑树 。 若是阈值大于8 但是数组长度小于64(没经过两次扩容) ,此时会扩容,而不会将链表转化为红黑树。
- 当链表长度为6的时候,会将红黑树转化为链表
原因:
因为链表过小时,使用红黑树性能还没有使用链表来的高。
2、有三种情况触发扩容机制
阈值 = table.length * load_factor(0.75)为主要扩容依据,默认16 * 0.75 = 12(判断链表长度),下面总结基于JDK1.8。
-
1、在数组上某一下标的数组这里记为table[a]的链表长度bucket.len = 7,再插入一个map时,发送hash碰撞且hash(key) = a,即这时会将元素插入链表中bucket.len = 8,链表长度等于8时很多人就会想到是不是要变红黑树。但是不是这样的,需要先判断table.length:
若table.length >=64 ,则直接转化为红黑树;
若是table.length < 64,则会触发扩容机制。
即在初始状态下bucket.len == 8,9的情况下可能都不会转化红黑树,而是直接扩容。在table.length >= 64 情况下,只要bucket.len达到8,链表直接转化为红黑树。 -
2、当元素个数(hashmap.size()) > table.length*load_factor(阈值)会触发扩容机制。为什么要大于呢?因为JDK8是先插入后扩容。
-
3、HashMap为空,初始化的时候也会触发扩容机制进行HashMap初始化。
3、注意点
-
JDK1.7之前先扩容在插入
-
JDK1.8先插入后扩容
总结网上说的
jdk7 数组+单链表 jdk8 数组+(单链表+红黑树)
jdk7 链表头插 jdk8 链表尾插
头插: resize后transfer数据时不需要遍历链表到尾部再插入
头插: 最近put的可能等下就被get,头插遍历到链表头就匹配到了
头插: resize后链表可能倒序; 并发resize可能产生循环链
jdk7 先扩容再put jdk8 先put再扩容 (why?有什么区别吗?)
jdk7 计算hash运算多 jdk8 计算hash运算少
jdk7 受rehash影响 jdk8 调整后是(原位置)or(原位置+旧容量)
收藏网址(非转载):http://www.jasongj.com/java/concurrenthashmap -
HashMap源码上链表长度大于8-1=7时就转化为红黑树。
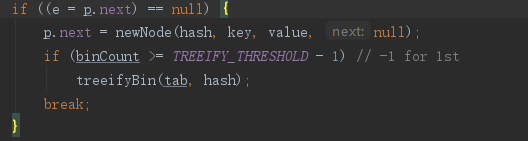

-
这是链表树化的方法 这里指明了 tab.length也就是table.length < 64时,需要先扩容而不是树化。


